
Snowflake is the data warehouse built for the cloud, so let’s get all ☁️ cloudy and stream some data from Kafka running in Confluent Cloud to Snowflake!
What I’m showing also works just as well for an on-premises Kafka cluster. I’m using SQL Server as an example data source, with Debezium to capture and stream and changes from it into Kafka.
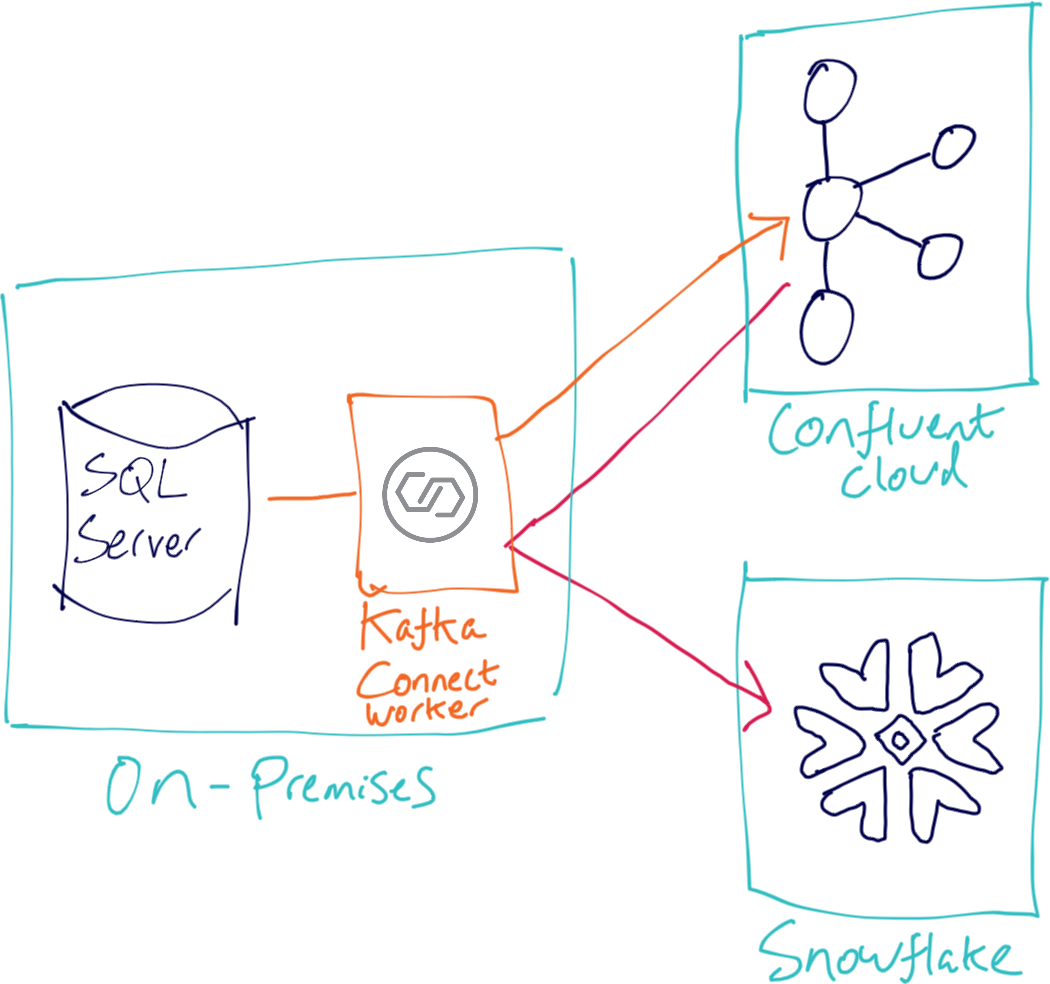
I’m assuming that you’ve signed up for Confluent Cloud and Snowflake and are the proud owner of credentials for both. I’m going to use a demo rig based on Docker to provision SQL Server and a Kafka Connect worker, but you can use your own setup if you want.
All the code shown here is based on this github repo. If you’re following along then make sure you set up .env (copy the template from .env.example) with all of your cloud details. This .env file gets mounted in the Docker container to /data/credentials.properties, which is what’s referenced in the connector configurations below.
SQL Server ➡️ Kafka with Debezium 🔗
SQL Server needs to be configured for CDC at a database level:
USE [demo]
GO
EXEC sys.sp_cdc_enable_db
GO and then per table:
USE [demo]
EXEC sys.sp_cdc_enable_table
@source_schema = N'dbo',
@source_name = N'ORDERS',
@role_name = NULL,
@supports_net_changes = 0
GO Once that’s done you can setup the connector. If you’ve not installed it already then make sure you’ve installed the Debezium SQL Server connector in your Kafka Connect worker and restarted it:
confluent-hub install --no-prompt debezium/debezium-connector-sqlserver:0.10.0Check that the plugin has been loaded successfully:
$ curl -s localhost:8083/connector-plugins|jq '.[].class'|grep debezium
"io.debezium.connector.sqlserver.SqlServerConnector"Debezium will write to a topic with all of the data from SQL Server. Debezium also needs its own topic for tracking the DDL—and we need to pre-create both these topics (see this article for more details):
$ ccloud kafka topic create --partitions 1 dbz_dbhistory.mssql.asgard-01
$ ccloud kafka topic create mssql-01-mssql.dbo.ORDERS
$ ccloud kafka topic list
Name
+-------------------------------------+
dbz_dbhistory.mssql.asgard-01
mssql-01-mssql.dbo.ORDERSNow create the connector. It’s a bit more verbose because we’re using a secure Kafka cluster and Debezium needs the details passed directly to it:
curl -i -X PUT -H "Content-Type:application/json" \
http://localhost:8083/connectors/source-debezium-mssql-01/config \
-d '{
"connector.class": "io.debezium.connector.sqlserver.SqlServerConnector",
"database.hostname": "mssql",
"database.port": "1433",
"database.user": "sa",
"database.password": "Admin123",
"database.dbname": "demo",
"database.server.name": "mssql",
"table.whitelist":"dbo.orders",
"database.history.kafka.bootstrap.servers": "${file:/data/credentials.properties:CCLOUD_BROKER_HOST}:9092",
"database.history.kafka.topic": "dbz_dbhistory.mssql.asgard-01",
"database.history.consumer.security.protocol": "SASL_SSL",
"database.history.consumer.ssl.endpoint.identification.algorithm": "https",
"database.history.consumer.sasl.mechanism": "PLAIN",
"database.history.consumer.sasl.jaas.config": "org.apache.kafka.common.security.plain.PlainLoginModule required username=\"${file:/data/credentials.properties:CCLOUD_API_KEY}\" password=\"${file:/data/credentials.properties:CCLOUD_API_SECRET}\";",
"database.history.producer.security.protocol": "SASL_SSL",
"database.history.producer.ssl.endpoint.identification.algorithm": "https",
"database.history.producer.sasl.mechanism": "PLAIN",
"database.history.producer.sasl.jaas.config": "org.apache.kafka.common.security.plain.PlainLoginModule required username=\"${file:/data/credentials.properties:CCLOUD_API_KEY}\" password=\"${file:/data/credentials.properties:CCLOUD_API_SECRET}\";",
"decimal.handling.mode":"double",
"transforms": "unwrap,addTopicPrefix",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"transforms.addTopicPrefix.type":"org.apache.kafka.connect.transforms.RegexRouter",
"transforms.addTopicPrefix.regex":"(.*)",
"transforms.addTopicPrefix.replacement":"mssql-01-$1"
}'With that running we can then check the data from Kafka. Note that we’re using Avro to serialise the data, with the Schema Registry running as part of Confluent Cloud.
$ ccloud kafka topic consume --from-beginning mssql-04-mssql.dbo.ORDERS
Starting Kafka Consumer. ^C to exit
����������@Proper Job
���q=
ףp�?Wainwright
��Ҝ333333@Proper Job
�ޜ��Q��@GalenaBecause it’s Avro, it renders here as a bunch of odd characters. We can use a tool such as kafkacat if we want to deserialise it:
source .env
docker run --rm edenhill/kafkacat:1.5.0 \
-X security.protocol=SASL_SSL -X sasl.mechanisms=PLAIN \
-X ssl.ca.location=./etc/ssl/cert.pem -X api.version.request=true \
-b ${CCLOUD_BROKER_HOST}:9092 \
-X sasl.username="${CCLOUD_API_KEY}" \
-X sasl.password="${CCLOUD_API_SECRET}" \
-r https://"${CCLOUD_SCHEMA_REGISTRY_API_KEY}":"${CCLOUD_SCHEMA_REGISTRY_API_SECRET}"@${CCLOUD_SCHEMA_REGISTRY_HOST} \
-s avro \
-t mssql-04-mssql.dbo.ORDERS \
-f 'Topic %t[%p], offset: %o, Headers: %h, key: %k, payload: %S bytes: %s\n' \
-C -o beginning -c5Topic mssql-04-mssql.dbo.ORDERS[5], offset: 0, Headers: , key: , payload: 34 bytes: {"order_id": {"int": 5}, "customer_id": {"int": 14}, "order_ts": {"int": 18233}, "order_total_usd": {"double": 3.8900000000000001}, "item": {"string": "Wainwright"}}
Topic mssql-04-mssql.dbo.ORDERS[5], offset: 1, Headers: , key: , payload: 30 bytes: {"order_id": {"int": 6}, "customer_id": {"int": 16}, "order_ts": {"int": 18225}, "order_total_usd": {"double": 3.9100000000000001}, "item": {"string": "Galena"}}
Topic mssql-04-mssql.dbo.ORDERS[5], offset: 2, Headers: , key: , payload: 32 bytes: {"order_id": {"int": 7}, "customer_id": {"int": 19}, "order_ts": {"int": 18227}, "order_total_usd": {"double": 4.6900000000000004}, "item": {"string": "Landlord"}}
Topic mssql-04-mssql.dbo.ORDERS[5], offset: 3, Headers: , key: , payload: 34 bytes: {"order_id": {"int": 8}, "customer_id": {"int": 2}, "order_ts": {"int": 18228}, "order_total_usd": {"double": 3.6699999999999999}, "item": {"string": "Proper Job"}}
Topic mssql-04-mssql.dbo.ORDERS[5], offset: 4, Headers: , key: , payload: 39 bytes: {"order_id": {"int": 9}, "customer_id": {"int": 5}, "order_ts": {"int": 18229}, "order_total_usd": {"double": 2.2400000000000002}, "item": {"string": "Black Sheep Ale"}}Kafka ➡️ Snowflake ❄️ 🔗
Setting up Snowflake account and key pair 🔗
To send data to Snowflake you first need to generate a private/public key pair that will be used for authentication. Generate the keys:
# Create Private key - keep this safe, do not share!
openssl genrsa -out snowflake_key.pem 2048
# Generate public key from private key. You can share your public key.
openssl rsa -in snowflake_key.pem -pubout -out snowflake_key.pubYou should now have two files:
$ ls -l snowflake_key*
-rw-r--r-- 1 rmoff staff 1679 21 Nov 09:28 snowflake_key.pem
-rw-r--r-- 1 rmoff staff 451 21 Nov 09:28 snowflake_key.pubNow you need to get your public key:
$ cat snowflake_key.pub
-----BEGIN PUBLIC KEY-----
MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEAya/BRlyhsfdlJQnPqoRn
lJfxKxujoyionNBPIDFpVpGZ9C1ZE7Q1kGIrEoZfq1t2p6lT8cX6gIZkMDF10I/8
yqHGiCdSEQBuMYXwWpnl3C1sttFHNfxbsjiKSZDlMTbEmzwU5s5LpMt8YvFWp8Iu
3ilHK9Vwy0wbsMDCjDcrC6xCS6qp1n4oso+V24aaxKd/mUtpPy9toAx2NC5GMoDb
tehlbTyPkk/9qFl7GUsf46HbQMEGoGkRrY9VFm+3Z8wCwsFNpURIvLEBcrTFdnmn
IgDBa96+dKgaN8qV6RW3ZMheQOJH1tP3M0qXsLNbR00E7yAlCYjNQD3hXjGKL3Oc
5wIDAQAB
-----END PUBLIC KEY-----But minus the header and footer and joined over a single line. You can do this manually, or automagically:
$ grep -v "BEGIN PUBLIC" snowflake_key.pub | grep -v "END PUBLIC"|tr -d \n
MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEAya/BRlyhsfdlJQnPqoRnlJfxKxujoyionNBPIDFpVpGZ9C1ZE7Q1kGIrEoZfq1t2p6lT8cX6gIZkMDF10I/8yqHGiCdSEQBuMYXwWpnl3C1sttFHNfxbsjiKSZDlMTbEmzwU5s5LpMt8YvFWp8Iu3ilHK9Vwy0wbsMDCjDcrC6xCS6qp1n4oso+V24aaxKd/mUtpPy9toAx2NC5GMoDbtehlbTyPkk/9qFl7GUsf46HbQMEGoGkRrY9VFm+3Z8wCwsFNpURIvLEBcrTFdnmnIgDBa96+dKgaN8qV6RW3ZMheQOJH1tP3M0qXsLNbR00E7yAlCYjNQD3hXjGKL3Oc5wIDAQABNow head to Snowflake, where we need to create a user for loading the data. First up, switch to the SECURITYADMIN role.

Make sure you do this in the Context section of the worksheet, not the top-right dropdown (otherwise you’ll get SQL access control error: Insufficient privileges to operate on account 'xyz').
|
Now create the user, here called kafka. Because we’re in demo-land we’re also granting Kafka the keys to the kingdom (SYSADMIN), just to make everything nice 'n easy.
CREATE USER kafka RSA_PUBLIC_KEY='MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEAya/BRlyhsfdlJQnPqoRnlJfxKxujoyionNBPIDFpVpGZ9C1ZE7Q1kGIrEoZfq1t2p6lT8cX6gIZkMDF10I/8yqHGiCdSEQBuMYXwWpnl3C1sttFHNfxbsjiKSZDlMTbEmzwU5s5LpMt8YvFWp8Iu3ilHK9Vwy0wbsMDCjDcrC6xCS6qp1n4oso+V24aaxKd/mUtpPy9toAx2NC5GMoDbtehlbTyPkk/9qFl7GUsf46HbQMEGoGkRrY9VFm+3Z8wCwsFNpURIvLEBcrTFdnmnIgDBa96+dKgaN8qV6RW3ZMheQOJH1tP3M0qXsLNbR00E7yAlCYjNQD3hXjGKL3Oc5wIDAQAB';
GRANT ROLE SYSADMIN TO USER kafka;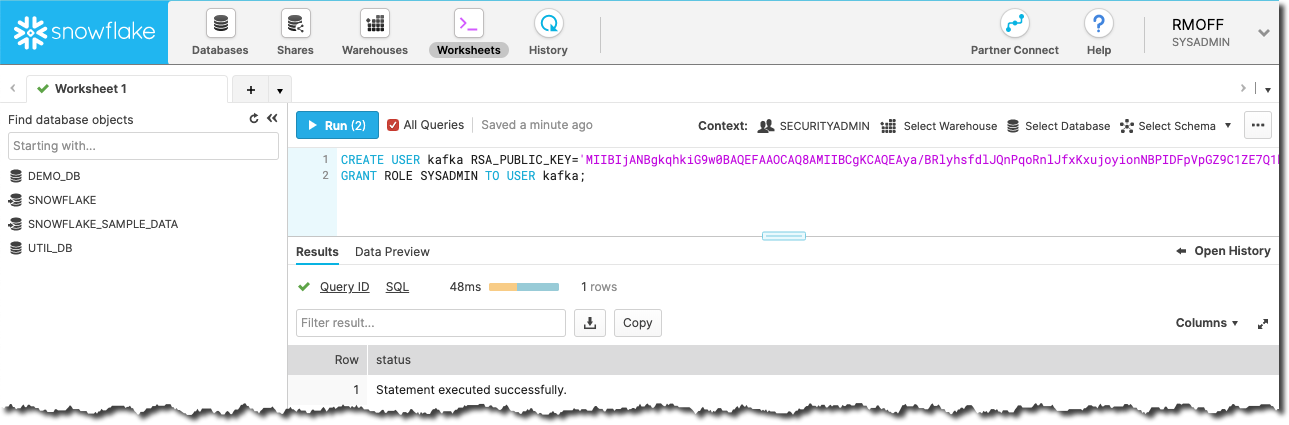
Now we need to extract the private key for the key pair, which is in the .pem file that we created, minus the header and footer and on a single line:
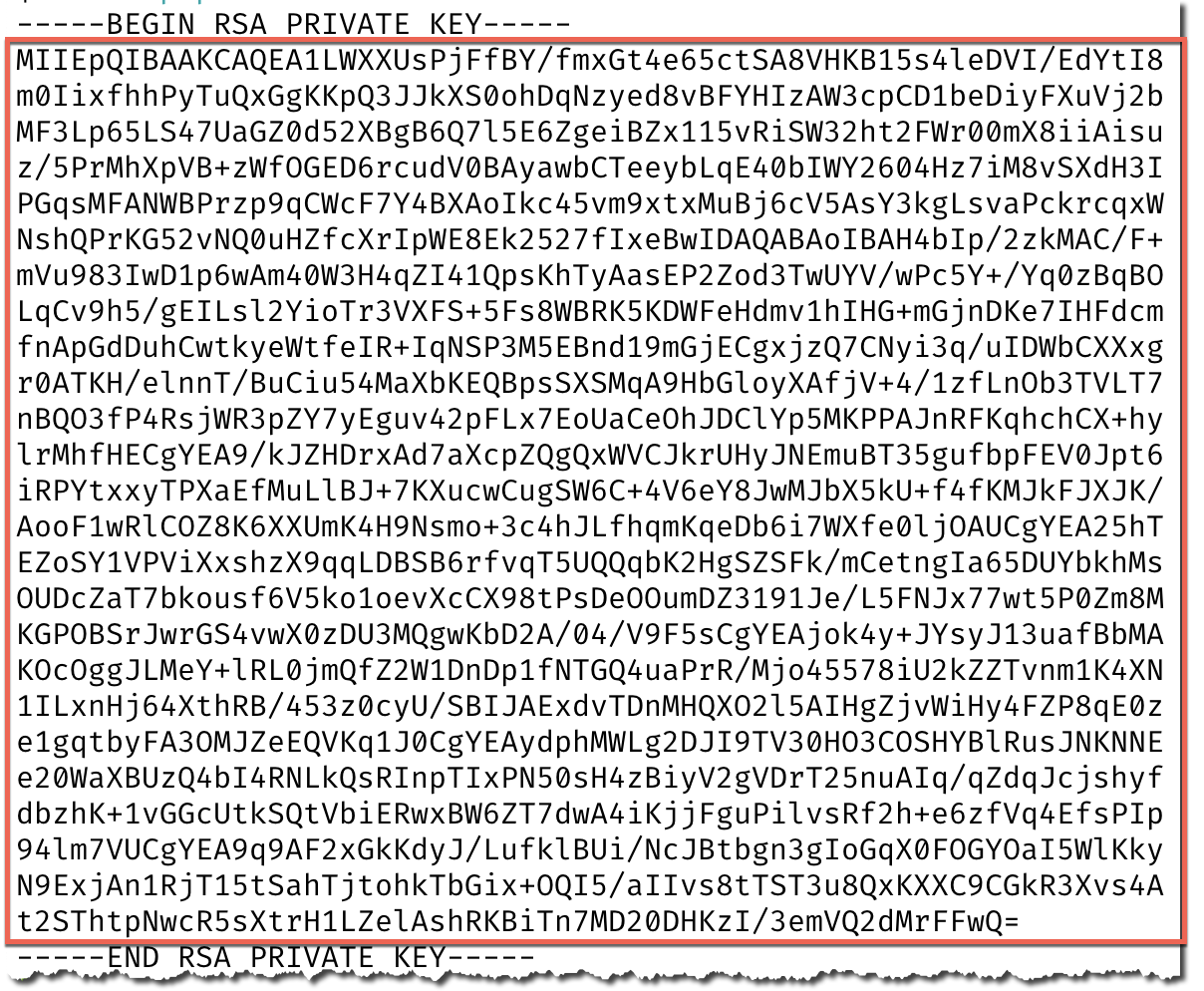
| Your private key is private - don’t share it with anyone who shouldn’t have access to the account, and definitely don’t post it on the internet on a blog post! |
As before you can extract the key automagically with:
grep -v "BEGIN RSA PRIVATE" snowflake_key.pem | grep -v "END RSA PRIVATE"|tr -d \nPut this value, along with the URL of your Snowflake environment and the user that we created (kafka) in the .env file
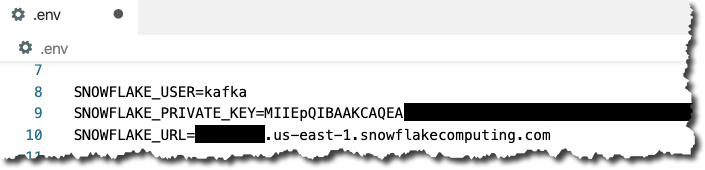
This .env file gets mounted in the Docker container to /data/credentials.properties which is what’s referenced in the connector configuration below.
Setting up the Snowflake connector 🔗
Install the connector:
confluent-hub install --no-prompt snowflakeinc/snowflake-kafka-connector:0.5.5Restart the Kafka Connect connector and check that it’s been loaded:
$ curl -s localhost:8083/connector-plugins|jq '.[].class'|grep snowflake
"com.snowflake.kafka.connector.SnowflakeSinkConnector"Now set up your connector configuration. A few important settings of note:
-
topics- A comma separated list of one or more topics that are to be streamed to Snowflake. You can optionally map topics to table names withsnowflake.topic2table.mapbut this is not mandatory. -
value.converter- Snowflake provide their own converters. Use either:-
com.snowflake.kafka.connector.records.SnowflakeAvroConverter -
com.snowflake.kafka.connector.records.SnowflakeJsonConverter
-
-
Authentication / sensitive information I’ve embedded these in a separate file (
.env) that’s loaded by the connector directly:-
snowflake.url.name -
snowflake.user.name- we created the userkafkafor this above -
snowflake.private.key- this is the key that we extracted in the step above
-
You can see all of the configuration options in the documentation.
Create the connector:
curl -i -X PUT -H "Content-Type:application/json" \
http://localhost:8083/connectors/sink_snowflake_01/config \
-d '{
"connector.class":"com.snowflake.kafka.connector.SnowflakeSinkConnector",
"tasks.max":1,
"topics":"mssql-01-mssql.dbo.ORDERS",
"snowflake.url.name":"${file:/data/credentials.properties:SNOWFLAKE_HOST}",
"snowflake.user.name":"${file:/data/credentials.properties:SNOWFLAKE_USER}",
"snowflake.user.role":"SYSADMIN",
"snowflake.private.key":"${file:/data/credentials.properties:SNOWFLAKE_PRIVATE_KEY}",
"snowflake.database.name":"DEMO_DB",
"snowflake.schema.name":"PUBLIC",
"key.converter":"org.apache.kafka.connect.storage.StringConverter",
"value.converter":"com.snowflake.kafka.connector.records.SnowflakeAvroConverter",
"value.converter.schema.registry.url":"https://${file:/data/credentials.properties:CCLOUD_SCHEMA_REGISTRY_HOST}",
"value.converter.basic.auth.credentials.source":"USER_INFO",
"value.converter.basic.auth.user.info":"${file:/data/credentials.properties:CCLOUD_SCHEMA_REGISTRY_API_KEY}:${file:/data/credentials.properties:CCLOUD_SCHEMA_REGISTRY_API_SECRET}"
}'Check that it’s running:
$ curl -s "http://localhost:8083/connectors?expand=info&expand=status" | \
jq '. | to_entries[] | [ .value.info.type, .key, .value.status.connector.state,.value.status.tasks[].state,.value.info.config."connector.class"]|join(":|:")' | \
column -s : -t| sed 's/\"//g'| sort
sink | sink_snowflake_01 | RUNNING | RUNNING | com.snowflake.kafka.connector.SnowflakeSinkConnectorNow head over to Snowflake and you’ll see your table created and data loaded:
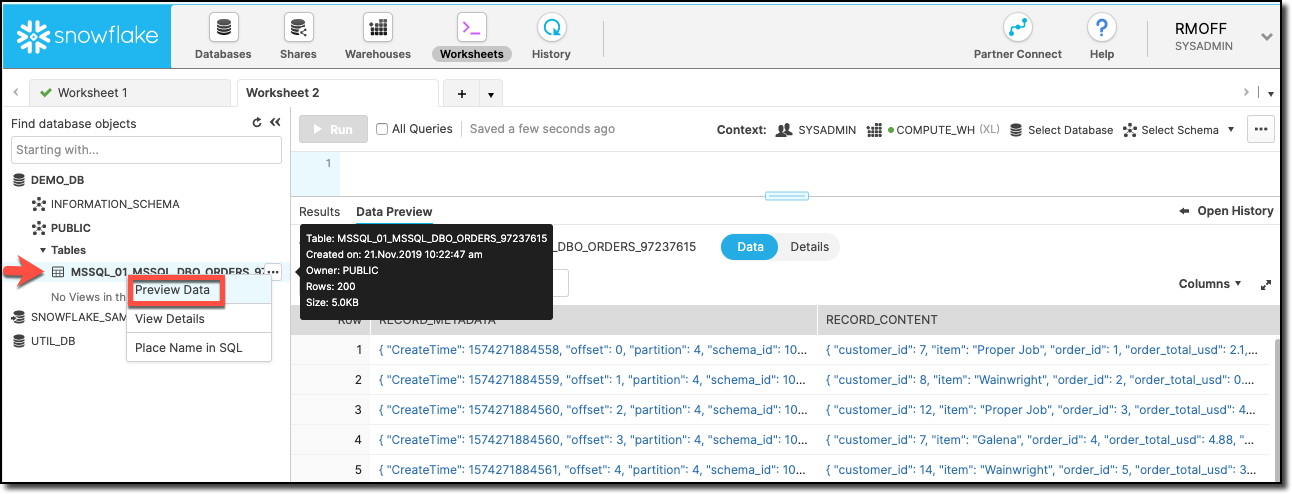
The connector writes the Kafka message payload to the RECORD_CONTENT field and its metadata (partition, offset, etc) to RECORD_METADATA. You can access the nested values using the colon as a seperator, e.g.:
SELECT RECORD_CONTENT:customer_id AS CUSTOMER_ID,
RECORD_CONTENT:item AS ITEM,
RECORD_CONTENT:order_total_usd AS ORDER_TOTAL_USD
FROM "DEMO_DB"."PUBLIC"."MSSQL_01_MSSQL_DBO_ORDERS_97237615";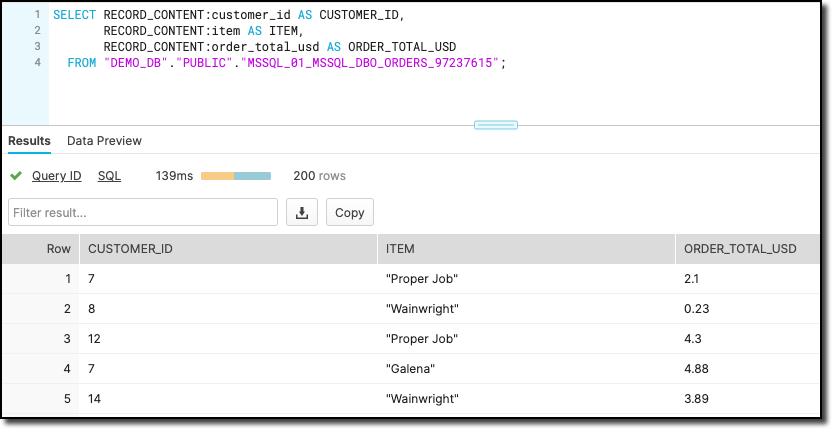
Footnote : a few gotchas 🔗
-
Gotcha 01 : The connector name must be a valid Snowflake identifier. If it’s not you’ll get this error:
[SF_KAFKA_CONNECTOR] name is empty or invalid. It should match Snowflake object identifier syntax. Please see the documentation. (com.snowflake.kafka.connector.Utils:246)In the example above, the connector name is
sink_snowflake_01. If I tried to name itsink-snowflake-01(i.e. using-instead of_) then it would fail 🤷♂️See this issue on the Snowflake connector repo.
Solution: don’t name your connector with characters that aren’t valid in a Snowflake object name.
-
You have to use Snowflake’s own converters, or else you get:
[SF_KAFKA_CONNECTOR] Exception: Invalid record data [SF_KAFKA_CONNECTOR] Error Code: 0019 [SF_KAFKA_CONNECTOR] Detail: Unrecognizable record content, please use Snowflake ConvertersSolution: Depending on how your data is serialised, use
com.snowflake.kafka.connector.records.SnowflakeJsonConverterorcom.snowflake.kafka.connector.records.SnowflakeAvroConverter. -
Sometimes the connector will fail with an error and need restarting:
[SF_KAFKA_CONNECTOR] Exception: Failed to put records [SF_KAFKA_CONNECTOR] Error Code: 5014 [SF_KAFKA_CONNECTOR] Detail: SinkTask hasn't been initialized before calling PUT function at com.snowflake.kafka.connector.internal.SnowflakeErrors.getException(SnowflakeErrors.java:362) at com.snowflake.kafka.connector.internal.SnowflakeErrors.getException(SnowflakeErrors.java:321) at com.snowflake.kafka.connector.SnowflakeSinkTask.getSink(SnowflakeSinkTask.java:94) at com.snowflake.kafka.connector.SnowflakeSinkTask.put(SnowflakeSinkTask.java:195) at org.apache.kafka.connect.runtime.WorkerSinkTask.deliverMessages(WorkerSinkTask.java:538) at org.apache.kafka.connect.runtime.WorkerSinkTask.poll(WorkerSinkTask.java:321) at org.apache.kafka.connect.runtime.WorkerSinkTask.iteration(WorkerSinkTask.java:224) at org.apache.kafka.connect.runtime.WorkerSinkTask.execute(WorkerSinkTask.java:192) at org.apache.kafka.connect.runtime.WorkerTask.doRun(WorkerTask.java:177) at org.apache.kafka.connect.runtime.WorkerTask.run(WorkerTask.java:227) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748)Solution: Restart the Connect task via the REST API. If your connector is called
sink_snowflake_01then you can run this to restart task0:curl -X POST http://localhost:8083/connectors/sink_snowflake_01/tasks/0/restart