
My journey with Apache Flink begins with an overview of what Flink actually is.
What better place to start than the Apache Flink website itself:
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.

In this post, I’m going to summarise my current—possibly naïve—understanding of:
- What Flink is
- What Flink is used for
- Who uses Flink
- How do you run Flink
- Where to find the Flink community
So: What is Flink? 🔗
I found a couple of excellent podcasts from Fabian Heuske and my Decodable colleague Robert Metzger respectively that gave some really useful background on the project:
- Flink started life as a research project in 2011, called Stratosphere.
- It was donated to Apache Software Foundation in 2014.
- Version 1.0 released 2016, latest version is 1.17 .
- Whilst it was originally designed for batch, it always used streaming principles, making its move into stream processing a logical one
- Hadoop revolutionised the distributed processing of data at scale, but was “dumb”. Flink aimed to use some of the principles whilst bringing in important learnings from the RDBMS world that had been missed in Hadoop. Flink includes a bunch of things that you’d have to build for yourself in Hadoop, such as pipelined execution (e.g. all stages run concurrently and stream data), native join operators, and it re-use of data properties such as the data being sorted or partitioned already in a certain way.
- JVM-based. SQL and PyFlink added in recent years.
- Flink is a Distributed system. Each worker stores state.
- It supports exactly once state guarantee with checkpointing across workers that stores the processing state (such as aggregations), as well as the metadata of input sources (e.g. Kafka topics offsets) all on a distributed filesystem (e.g. S3)
- Event time processing. Uses watermarks (same as Google data flow), which enable you to trade off between completeness and latency.
- 🤯 Everything is a stream; it’s just some streams are bounded, whilst others are unbounded.
- Wait, What? Everything is a Stream?
- From my background with Apache Kafka and the stream-table duality, this source-agnostic framing of events is different, and I can’t wait to explore it further. I’m interested to see if it’s just a matter of semantics, or if there is something fundamentally different in how Flink reasons about streams of events vs state for given keys.
Uses & Users of Flink 🔗
Use Cases 🔗
The documentation for Flink lays out three distinct use cases for Flink. Under each are linked several examples, mostly from the Flink Forward conference.
- Event-driven Applications, e.g.
- Data Analytics Applications, e.g.
- Quality monitoring of Telco networks
- Analysis of product updates & experiment evaluation
- Ad-hoc analysis of live data
- Large-scale graph analysis
- Data Pipeline Applications, e.g.
- Real-time search index building
- Continuous ETL (a.k.a. “Streaming ETL”)
One thing that’s interesting about the linked examples is that they are all from 6-7 years ago. One can look at this two ways. Put positively, it demonstrates what a long history and proof of success Flink has when it comes to experience in stream processing. Being snarky, one would cast it in the light that Flink is a technology of the past, on its way out with the Hadoops of this world.
I’d strongly reject the latter view. You may say that is obvious given that I now work for a company offering a managed Flink service 😉. But this in itself is a point to counter the snark. There are multiple companies launching Flink as a service—including companies which already had stream processing offerings based on other technology. Flink is a well-established technology with a strong roadmap and a modern and cloud-native vision for its future direction.
Users of Flink 🔗
Whilst the rise of managed Flink services is one proof-point demonstrating Flink’s popularity, the other irrefutable one is its continued use in a wide range of companies and use cases (and not just those from 6-7 years ago). A quick look through the back issues of Data Engineering Weekly and past sessions of Flink Forward and other conferences demonstrates this.
Users with recent (in the last ~two years) published use cases include:
- Alibaba Cloud
- Amazon
- Apple
- Booking.com
- Capital One
- DoorDash
- ING Bank
- Instacart
- JP MorganChase
- Lyft
- Netflix (ad infinitum)
- Pintrest (this older article lists more of their use cases)
- Shopify
- Stripe
- TikTok
- Uber
- Vinted
See also the Powered By Flink highlights and complete list.
“What Can Flink Do” vs “Where Will You Find Flink” 🔗
After I posted the first draft of this post, my colleague (and Apache Flink PMC Chair!) Robert Metzger shared this useful slide with me.
I like this because it spells out what Flink does (e.g. Windowing, Streaming Joins, Filtering, etc), and separately, where it gets used for that.
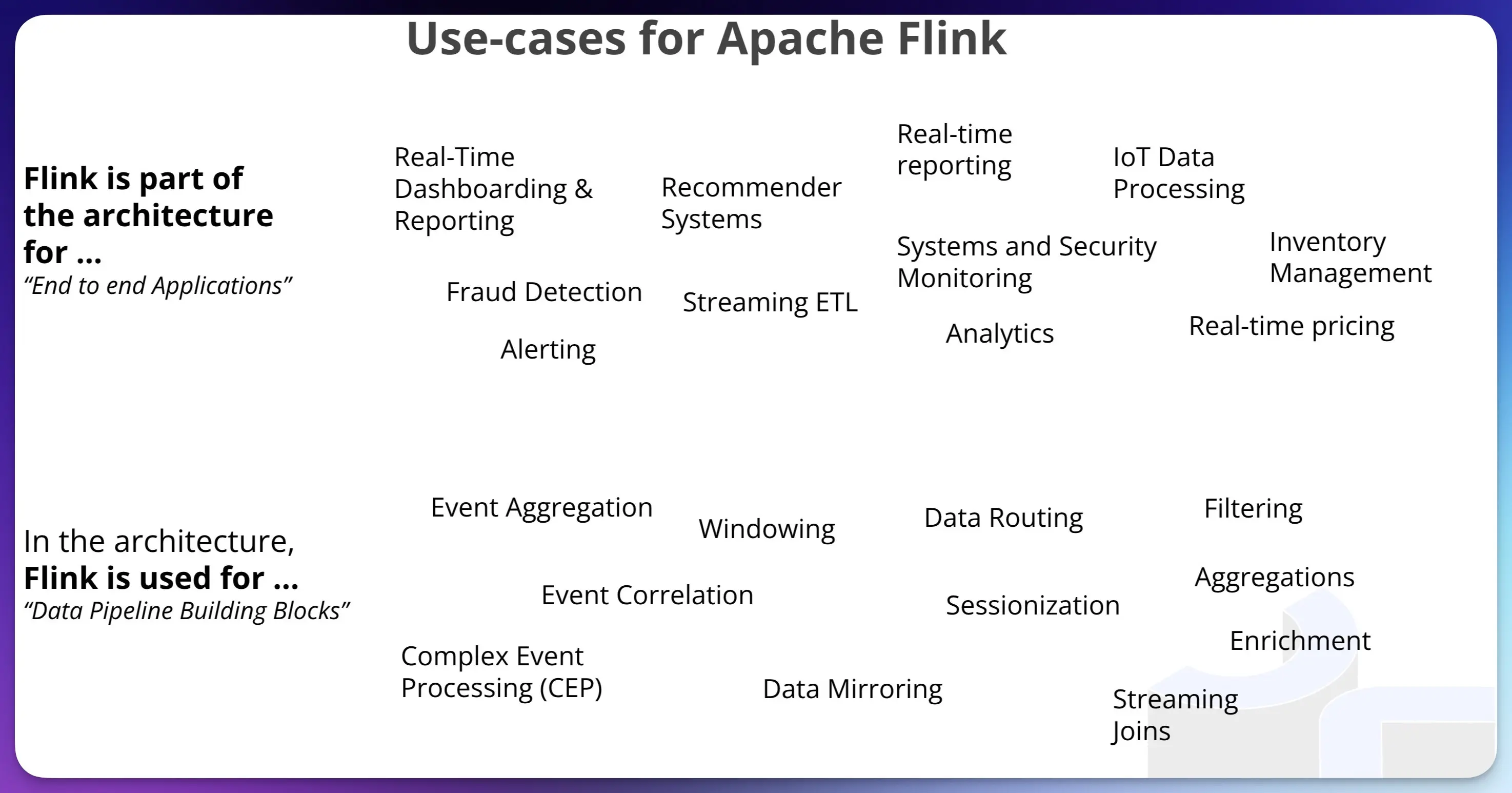
How do you run Flink? 🔗
Self-Managed 🔗
Flink is a distributed system, which means that you don’t just buy one great big box and scale it up and up for capacity. Instead, you deploy it across multiple instances for both scalability and fault-tolerance.
The Flink documentation has a clear set of instructions for running Flink using the binaries directly, under Docker, and with Kubernetes. Betraying its Big Data history, is also still supports YARN.
Managed Service 🔗
Did I mention yet that Decodable offers a fully-managed Apache Flink service? :-D
You can find a list of other vendors that offer Apache Flink as a managed service in the Flink documentation.
The Flink Community 🔗
Just like any healthy open-source project, there is a good community around Flink. Per the Apache motto:
If it didn’t happen on a mailing list, it didn’t happen.
The community page on the Flink site lists numerous mailing lists. news@ and community@ are both pretty stagnant, but users@ is well-used with half a dozen posts per day. If you’re contributing to Flink (rather than just using it) you’ll want the dev@ list too.
Alongside the mailing lists, there is a Slack group with 3k members. It has a good layout of channels, and a handful of messages per day
You’ll also find a steady stream of Flink questions and answers on StackOverflow.
What’s next for Flink? 🔗
There’s a comprehensive and well-maintained roadmap for Flink. Changes are made through FLIPs (FLink Improvement Proposals).
As well as what’s coming there’s also a clear list of features that are being phased out. This level of insight into the project is really useful for a newbie—given how long Flink has been around (aeons, in internet years) there is going to be a lot of material published that is out of date and this chart will hopefully be a quick way to navigate that.
The roadmap page is notable for not only a list of planned features but also the general strategy (which should help inform users as to whether their use cases are within sensible bounds) and even something close to my own heart: developer experience. One particularly interesting bit that caught my eye is the idea of built-in dynamic table storage, described in FLIP-188 and—if I understand correctly—spun out into its own Apache Incubator project, Apache Paimon. Paimon describes itself as a “Streaming data lake platform” and is definitely on my list to go and check out particularly after my work last year on mapping out the data engineering landscape as at first glance I’m not sure where it fits.
Flink Resources 🔗
The Apache Flink project website itself is an excellent resource. Especially when compared to some other Apache projects (cough), it’s extremely well laid out, thoughtfully organised, and easy to use.
Some other good places for Flink information include:
- The Flink Forward conference (previous events)
- Podcasts
- Apache Flink presentations on SpeakerDeck