
Whilst Apache Kafka is an event streaming platform designed for, well, streams of events, it’s perfectly valid to use it as a store of data which perhaps changes only occasionally (or even never). I’m thinking here of reference data (lookup data) that’s used to enrich regular streams of events.
You might well get your reference data from a database where it resides and do so effectively using CDC - but sometimes it comes down to those pesky CSV files that we all know and love/hate. Simple, awful, but effective. I wrote previously about loading CSV data into Kafka from files that are updated frequently, but here I want to look at CSV files that are not changing. Kafka Connect simplifies getting data in to (and out of) Kafka but even Kafka Connect becomes a bit of an overhead when you just have a single file that you want to load into a topic and then never deal with again. I spent this afternoon wrangling with a couple of CSV-ish files, and building on my previous article about neat tricks you can do in bash with data, I have some more to share with you here :)
The data 🔗
The first file has two fields and is semi-colon delimited:
$ cat data01.csv
shipname;mmsi
FRIO FORWIN;210631000
AQUAMARINE;214182223
OCEAN STAR 98;214182700
MINIK ARCTICA;219663000
IVALO ARCTICA;219667000
IZAR ARGIA;224434000
V CENTENARIO;224739000
MARINERO2;238187240
SANTINA;256384000The second has more fields, and is comma-separated. There is a common field in both files (mmsi) and this will be important later.
$ cat data02.csv
mmsi,shipname,callsign,flag,imo,first_timestamp,last_timestamp
306117000,SIERRALAUREL,PJBQ,ANT,9163403,2018-03-29T08:34:21Z,2018-06-30T17:08:41Z
306873000,SIERRALEYRE,PJJZ,ANT,9135822,2012-01-01T01:06:00Z,2012-06-26T08:58:28Z
309681,GREENBRAZIL,C6WH6,BHS,9045792,2018-06-29T10:34:00Z,2018-06-30T23:47:40Z
308735000,NOVA BRETAGNE,C6JI7,BHS,9000364,2012-01-01T00:39:08Z,2013-09-12T10:03:48Z
311000682,SIERRA LARA,C6DI3,BHS,9120205,2017-07-03T10:28:05Z,2018-06-30T23:35:36Z
311000433,SILVER PEARL,C6CC5,BHS,8400050,2015-08-19T10:00:02Z,2018-06-30T23:57:13Z
311000709,SIERRA LEYRE,C6DL3,BHS,9135822,2017-10-12T08:51:41Z,2018-06-30T06:08:40Z
311043900,GREENCONCORDIA,C6YS7,BHS,9011038,2012-01-03T22:17:16Z,2013-09-09T11:44:22Z
308572000,RUNAWAY BAY,C6PX2,BHS,9019640,2012-01-01T00:28:40Z,2017-02-08T06:13:05ZThe requirement 🔗
I’m using the data from both these files to enrich a stream of data about the movement of ships, based on the mmsi field as a key. I want to load both datasets into separate topics, with the mmsi field set as the key in both.
The solution - tl;dr 🔗
Whilst I could use Kafka Connect connectors for ingesting flat files into Kafka such as kafka-connect-spooldir and kafka-connect-filepulse, I wanted something dead simple. Since the data wasn’t changing I didn’t want to get into setting up connectors, and quick & dirty would be just fine.
The short answer here is kafkacat, which takes stdin as a source of messages for writing to Kafka. It can be given a delimiter to split the input into key and value for writing to Kafka.
The slightly longer answer is a few other bash tools for manipulating the data into an appropriate state for kafkacat to receive.
The solution - in detail 🔗
Switching fields around in bash 🔗
The first file, data01.csv, has the mmsi field second, and I want the first so that I can use it as the key when it gets to kafkacat. For that we can use awk:
awk -F";" '{ print $2 "," $1 }' data01.csvOr…we think we can. Because this was where the fun started. Check this out. What should happen is that with the field separator set to ; awk will store the first field in $1 and second in $2, which I can then just reverse in the print output. But what happens is this:
awk -F";" '{ print $2 "," $1 }' data01.csv
,shipname
,FRIO FORWIN
,AQUAMARINE
,OCEAN STAR 98Huh? I get the new field separator (a comma), and the the first field ($1) — but not the second. Weird. Let’s see if $2 is working:
awk -F";" '{ print $2 }' data01.csv
mmsi
210631000
214182223
214182700Yup, that field is working too - so why aren’t they working together?
When is a line break different from a line break? 🔗
After a lot of headscratching, and a lot of Google and StackOverflow, I hit on the problem.
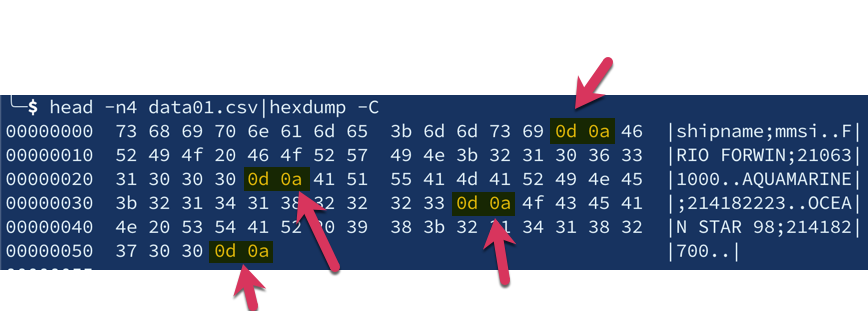
The file was written with /x0d /x0a (CRLF) line endings, which was screwing things up. I don’t actually know why (drop me a line if you do!) but once I stripped the CR (\r) them out with tr things started to look better:
$ tr -d '\r' < data01.csv |awk -F";" ' { print $2 "," $1 }'
mmsi,shipname
210631000,FRIO FORWIN
214182223,AQUAMARINE
214182700,OCEAN STAR 98Setting a key separator / Inserting hex values with awk 🔗
I’ve written before about a little trick for manipulating data from jq piped to kafkacat such that a key is set in the resulting Kafka message. I wanted to use the same approach here. It relies on putting a character between the key and value part of the data, and picking a character that isn’t going to appear elsewhere in the payload. I used \x1c here.
To use it as the separator between the two fields in awk looks like this - I’m piping it to hexdump so that you can see its effect:
$ tr -d '\r' < data01.csv | awk -F";" ' { print $2 "\x1c" $1 } '| hexdump -C
00000000 6d 6d 73 69 1c 73 68 69 70 6e 61 6d 65 0a 32 31 |mmsi.shipname.21|
00000010 30 36 33 31 30 30 30 1c 46 52 49 4f 20 46 4f 52 |0631000.FRIO FOR|
00000020 57 49 4e 0a 32 31 34 31 38 32 32 32 33 1c 41 51 |WIN.214182223.AQ|
00000030 55 41 4d 41 52 49 4e 45 0a 32 31 34 31 38 32 37 |UAMARINE.2141827|
00000040 30 30 1c 4f 43 45 41 4e 20 53 54 41 52 20 39 38 |00.OCEAN STAR 98|Now we’re ready to stream the data to Kafka, specifying this special character as the key separator to kafkacat:
tr -d '\r' < data01.csv | \
awk -F";" ' { print $2 "\x1c" $1 } '| \
kafkacat -b localhost:9092 -t data01 -K$'\x1c' -PWe can consume the data from the Kafka topic with kafkacat to check that it’s worked:
$ kafkacat \
-b localhost:9092 \
-C -o beginning -u \
-t data01 \
-f 'Topic+Partition+Offset: %t+%p+%o\tKey: %k\tValue: %s\n'
Topic+Partition+Offset: data01+0+0 Key: mmsi Value: shipname
Topic+Partition+Offset: data01+0+1 Key: 210631000 Value: FRIO FORWIN
Topic+Partition+Offset: data01+0+2 Key: 214182223 Value: AQUAMARINE
Topic+Partition+Offset: data01+0+3 Key: 214182700 Value: OCEAN STAR 98NOTE: The CSV header line has been ingested as a data row; if we were fussed we could filter it out prior to ingest with head.
So: one file down, one to go. The second one is a bit more tricky because we’ve got more fields to deal with. I don’t really want to start writing awk statements with a long list of field numbers and separators, so let’s see how we can do it a bit smarter.
Changing the first comma in a CSV file in bash 🔗
Unlike the previous file, the key field (mmsi) is the first field in this file so we don’t need to reorder things.
head data02.csv
mmsi,shipname,callsign,flag,imo,first_timestamp,last_timestamp
306117000,SIERRALAUREL,PJBQ,ANT,9163403,2018-03-29T08:34:21Z,2018-06-30T17:08:41Z
306873000,SIERRALEYRE,PJJZ,ANT,9135822,2012-01-01T01:06:00Z,2012-06-26T08:58:28Z
309681,GREENBRAZIL,C6WH6,BHS,9045792,2018-06-29T10:34:00Z,2018-06-30T23:47:40ZWe do, however, want to change the comma into our bespoke key/value delimiter. This time I reached for sed (although if there’s one thing I learnt from my afternoon of Googling is that sed and awk and always perl usually can be twisted to perform the same function).
In sed the very common usage is to change one thing for another—so much so that it’s become shorthand amongst nerds when reviewing documents to report a tyop (s/tyop/typo) — see what I did there? ;-)
So, with sed if you specify a trailing /g in the replacement expression then all matches are replaced:
$ echo 'one_two_three' | sed 's/_/ FOO /g'
one FOO two FOO threeWithout the trailing /g only the first match is replaced:
$ echo 'one_two_three' | sed 's/_/ FOO /'
one FOO two_threeSo we can use this to replace the first comma (after our key field), whilst leaving the others alone. As before we needed to strip out the CR characters in the line breaks with tr:
$ tr -d '\r' < data02.csv|sed 's/,/ FOO /'
mmsi FOO shipname,callsign,flag,imo,first_timestamp,last_timestamp
306117000 FOO SIERRALAUREL,PJBQ,ANT,9163403,2018-03-29T08:34:21Z,2018-06-30T17:08:41Z
306873000 FOO SIERRALEYRE,PJJZ,ANT,9135822,2012-01-01T01:06:00Z,2012-06-26T08:58:28Z
309681 FOO GREENBRAZIL,C6WH6,BHS,9045792,2018-06-29T10:34:00Z,2018-06-30T23:47:40ZNow all we need to do is replace ` FOO ` with a single-character hex value that we can use for the key delimiter in kafkacat. And this was where it got sticky.
Using a hex value in the replacement argument of sed 🔗
I started off with the fairly obvious, which didn’t work - I just got a literal x1c value:
$ tr -d '\r' < data02.csv|sed 's/,/\x1c/'
mmsix1cshipname,callsign,flag,imo,first_timestamp,last_timestamp
306117000x1cSIERRALAUREL,PJBQ,ANT,9163403,2018-03-29T08:34:21Z,2018-06-30T17:08:41Z
306873000x1cSIERRALEYRE,PJJZ,ANT,9135822,2012-01-01T01:06:00Z,2012-06-26T08:58:28Z
309681x1cGREENBRAZIL,C6WH6,BHS,9045792,2018-06-29T10:34:00Z,2018-06-30T23:47:40ZAll that Google wanted to tell me was how to replace a hex value with sed, rather than use hex in the replacement. Eventually I found this answer on StackOverflow which set me on the right lines - using $(printf '\x1c') (and because that uses single quotes, change the sed expression to be surrounded by double quotes)
tr -d '\r' < data02.csv|sed "s/,/$(printf '\x1c')/"|hexdump -C
00000000 6d 6d 73 69 1c 73 68 69 70 6e 61 6d 65 2c 63 61 |mmsi.shipname,ca|
00000010 6c 6c 73 69 67 6e 2c 66 6c 61 67 2c 69 6d 6f 2c |llsign,flag,imo,|
00000020 66 69 72 73 74 5f 74 69 6d 65 73 74 61 6d 70 2c |first_timestamp,|
00000030 6c 61 73 74 5f 74 69 6d 65 73 74 61 6d 70 0a 33 |last_timestamp.3|
00000040 30 36 31 31 37 30 30 30 1c 53 49 45 52 52 41 4c |06117000.SIERRAL|
00000050 41 55 52 45 4c 2c 50 4a 42 51 2c 41 4e 54 2c 39 |AUREL,PJBQ,ANT,9|
00000060 31 36 33 34 30 33 2c 32 30 31 38 2d 30 33 2d 32 |163403,2018-03-2|
00000070 39 54 30 38 3a 33 34 3a 32 31 5a 2c 32 30 31 38 |9T08:34:21Z,2018|
00000080 2d 30 36 2d 33 30 54 31 37 3a 30 38 3a 34 31 5a |-06-30T17:08:41Z|So after this I ended up with
tr -d '\r' < data02.csv | \
sed "s/,/$(printf '\x1c')/" | \
kafkacat -b localhost:9092 -t data02 -K$'\x1c' -PWhich worked a treat and loaded the data which looked like this once loaded:
$ kafkacat \
-b localhost:9092 \
-C -o beginning -u \
-t data02 \
-f 'Topic+Partition+Offset: %t+%p+%o\tKey: %k\tValue: %s\n'
Topic+Partition+Offset: data02+0+0 Key: mmsi Value: shipname,callsign,flag,imo,first_timestamp,last_timestamp
Topic+Partition+Offset: data02+0+1 Key: 306117000 Value: SIERRALAUREL,PJBQ,ANT,9163403,2018-03-29T08:34:21Z,2018-06-30T17:08:41Z
Topic+Partition+Offset: data02+0+2 Key: 306873000 Value: SIERRALEYRE,PJJZ,ANT,9135822,2012-01-01T01:06:00Z,2012-06-26T08:58:28Z
Topic+Partition+Offset: data02+0+3 Key: 309681 Value: GREENBRAZIL,C6WH6,BHS,9045792,2018-06-29T10:34:00Z,2018-06-30T23:47:40ZUsing the data 🔗
So, whilst my explanations may have been verbose, the actual result was relatively simple. With the data loaded into Kafka topics I could fire up ksqlDB (in which I was doing the stream processing) and define a table over each topic. The key (!!) thing with tables is that the Kafka message key must be the key declared in the table—which is why we did that extra work above at ingest time.
CREATE TABLE data01 (mmsi BIGINT PRIMARY KEY, shipname_raw varchar)
WITH (KAFKA_TOPIC='data01', FORMAT='DELIMITED');
CREATE TABLE data02 (mmsi BIGINT PRIMARY KEY,shipname VARCHAR,callsign VARCHAR,flag VARCHAR,imo VARCHAR,first_timestamp VARCHAR,last_timestamp VARCHAR)
WITH (KAFKA_TOPIC='data02', FORMAT='DELIMITED');And with the tables defined, I could query them:
ksql> SELECT * FROM data01 EMIT CHANGES LIMIT 3;
+-----------+--------------+
|MMSI |SHIPNAME_RAW |
+-----------+--------------+
|210631000 |FRIO FORWIN |
|214182223 |AQUAMARINE |
|214182700 |OCEAN STAR 98 |
Limit Reached
Query terminated
ksql> SELECT * FROM data02 EMIT CHANGES LIMIT 3;
+----------+-------------+---------+-----+--------+---------------------+---------------------+
|MMSI |SHIPNAME |CALLSIGN |FLAG |IMO |FIRST_TIMESTAMP |LAST_TIMESTAMP |
+----------+-------------+---------+-----+--------+---------------------+---------------------+
|306117000 |SIERRALAUREL |PJBQ |ANT |9163403 |2018-03-29T08:34:21Z |2018-06-30T17:08:41Z |
|306873000 |SIERRALEYRE |PJJZ |ANT |9135822 |2012-01-01T01:06:00Z |2012-06-26T08:58:28Z |
|309681 |GREENBRAZIL |C6WH6 |BHS |9045792 |2018-06-29T10:34:00Z |2018-06-30T23:47:40Z |
Limit Reached
Query terminatedOther suggestions 🔗
A couple of useful suggestions in response to this post, from Simon Aubury:
Nice blog as ever @rmoff. Another way to strip Windows line-endings (CR/LF) from a data file is to pipe through dos2unix
— Simon Aubury (@SimonAubury) February 27, 2021
and from edbond