
Debezium is a CDC tool that can stream changes from MySQL, MongoDB, and PostgreSQL into Kafka, using Kafka Connect. In this article we’ll see how to set it up and examine the format of the data. A subsequent article will show using this realtime stream of data from a RDBMS and join it to data originating from other sources, using KSQL.
The software versions used here are:
- Confluent Platform 4.0
- Debezium 0.7.2
- MySQL 5.7.19 with Sakila sample database installed
Install Debezium 🔗
To use it, you need the relevant JAR for the source system (e.g. MySQL), and make that JAR available to Kafka Connect. Here we’ll set it up for MySQL.
Download debezium-connector-mysql-0.7.2-plugin.tar.gz jar from https://repo1.maven.org/maven2/io/debezium/debezium-connector-mysql/
Unpack the .tar.gz into its own folder, for example /u01/plugins so that you have:
/u01/plugins/debezium-connector-mysql/mysql-binlog-connector-java-0.13.0.jar
/u01/plugins/debezium-connector-mysql/debezium-core-0.7.2.jar
/u01/plugins/debezium-connector-mysql/mysql-binlog-connector-java-0.13.0.jar
/u01/plugins/debezium-connector-mysql/mysql-connector-java-5.1.40.jar
/u01/plugins/debezium-connector-mysql/debezium-connector-mysql-0.7.2.jar
Now configure Kafka Connect to pick up the Debezium plugin, by updating the Kafka Connect worker config.
Edit ./etc/kafka/connect-distributed.properties and append to plugin.path the value for the folder containing the Debezium JAR. For example:
plugin.path=share/java,/u01/plugins/
plugin.path is based on this expected structure: 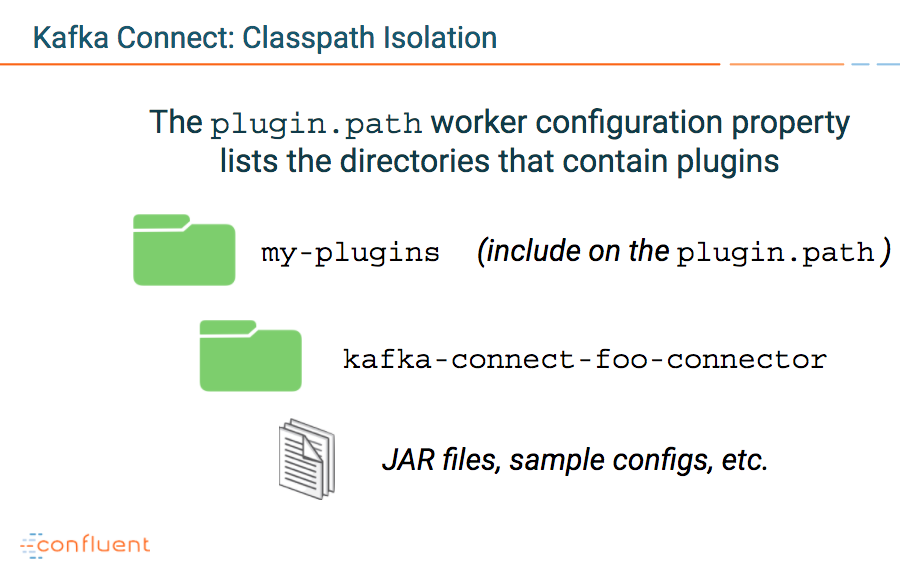
MySQL config 🔗
Debezium uses MySQL’s binlog facility to extract events, and you need to configure MySQL to enable it. Here is the bare-basics necessary to get this working - fine for demo purposes, but not a substitute for an actual MySQL DBA doing this properly :)
Check current state of binlog replication:
$ mysqladmin variables -uroot|grep log_bin
| log_bin | OFF
[...]
Enable binlog per the doc. On the Mac I’d installed MySQL with homebrew, and enabled binlog by creating the following file at /usr/local/opt/mysql/my.cnf
[mysqld]
server-id = 42
log_bin = mysql-bin
binlog_format = row
binlog_row_image = full
expire_logs_days = 10
I restarted mysqld with:
brew services restart mysql
and verified that binlog was now enabled:
$ mysqladmin variables -uroot|grep log_bin
| log_bin | ON
[...]
Create user with required permissions;
$ mysql -uroot
mysql> GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'debezium' IDENTIFIED BY 'dbz';
Kafka Connect setup 🔗
Load the connector configuration into Kafka Connect using the REST API:
curl -i -X POST -H "Accept:application/json" \
-H "Content-Type:application/json" http://localhost:8083/connectors/ \
-d '{
"name": "mysql-connector",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"database.hostname": "localhost",
"database.port": "3306",
"database.user": "debezium",
"database.password": "dbz",
"database.server.id": "42",
"database.server.name": "demo",
"database.history.kafka.bootstrap.servers": "localhost:9092",
"database.history.kafka.topic": "dbhistory.demo" ,
"include.schema.changes": "true"
}
}'
Now check that the connector is running successfully:
curl -s "http://localhost:8083/connectors" | jq '.[]' | \
xargs -I{connector_name} curl -s "http://localhost:8083/connectors/"{connector_name}"/status" | \
jq -c -M '[.name,.connector.state,.tasks[].state] | \
join(":|:")'| column -s : -t| sed 's/\"//g'| sort
mysql-connector | RUNNING | RUNNING
If it’s FAILED then check the Connect Worker log for errors - often this will be down to mistakes with the plugin’s JAR path or availability, so check that carefully.
Assuming it’s RUNNING, you should see in the Connect Worker logs something like this, indicating that Debezium has successfully pulled data from MySQL:
[2018-02-09 15:27:40,268] INFO Starting snapshot for jdbc:mysql://localhost:3306/?useInformationSchema=true&nullCatalogMeansCurrent=false&useSSL=false&useUnicode=true&characterEncoding=UTF-8&characterSetResults=UTF-8&zeroDateTimeBehavior=convertToNull with user 'debezium' (io.debezium.connector.mysql.SnapshotReader:220)
[...]
[2018-02-09 15:27:57,297] INFO Step 8: scanned 97354 rows in 24 tables in 00:00:15.617 (io.debezium.connector.mysql.SnapshotReader:579)
[2018-02-09 15:27:57,297] INFO Step 9: committing transaction (io.debezium.connector.mysql.SnapshotReader:611)
[2018-02-09 15:27:57,299] INFO Completed snapshot in 00:00:17.032 (io.debezium.connector.mysql.SnapshotReader:661)
Inspect the MySQL data in Kafka 🔗
Use kafka-topics to see all the topics created by Debezium:
kafka-topics --zookeeper localhost:2181 --list
Each table in the database becomes one topic in Kafka. You’ll see that the topic name is in the format of database.schema.table:
fullfillment.sakila.actor
fullfillment.sakila.address
fullfillment.sakila.category
[...]
Now let’s look at the messages. Each table row becomes a message on a kafka topic.
Run the Avro Console consumer: (using the excellent jq for easy formatting of the JSON)
./bin/kafka-avro-console-consumer \
--bootstrap-server localhost:9092 \
--property schema.registry.url=http://localhost:8081 \
--topic fullfillment.sakila.customer \
--from-beginning | jq '.'
This will show the current contents of the topic. Leave the above command running, and in a separate window make a change to the table in MySQL, for example, an update:
mysql> UPDATE CUSTOMER SET FIRST_NAME='Rick' WHERE CUSTOMER_ID=603;
In the Kafka consumer you’ll see the change record come through pretty much instantaneously.
The records from Debezium look like this:
{
"before": null,
"after": {
"fullfillment.sakila.rental.Value": {
"rental_id": 13346,
"rental_date": 1124483301000,
"inventory_id": 4541,
"customer_id": 131,
"return_date": {
"long": 1125188901000
},
"staff_id": 2,
"last_update": "2006-02-15T21:30:53Z"
}
},
"source": {
"name": "fullfillment",
"server_id": 0,
"ts_sec": 0,
"gtid": null,
"file": "mysql-bin.000002",
"pos": 832,
"row": 0,
"snapshot": {
"boolean": true
},
"thread": null,
"db": {
"string": "sakila"
},
"table": {
"string": "rental"
}
},
"op": "c",
"ts_ms": {
"long": 1518190060267
}
}
Note the structure of the messages - you get an before and after view of the record, plus a bunch of metadata (source, op, ts_ms). Depending on what you’re using the CDC events for, you’ll want to retain some or all of this structure.
Event Message Flattening with Single Message Transform 🔗
For simply streaming into Kafka the current state of the record, it can be useful to take just the after section of the message. Kafka Connect includes functionality called Single Message Transform (SMT). As the name suggests, it enables you to transform single messages! You can read more about it and examples of its usage here. As well as the Transforms that ship with Apache Kafka, you can write your own using the documented API. This is exactly what the Debezium project have done, shipping their own SMT as part of it, providing an easy way to flatten the events that Debezium emits.
Using SMT you can amend the message inbound/outbound from Kafka to show just the new record:
{
"c1": {
"int": 100
},
"c2": {
"string": "wibble"
},
"create_ts": "2018-01-23T22:47:09Z",
"update_ts": "2018-02-09T15:35:48Z"
}
instead of the full change:
{
"before": {
"fullfillment.demo.foobar.Value": {
"c1": {
"int": 100
},
"c2": {
"string": "bar"
},
"create_ts": "2018-01-23T22:47:09Z",
"update_ts": "2018-01-23T22:47:09Z"
}
},
"after": {
"fullfillment.demo.foobar.Value": {
"c1": {
"int": 100
},
"c2": {
"string": "wibble"
},
"create_ts": "2018-01-23T22:47:09Z",
"update_ts": "2018-02-09T15:35:48Z"
}
},
"source": {
"name": "fullfillment",
"server_id": 42,
"ts_sec": 1518190548,
"gtid": null,
"file": "mysql-bin.000002",
"pos": 1025,
"row": 3,
"snapshot": null,
"thread": {
"long": 11
},
"db": {
"string": "demo"
},
"table": {
"string": "foobar"
}
},
"op": "u",
"ts_ms": {
"long": 1518190548539
}
}
SMT can also be used to modify the target topic (which unmodified is server.database.table), using the RegexRouter transform.
With these two SMT included, this is how our configuration looks now:
{
"name": "mysql-connector-flattened",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"database.hostname": "localhost",
"database.port": "3306",
"database.user": "debezium",
"database.password": "dbz",
"database.server.id": "42",
"database.server.name": "fullfillment",
"database.history.kafka.bootstrap.servers": "localhost:9092",
"database.history.kafka.topic": "dbhistory.fullfillment" ,
"include.schema.changes": "true" ,
"transforms": "unwrap,changetopic",
"transforms.unwrap.type": "io.debezium.transforms.UnwrapFromEnvelope",
"transforms.changetopic.type":"org.apache.kafka.connect.transforms.RegexRouter",
"transforms.changetopic.regex":"(.*)",
"transforms.changetopic.replacement":"$1-smt"
}
}
To see how streaming events from a RDBMS such as MySQL into Kafka can be even more powerful when combined with KSQL for stream processing check out KSQL in Action: Enriching CSV Events with Data from RDBMS into AWS.