
Prompted by a question on StackOverflow, the requirement is to take a series of events related to a common key and for each key output a series of aggregates derived from a changing value in the events. I’ll use the data from the question, based on ticket statuses. Each ticket can go through various stages, and the requirement was to show, per customer, how many tickets are currently at each stage.
Here’s the source data:
| Customer | Ticket ID | Ticket Status |
|---|---|---|
| 2216 | 1472 | closed |
| 8945 | 1472 | waiting |
| 8945 | 1472 | processing |
| 8945 | 1472 | waiting |
| 8952 | 1472 | new |
| 8952 | 1472 | close-request |
By eyeballing the data we can see that for this one customer there are three tickets, in state closed, waiting, close-request and so the desired output is:
| Customer | Tickets closed | Tickets waiting | Tickets processing | Tickets waiting | Tickets new | Tickets close request |
|---|---|---|---|---|---|---|
| 1472 | 1 | 1 | 0 | 0 | 0 | 1 |
In RDBMS SQL this would be a fairly trivial PIVOT operation. In KSQL we can achieve the same using the CASE statement which was added in 5.2. Along the way we also need to reason about state vs event stream.
It’s possible to do this by building a table (for state) and then an aggregate on that table.
-
Set up the test data
kafkacat -b localhost -t tickets -P <<EOF {"ID":2216,"CONTACT_ID":1472,"SUBJECT":"Test Bodenbach","STATUS":"closed","TIMESTRING":"2012-11-08 10:34:30.000"} {"ID":8945,"CONTACT_ID":1472,"SUBJECT":"sync-test","STATUS":"waiting","TIMESTRING":"2019-04-16 23:07:01.000"} {"ID":8945,"CONTACT_ID":1472,"SUBJECT":"sync-test","STATUS":"processing","TIMESTRING":"2019-04-16 23:52:08.000"} {"ID":8945,"CONTACT_ID":1472,"SUBJECT":"sync-test","STATUS":"waiting","TIMESTRING":"2019-04-17 00:10:38.000"} {"ID":8952,"CONTACT_ID":1472,"SUBJECT":"another sync ticket","STATUS":"new","TIMESTRING":"2019-04-17 00:11:23.000"} {"ID":8952,"CONTACT_ID":1472,"SUBJECT":"another sync ticket","STATUS":"close-request","TIMESTRING":"2019-04-17 00:12:04.000"} EOF -
Preview the topic data
ksql> PRINT 'tickets' FROM BEGINNING; Format:JSON {"ROWTIME":1555511270573,"ROWKEY":"null","ID":2216,"CONTACT_ID":1472,"SUBJECT":"Test Bodenbach","STATUS":"closed","TIMESTRING":"2012-11-08 10:34:30.000"} {"ROWTIME":1555511270573,"ROWKEY":"null","ID":8945,"CONTACT_ID":1472,"SUBJECT":"sync-test","STATUS":"waiting","TIMESTRING":"2019-04-16 23:07:01.000"} {"ROWTIME":1555511270573,"ROWKEY":"null","ID":8945,"CONTACT_ID":1472,"SUBJECT":"sync-test","STATUS":"processing","TIMESTRING":"2019-04-16 23:52:08.000"} {"ROWTIME":1555511270573,"ROWKEY":"null","ID":8945,"CONTACT_ID":1472,"SUBJECT":"sync-test","STATUS":"waiting","TIMESTRING":"2019-04-17 00:10:38.000"} {"ROWTIME":1555511270573,"ROWKEY":"null","ID":8952,"CONTACT_ID":1472,"SUBJECT":"another sync ticket","STATUS":"new","TIMESTRING":"2019-04-17 00:11:23.000"} {"ROWTIME":1555511270573,"ROWKEY":"null","ID":8952,"CONTACT_ID":1472,"SUBJECT":"another sync ticket","STATUS":"close-request","TIMESTRING":"2019-04-17 00:12:04.000"} -
Register the stream
CREATE STREAM TICKETS (ID INT, CONTACT_ID VARCHAR, SUBJECT VARCHAR, STATUS VARCHAR, TIMESTRING VARCHAR) WITH (KAFKA_TOPIC='tickets', VALUE_FORMAT='JSON'); -
Query the data
ksql> SET 'auto.offset.reset' = 'earliest'; ksql> SELECT * FROM TICKETS; 1555502643806 | null | 2216 | 1472 | Test Bodenbach | closed | 2012-11-08 10:34:30.000 1555502643806 | null | 8945 | 1472 | sync-test | waiting | 2019-04-16 23:07:01.000 1555502643806 | null | 8945 | 1472 | sync-test | processing | 2019-04-16 23:52:08.000 1555502643806 | null | 8945 | 1472 | sync-test | waiting | 2019-04-17 00:10:38.000 1555502643806 | null | 8952 | 1472 | another sync ticket | new | 2019-04-17 00:11:23.000 1555502643806 | null | 8952 | 1472 | another sync ticket | close-request | 2019-04-17 00:12:04.000 -
At this point we can use
CASEto pivot the aggregates:SELECT CONTACT_ID, SUM(CASE WHEN STATUS='new' THEN 1 ELSE 0 END) AS TICKETS_NEW, SUM(CASE WHEN STATUS='processing' THEN 1 ELSE 0 END) AS TICKETS_PROCESSING, SUM(CASE WHEN STATUS='waiting' THEN 1 ELSE 0 END) AS TICKETS_WAITING, SUM(CASE WHEN STATUS='close-request' THEN 1 ELSE 0 END) AS TICKETS_CLOSEREQUEST , SUM(CASE WHEN STATUS='closed' THEN 1 ELSE 0 END) AS TICKETS_CLOSED FROM TICKETS GROUP BY CONTACT_ID; 1472 | 1 | 1 | 2 | 1 | 1But, you’ll notice that the answer isn’t as expected. This is because we’re counting all six input events.
Let’s look at a single ticket, ID
8945—this goes through three state changes (waiting->processing->waiting) which each get included in the aggregate. We can validate this as follows with a simple predicate:SELECT CONTACT_ID, SUM(CASE WHEN STATUS='new' THEN 1 ELSE 0 END) AS TICKETS_NEW, SUM(CASE WHEN STATUS='processing' THEN 1 ELSE 0 END) AS TICKETS_PROCESSING, SUM(CASE WHEN STATUS='waiting' THEN 1 ELSE 0 END) AS TICKETS_WAITING, SUM(CASE WHEN STATUS='close-request' THEN 1 ELSE 0 END) AS TICKETS_CLOSEREQUEST , SUM(CASE WHEN STATUS='closed' THEN 1 ELSE 0 END) AS TICKETS_CLOSED FROM TICKETS WHERE ID=8945 GROUP BY CONTACT_ID; 1472 | 0 | 1 | 2 | 0 | 0 -
What we actually want is the current state for each ticket. So repartition the data on ticket ID:
CREATE STREAM TICKETS_BY_ID AS SELECT * FROM TICKETS PARTITION BY ID; CREATE TABLE TICKETS_TABLE (ID INT, CONTACT_ID INT, SUBJECT VARCHAR, STATUS VARCHAR, TIMESTRING VARCHAR) WITH (KAFKA_TOPIC='TICKETS_BY_ID', VALUE_FORMAT='JSON', KEY='ID'); -
Compare event stream vs current state
-
Event stream (KSQL Stream)
ksql> SELECT ID, TIMESTRING, STATUS FROM TICKETS; 2216 | 2012-11-08 10:34:30.000 | closed 8945 | 2019-04-16 23:07:01.000 | waiting 8945 | 2019-04-16 23:52:08.000 | processing 8945 | 2019-04-17 00:10:38.000 | waiting 8952 | 2019-04-17 00:11:23.000 | new 8952 | 2019-04-17 00:12:04.000 | close-request -
Current state (KSQL Table)
ksql> SELECT ID, TIMESTRING, STATUS FROM TICKETS_TABLE; 2216 | 2012-11-08 10:34:30.000 | closed 8945 | 2019-04-17 00:10:38.000 | waiting 8952 | 2019-04-17 00:12:04.000 | close-request
-
-
We want an aggregate of the table—we want to run the same
SUM(CASE…)…GROUP BYtrick that we did above, but based on the current state of each ticket, rather than each event:SELECT CONTACT_ID, SUM(CASE WHEN STATUS='new' THEN 1 ELSE 0 END) AS TICKETS_NEW, SUM(CASE WHEN STATUS='processing' THEN 1 ELSE 0 END) AS TICKETS_PROCESSING, SUM(CASE WHEN STATUS='waiting' THEN 1 ELSE 0 END) AS TICKETS_WAITING, SUM(CASE WHEN STATUS='close-request' THEN 1 ELSE 0 END) AS TICKETS_CLOSEREQUEST , SUM(CASE WHEN STATUS='closed' THEN 1 ELSE 0 END) AS TICKETS_CLOSED FROM TICKETS_TABLE GROUP BY CONTACT_ID;This gives us what we want:
1472 | 0 | 0 | 1 | 1 | 1 -
Let’s feed another ticket’s events into the topic and observe how the table’s state changes. Rows from a table are re-emitted when the state changes; you can also cancel the
SELECTand rerun it to see the current state only.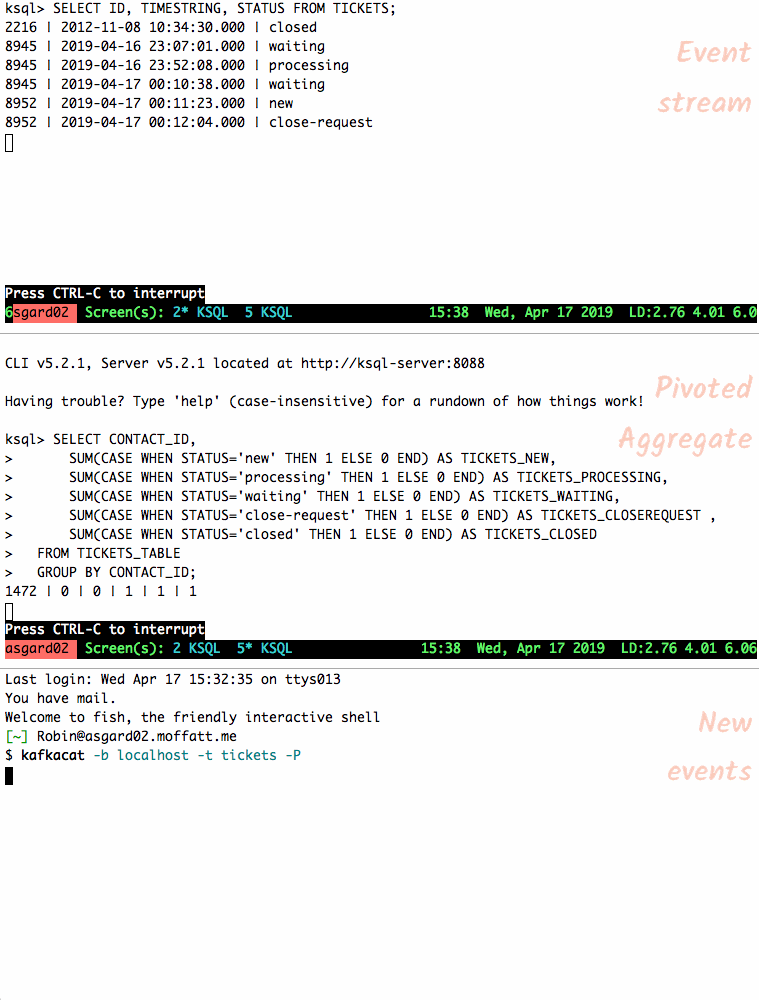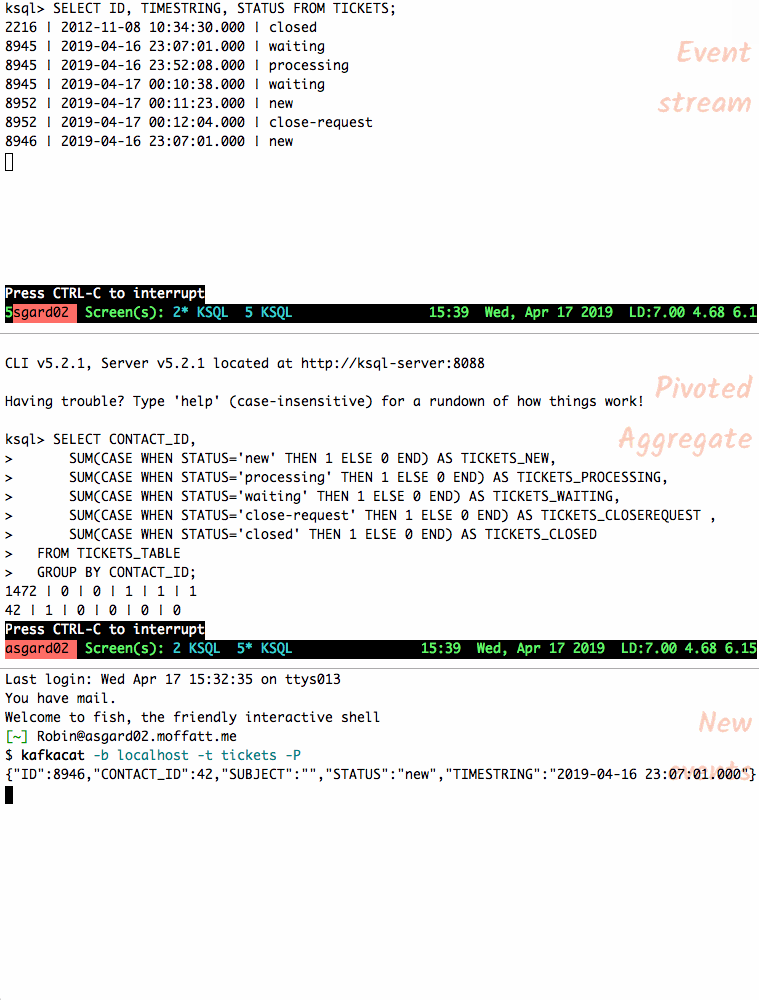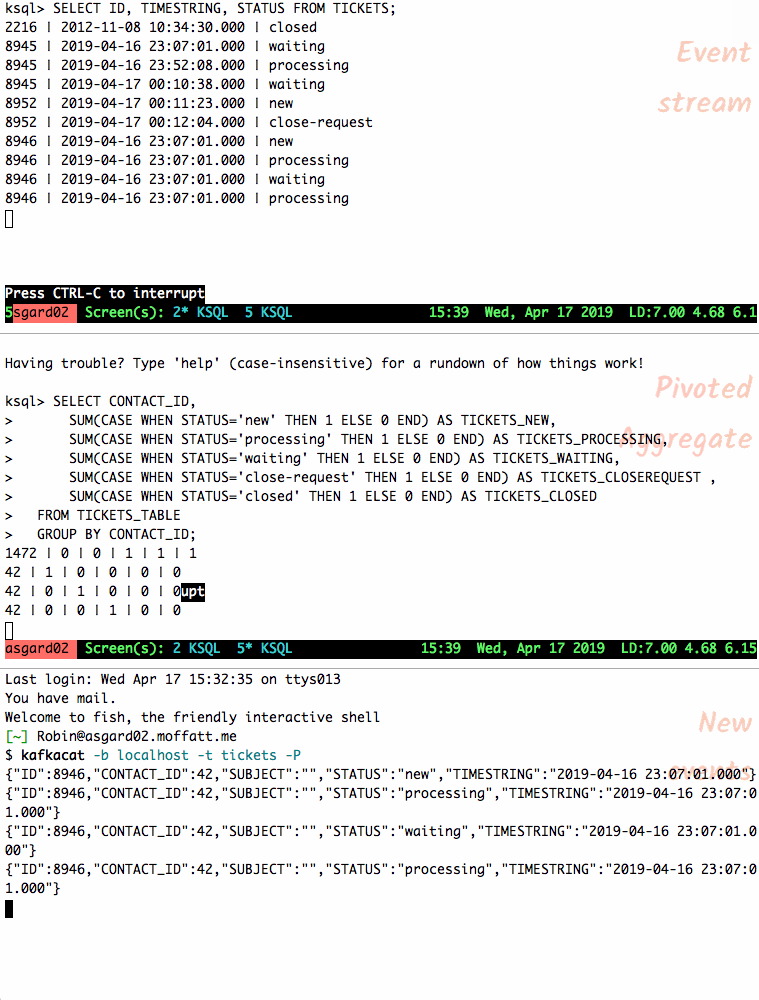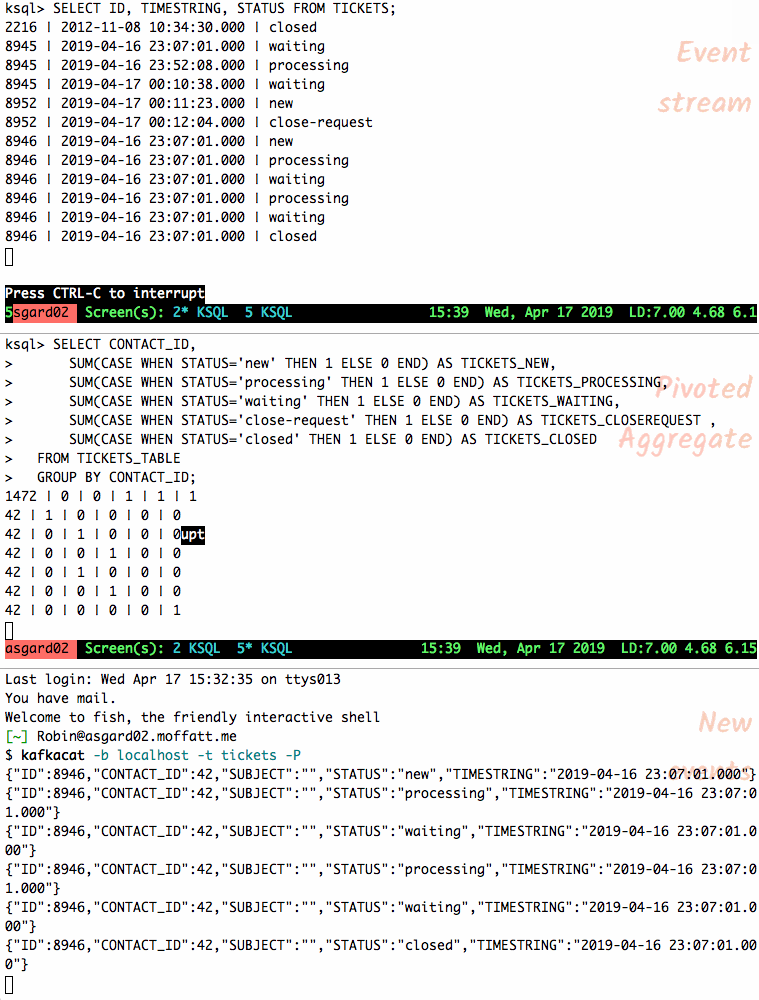
Sample data to try it for yourself:
{"ID":8946,"CONTACT_ID":42,"SUBJECT":"","STATUS":"new","TIMESTRING":"2019-04-16 23:07:01.000"} {"ID":8946,"CONTACT_ID":42,"SUBJECT":"","STATUS":"processing","TIMESTRING":"2019-04-16 23:07:01.000"} {"ID":8946,"CONTACT_ID":42,"SUBJECT":"","STATUS":"waiting","TIMESTRING":"2019-04-16 23:07:01.000"} {"ID":8946,"CONTACT_ID":42,"SUBJECT":"","STATUS":"processing","TIMESTRING":"2019-04-16 23:07:01.000"} {"ID":8946,"CONTACT_ID":42,"SUBJECT":"","STATUS":"waiting","TIMESTRING":"2019-04-16 23:07:01.000"} {"ID":8946,"CONTACT_ID":42,"SUBJECT":"","STATUS":"closed","TIMESTRING":"2019-04-16 23:07:01.000"} {"ID":8946,"CONTACT_ID":42,"SUBJECT":"","STATUS":"close-request","TIMESTRING":"2019-04-16 23:07:01.000"}
If you want to try this out further you can generate an stream of additional dummy data with this from Mockaroo, piped through awk to slow it down so you can see the effect on the generated aggregates as each message arrives:
while [ 1 -eq 1 ]
do curl -s "https://api.mockaroo.com/api/f2d6c8a0?count=1000&key=ff7856d0" | \
awk '{print $0;system("sleep 2");}' | \
kafkacat -b localhost -t tickets -P
done