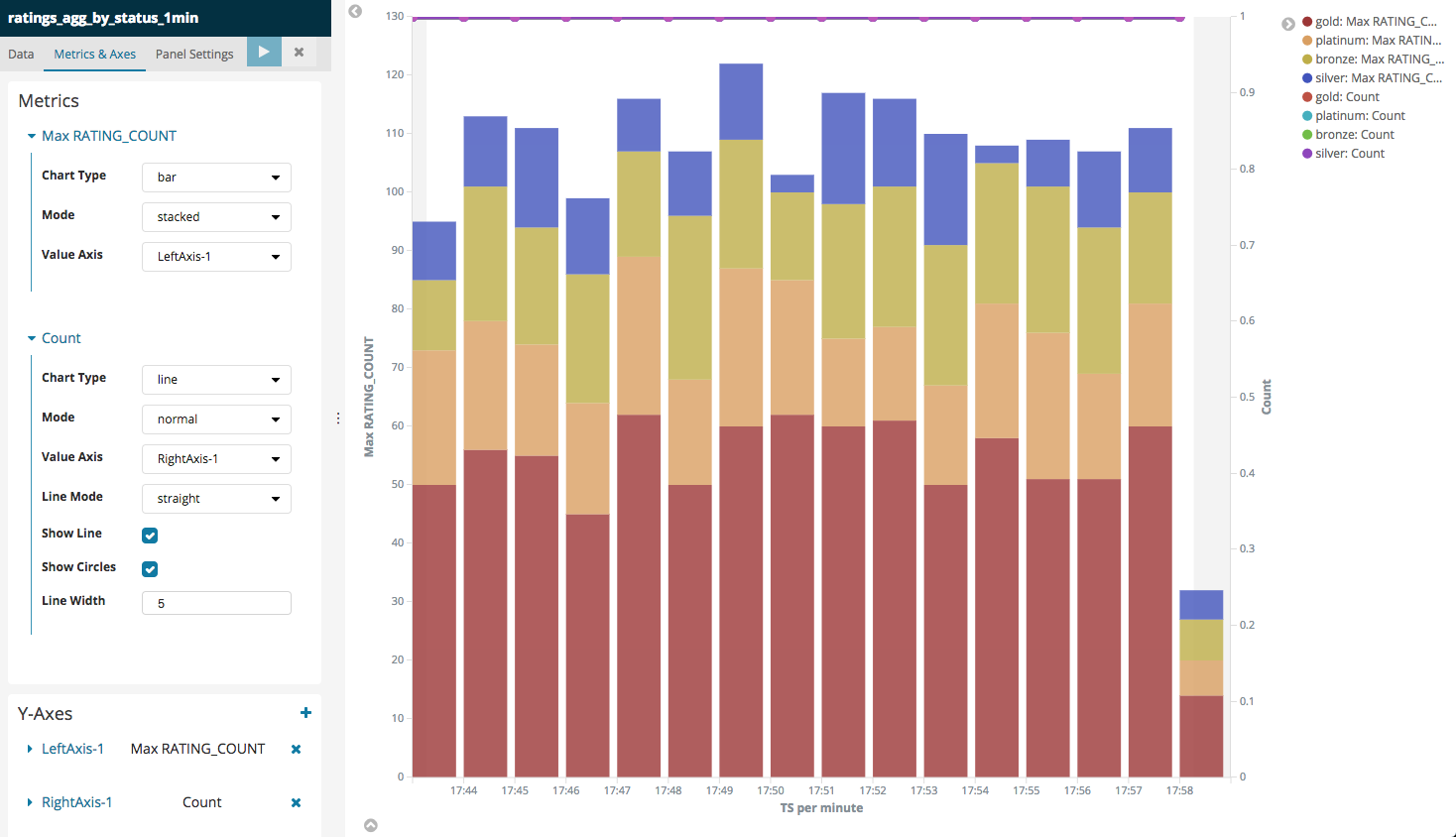
KSQL provides the ability to create windowed aggregations. For example, count the number of messages in a 1 minute window, grouped by a particular column:
CREATE TABLE RATINGS_BY_CLUB_STATUS AS \
SELECT CLUB_STATUS, COUNT(*) AS RATING_COUNT \
FROM RATINGS_WITH_CUSTOMER_DATA \
WINDOW TUMBLING (SIZE 1 MINUTES) \
GROUP BY CLUB_STATUS;
How KSQL, and Kafka Streams, stores the window timestamp associated with an aggregate, has recently changed. See #1497 for details.
Whereas previously the Kafka message timestamp (accessible through the
KSQL ROWTIME system column) stored the start of the window for which
the aggregate had been calculated, this changed in July 2018 to instead
be the timestamp of the latest message to update that aggregate value.
This was in Apache Kafka 2.0 and Confluent Platform 5.0, and back-ported
to previous versions.
ksql> DESCRIBE RATINGS_BY_CLUB_STATUS;
Name : RATINGS_BY_CLUB_STATUS
Field | Type
------------------------------------------
ROWTIME | BIGINT (system)
ROWKEY | VARCHAR(STRING) (system)
CLUB_STATUS | VARCHAR(STRING)
RATING_COUNT | BIGINT
------------------------------------------
For runtime statistics and query details run: DESCRIBE EXTENDED <Stream,Table>;
ksql> SELECT * FROM RATINGS_BY_CLUB_STATUS LIMIT 5;
1535994657217 | platinum : Window{start=1535994600000 end=-} | platinum | 14
1535994718988 | platinum : Window{start=1535994660000 end=-} | platinum | 26
1535994776177 | platinum : Window{start=1535994720000 end=-} | platinum | 23
1535994827952 | platinum : Window{start=1535994780000 end=-} | platinum | 14
1535994658145 | bronze : Window{start=1535994600000 end=-} | bronze | 12
Limit Reached
Query terminated
ksql>
It’s useful to be able to access the start time of a windowed aggregate, particularly for analytical uses. If KSQL is being used to build aggregates for analysis and reporting, the window for which an aggregate is required to give it any context. Otherwise it’s just a number!
An example of using the window timestamp is in streaming KSQL aggregates into Elasticsearch for visualisation:
There are plans to create a function in KSQL that will expose the window start timestamp again.
To get it to work with Elasticsearch, in Kafka Connect use the SMT as before to pull the message timestamp out into a field
"transforms": "ExtractTimestamp",
"transforms.ExtractTimestamp.type": "org.apache.kafka.connect.transforms.InsertField$Value",
"transforms.ExtractTimestamp.timestamp.field" : "TS"
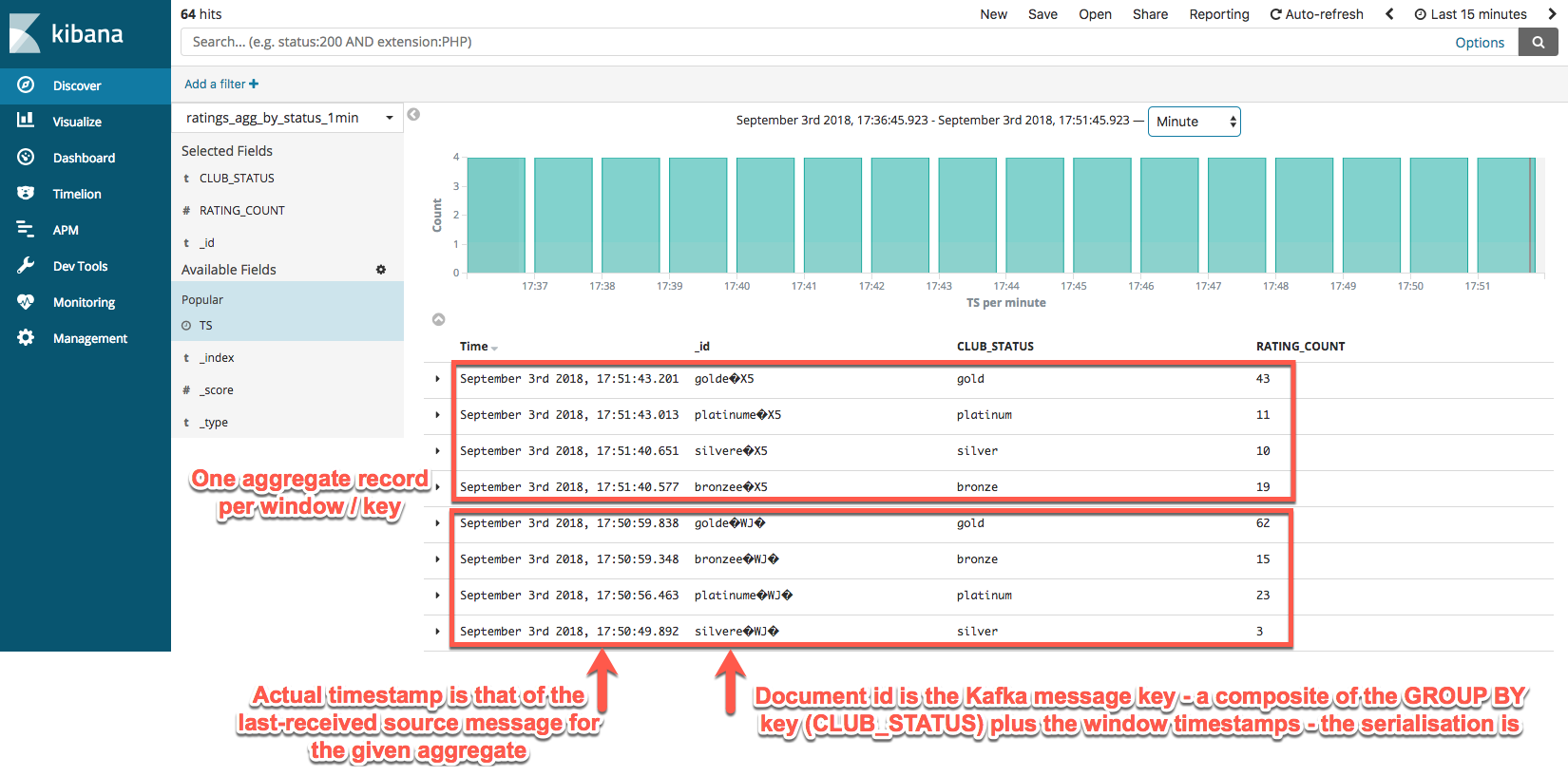
and then make sure you set "key.ignore": "false". This will then make
Kafka Connect use the Kafka message key (which is the grouped-by
field(s) plus the window start + end timestamp) as the Elasticsearch
document id. The effect of this is that you’ll end up with one document
per aggregation in Elasticsearch, updated in place.
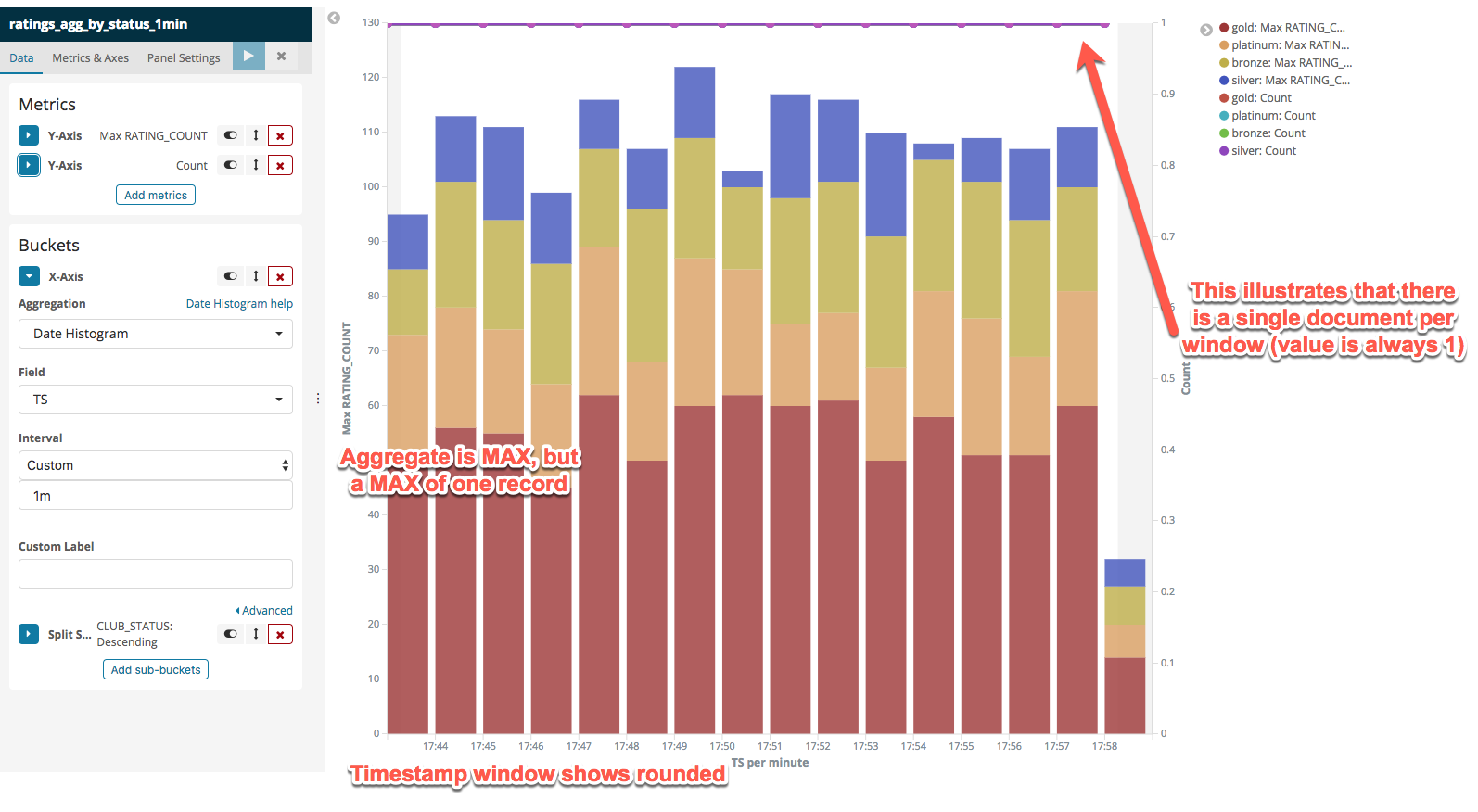
The timestamp value will not be on the beginning of the window but it will be within it - and you can use Kibana’s visualisation which will display it rounded: