
As a newcomer to Apache Flink one of the first things I did was join the Slack community (which is vendor-neutral and controlled by the Flink PMC). At the moment I’m pretty much in full-time lurker mode, soaking up the kind of questions that people have and how they’re using Flink.
One question that caught my eye was from Marco Villalobos, in which he asked about the Flink JDBC driver and a SQLDataException he was getting with a particular datatype. Now, unfortunately, I have no idea about the answer to this question—but the idea of a JDBC driver through which Flink SQL could be run sounded like a fascinating path to follow after previously looking at the SQL Client.
This took me down a bit of a rabbit hole, because after digging through the docs my understanding is that there are two options if you have a client that you want to connect to Flink using JDBC

At this point in time (and I would love to be corrected if I’m wrong!) my understanding is this:
tl;dr: If all you want to do is quickly hook up a JDBC client to Flink, then the Flink JDBC driver is the route to go—if you’re not bothered about a catalog to persist metadata. In either case, you also need to be running the SQL Gateway.
What are the JDBC options with Flink? 🔗
The docs don’t particularly help with this confusion, instead having two seemingly unconnected examples both with JDBC, and each using the SQL Gateway.
Looking at the history of the project brings to light how these pages have probably evolved.
-
A new Flink JDBC Driver was added in 1.18 (FLIP-293) and uses the SQL Gateway’s REST interface.
A JDBC driver and SQL gateway existed before as community projects which had fallen out of maintenance and were written for older versions of Flink. The SQL Gateway had previously been brought into Flink in FLIP-91.
-
The other JDBC route is through the Hive JDBC Driver which can be used in conjunction with the HiveServer2 support which was added to the SQL Gateway last year in Flink 1.16 with FLIP-223.
The motivation around adding HiveServer2 was the assertion that Hive is still the de-facto interface for those doing batch processing in the “Big Data” world.
Catalogs and Metadata… 🔗
In looking at the requirements for using HiveServer2 (via the original page’s Setup section) I got scared off ;-)
I suspect at some point I will have to bite this bullet because Flink itself doesn’t have its own metadata store, and per the docs:
HiveCatalog is the only persistent catalog provided out-of-box by Flink.
When we talk about catalogs and persisting metadata we’re talking about the tables and other objects that we define being there the next time we connect to the system. For transient processing, and indeed for sandbox and experimentation purposes, this might not be an issue. But this is something so fundamental that for something like an RDBMS that we wouldn’t even think to check that it does it - we just assume that whether MySQL, Oracle, or whatever, when we create a table it will of course be there next time we connect to the server.
So all that said, we’re going to just use the Flink JDBC Driver for now, and save the HiveServer2 endpoint of the SQL Gateway for another day.
Hands-on with the Flink JDBC Driver 🔗
My favourite way to learn something is by actually trying it out. The first step is to run the Flink cluster:
$ ./bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host asgard08.
Starting taskexecutor daemon on host asgard08.
and then the SQL Gateway:
$ ./bin/sql-gateway.sh start -Dsql-gateway.endpoint.rest.address=localhost
Starting sql-gateway daemon on host asgard08.
The SQL Gateway exposes two endpoints: REST (default) and HiveServer2 . Let’s use the REST endpoint to check that it’s working:
$ curl http://localhost:8083/v1/info
{"productName":"Apache Flink","version":"1.18.0"}%
Now we’ll use the JDBC driver, through the SQL gateway, from a suitable client. The JDBC driver isn’t bundled with Flink itself so you need to download it:
$ curl https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-jdbc-driver-bundle/1.18.0/flink-sql-jdbc-driver-bundle-1.18.0.jar -O
Now to choose our JDBC client.
❌ Attempt 1: jisql 🔗
Many years ago and in a different life I used jisql, so that was my first choice here simply for familiarity.
After cloning the jisql repo and building it (mvn package) I copied the Flink JDBC driver to the target folder that the build created.
$ ls -l *.jar
-rw-r--r--@ 1 rmoff staff 22258619 13 Nov 11:54 flink-sql-jdbc-driver-bundle-1.18.0.jar
-rw-r--r--@ 1 rmoff staff 86883 13 Nov 10:41 jisql-jar-with-dependencies.jar
-rw-r--r--@ 1 rmoff staff 19917 13 Nov 10:40 jisql.jar
Now to run it:
java -cp "$PWD/*" \
com.xigole.util.sql.Jisql \
-driver org.apache.flink.table.jdbc.FlinkDriver \
-cstring jdbc:flink://localhost:8083 \
-user none -password none -driverinfo
How I love the smell of Java stack traces in the morning 🙄
Exception in thread "main" java.lang.NoClassDefFoundError: org/slf4j/LoggerFactory
at org.apache.flink.table.jdbc.FlinkDriver.<clinit>(FlinkDriver.java:40)
at java.base/java.lang.Class.forName0(Native Method)
at java.base/java.lang.Class.forName(Class.java:315)
at com.xigole.util.sql.Jisql.run(Jisql.java:288)
at com.xigole.util.sql.Jisql.main(Jisql.java:275)
Caused by: java.lang.ClassNotFoundException: org.slf4j.LoggerFactory
at java.base/jdk.internal.loader.BuiltinClassLoader.loadClass(BuiltinClassLoader.java:581)
at java.base/jdk.internal.loader.ClassLoaders$AppClassLoader.loadClass(ClassLoaders.java:178)
at java.base/java.lang.ClassLoader.loadClass(ClassLoader.java:527)
... 5 more
One of the challenges for non-Java users of Flink (like me) is navigating these stacktraces which pop up even when you’re using the SQL side of things. From bitter experience, I know that NoClassDefFoundError means I’m probably missing a jar, or have a jar but in the wrong place, or the wrong colour, or something.
There’s also a line in the docs that I missed the first time around:
Notice that you need to copy slf4j-api-{slf4j.version}.jar to
targetwhich will be used by flink JDBC driver
This jar is for the SLF4J API Module. It’s beyond my pay grade to explain why this isn’t included with the Flink JDBC driver, so for now we’ll deal with the sharp edge and just go and download that too.
$ curl https://repo1.maven.org/maven2/org/slf4j/slf4j-api/2.0.9/slf4j-api-2.0.9.jar -O
$ cp slf4j-api-2.0.9.jar target
$ ls -l *.jar
-rw-r--r--@ 1 rmoff staff 22258619 13 Nov 11:54 flink-sql-jdbc-driver-bundle-1.18.0.jar
-rw-r--r--@ 1 rmoff staff 86883 13 Nov 10:41 jisql-jar-with-dependencies.jar
-rw-r--r--@ 1 rmoff staff 19917 13 Nov 10:40 jisql.jar
-rw-r--r--@ 1 rmoff staff 64579 13 Nov 11:54 slf4j-api-2.0.9.jar
Trying again:
$ java -cp "$PWD/*" \
com.xigole.util.sql.Jisql \
-driver org.apache.flink.table.jdbc.FlinkDriver \
-cstring jdbc:flink://localhost:8083 \
-user none -password none \
-driverinfo
[…]
driver.getMajorVersion() is 1
driver.getMinorVersion() is 18
driver is not JDBC compliant
metaData.getDatabaseProductName(): "Flink JDBC Driver"
metaData.getDatabaseProductVersion(): "1.18.0"
metaData.getDriverName(): "org.apache.flink.table.jdbc.FlinkDriver"
metaData.getDriverVersion(): "1.18.0"
Nice, we’re getting somewhere! Unfortunately, this is as far as we get. If we remove the -driverinfo flag (which gave us the driver info as seen above) so that we can get into the SQL prompt itself, we hit a problem:
$ java -cp "$PWD/*" \
com.xigole.util.sql.Jisql \
-driver org.apache.flink.table.jdbc.FlinkDriver \
-cstring jdbc:flink://localhost:8083 \
-user none -password none
SLF4J: No SLF4J providers were found.
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See https://www.slf4j.org/codes.html#noProviders for further details.
SQLException : SQL state: null java.sql.SQLFeatureNotSupportedException: FlinkConnection#clearWarnings is not supported yet. ErrorCode: 0
SQLFeatureNotSupportedException is a recurred theme with the Flink JDBC Driver. In this case, it’s clearWarnings that isn’t supported.
Even if I go into the code and comment out the call to clearWarnings and rebuild jisql (look at me delving into Java code which I have no idea about what I’m doing! 🤪), it soon bombs out on further SQLFeatureNotSupportedException errors.
✅ Attempt 2: sqlline 🔗
The docs themselves demonstrate the JDBC Driver with sqlline so I was hoping that this would at least work.
As before, I cloned the repo and built it (./mvnw package -DskipTests - one of the tests seems to be broken, hence skipping it). Learning from my lesson before I put both the Flink JDBC driver and slf4j jars in the same folder as the sqlline jar:
$ ls -l target/*.jar
-rw-r--r--@ 1 rmoff staff 22258619 13 Nov 11:06 flink-sql-jdbc-driver-bundle-1.18.0.jar
-rw-r--r--@ 1 rmoff staff 64579 13 Nov 11:11 slf4j-api-2.0.9.jar
-rw-r--r--@ 1 rmoff staff 3128007 13 Nov 10:54 sqlline-1.13.0-SNAPSHOT-jar-with-dependencies.jar
-rw-r--r--@ 1 rmoff staff 505697 13 Nov 10:54 sqlline-1.13.0-SNAPSHOT-javadoc.jar
-rw-r--r--@ 1 rmoff staff 151338 13 Nov 10:54 sqlline-1.13.0-SNAPSHOT-sources.jar
-rw-r--r--@ 1 rmoff staff 243014 13 Nov 10:54 sqlline-1.13.0-SNAPSHOT.jar
Now to run it. There are two options - the helper shell script that ships with sqlline and sets up the classpath nicely, or just directly like with jisql above. I opted for the former since it’s tidier on the CLI:
$ ./bin/sqlline
sqlline version 1.13.0-SNAPSHOT
sqlline>
So far, so good.
Let’s connect to the Flink cluster using the gateway’s REST endpoint using the connect command and JDBC URL:
sqlline> !connect jdbc:flink://localhost:8083
[…]
We’re prompted for credentials, even though the driver doesn’t support them at this stage. Hit return for both, ignore the is not supported yet errors, and we’re now at a prompt from which we can enter some Flink SQL!
Enter username for jdbc:flink://localhost:8083:
Enter password for jdbc:flink://localhost:8083:
Error: FlinkConnection#setReadOnly is not supported yet. (state=,code=0)
Error: FlinkDatabaseMetaData#getDefaultTransactionIsolation is not supported (state=,code=0)
0: jdbc:flink://localhost:8083>
Let’s run a query using the same example as last time:
0: jdbc:flink://localhost:8083> SELECT
. . . . . . . . . . .semicolon> name,
. . . . . . . . . . .semicolon> COUNT(*) AS cnt
. . . . . . . . . . .semicolon> FROM
. . . . . . . . . . .semicolon> (VALUES ('Bob'), ('Alice'), ('Greg'), ('Bob')) AS NameTable(name)
. . . . . . . . . . .semicolon> GROUP BY name;
+-------+-----+
| name | cnt |
+-------+-----+
| Bob | 1 |
| Alice | 1 |
| Greg | 1 |
| Bob | 1 |
| Bob | 2 |
+-------+-----+
5 rows selected (1.044 seconds)
What about streaming? We’ll create a table using the datagen connector. This connector basically stuffs random values into each field to match the respective data type.
0: jdbc:flink://localhost:8083> CREATE TABLE foo (
. . . . . . . . . . . . . . .)> a_number BIGINT,
. . . . . . . . . . . . . . .)> a_decimal DECIMAL(32,2),
. . . . . . . . . . . . . . .)> a_string STRING
. . . . . . . . . . . . . . .)> ) WITH (
. . . . . . . . . . . . . . .)> 'connector' = 'datagen'
. . . . . . . . . . . . . . .)> );
No rows affected (0.145 seconds)
It’s not pretty, but it is effective. Here’s a bounded query against the table:
0: jdbc:flink://localhost:8083> SELECT * FROM foo LIMIT 5;
+----------------------+-----------------------------------+------------------------------------------------------------------------------------------------------+
| a_number | a_decimal | a_string |
+----------------------+-----------------------------------+------------------------------------------------------------------------------------------------------+
| 5498399883014354114 | 74212271515046392498116100096.00 | 702e6aa4b8c69d6fdd67ec90fcf90253377357b250e74d40934ab25cd6aa0c631309f49789b80678a522379b1ad3861187af |
| -3618213315685925891 | 93385166264069454971029946368.00 | 4e1ec64676a13eacb7d58757492c1ea3c0c77138dbdedca63827d516cd7849aa1c73fa714fb8d07d98e18c3a20a42ce24c53 |
| 9058675481861391925 | 651238545085586500000000000000.00 | b81f3859c94f37088821df93d2e5284ab0778b49d4c89729a45ef82634a8f1c7313224f1dca03e437653a563b93c15841c1e |
| -607555464239338146 | 214827744726156960000000000000.00 | a15acba4276bcbb2b0846599d79c44fd23a22acc178f0c76abdc951c793149bd2735b734ccbc1f4b65c1294f09cb84cc153b |
| -2603485567200316583 | 413883713557198900000000000000.00 | 7266d08ef4fa9f84677ce01d536475e798f1218fdf63fdb174f7ce07e0511c6511f0d981ddc6a3d08b8e7a1fd5c01304d673 |
+----------------------+-----------------------------------+------------------------------------------------------------------------------------------------------+
5 rows selected (0.832 seconds)
Without the LIMIT clause, it’s unbounded:
One of the issues with using the JDBC Driver is that there is extreme verbosity. This might be from the REST endpoint rather than the JDBC driver itself (I’m not sure) but either way, the user is left with a screenful of noise if they try to do something that causes a problem. For example, if you tell Flink to run as a batch job:
SET execution.runtime-mode=batch;
and then run a SELECT against the above foo table (which is defined as an unbounded source) you get a sensible and well-formed error:
org.apache.flink.table.api.ValidationException:
Querying an unbounded table 'default_catalog.default_database.foo' in batch mode is not allowed.
The table source is unbounded.
However, this error is buried amongst vast stacktrace noise. Here’s what the above one error looks like—I had to zoom my font size right down to even get all the messages on the viewable screen:

As a side note—since we’ve gone down this bounded/unbounded batch/streaming path—you can also use datagen as a bounded source by setting the number-of-rows option in the DDL:
CREATE TABLE bar (
c1 INT,
c2 STRING
) WITH (
'connector' = 'datagen',
'number-of-rows' = '8'
);
0: jdbc:flink://localhost:8083> SELECT * FROM bar;
+-------------+------------------------------------------------------------------------------------------------------+
| c1 | c2 |
+-------------+------------------------------------------------------------------------------------------------------+
| -596725830 | e2286a4c7200d165502c49d58793f3867ec3462b75c029d0552f0475c36e95aff2cedd17e7c2fd0e12dfc90f4ca561513eaf |
| 288846669 | f39a0c31abd89ff15841d2875fd6669bb88e31357bdcf75a4d67c3d4aa67283497800fe820881a3bac6fbaddcce301d916b7 |
| -1278589269 | ad9f5d238476c34dfaf4c60f42e1a1a38f64201f93ad5e9d59ea3831fdf1fcf47240820e437aa3db280917c4740169773558 |
| -2001314692 | 8aefa715dbb1cfabf4705b5e89263b95e09953605663861c0dba79b566b24f17f0f7e43f51f4192120c8e85c06922cf24b41 |
| 523937178 | 66e5a9e560b0014bdbb3393f660c6ad9cd5ddb098eef205ebfc13ffc819b50d31809bb1ebf2356d5943ec2f1b395b3c78fc0 |
| 445642724 | 7311f7970f709ccbb724bf7386cf3baed4c6957d54fb4625f4a2f6fa958cf58617c812eb1cd4373e809234e5704e2141364f |
| 2038995175 | 0ef84598989c488bda2a75d3138ec3cd08f7449b06a1b8321a63e46009f5dcea27e158023a2dabc6851c379f06cdad9e93f6 |
| -2071526857 | 2b0152d3da610caad8c7256e2e410b55979bde72c34f918ccd53f438f5ca5104d996db448e41edff536ba01f5664472e52c8 |
+-------------+------------------------------------------------------------------------------------------------------+
8 rows selected (0.813 seconds)
🦫 DBeaver 🔗
A popular open-source GUI for databases (and more) is DBeaver. You can already use it with Flink through the HiveServer2 support in SQL Gateway, and the Flink JDBC Driver means it can natively support it.
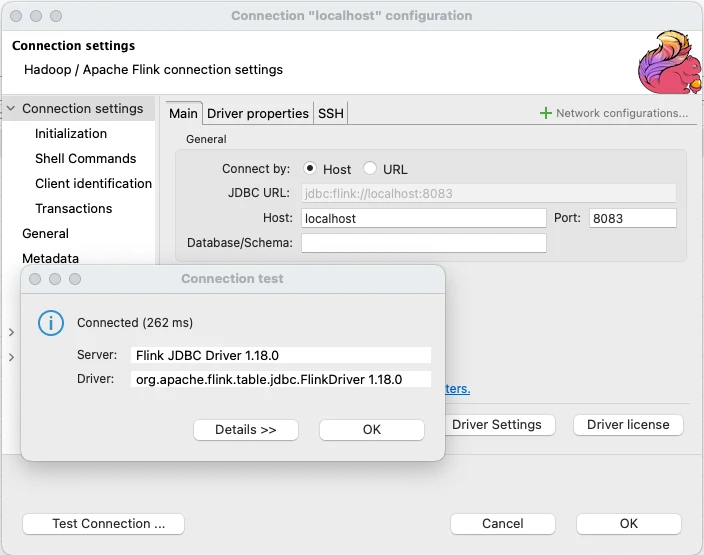
Just like with sqlline, you can run Flink SQL statements to create and query tables. DBeaver seems happy querying both bounded tables:
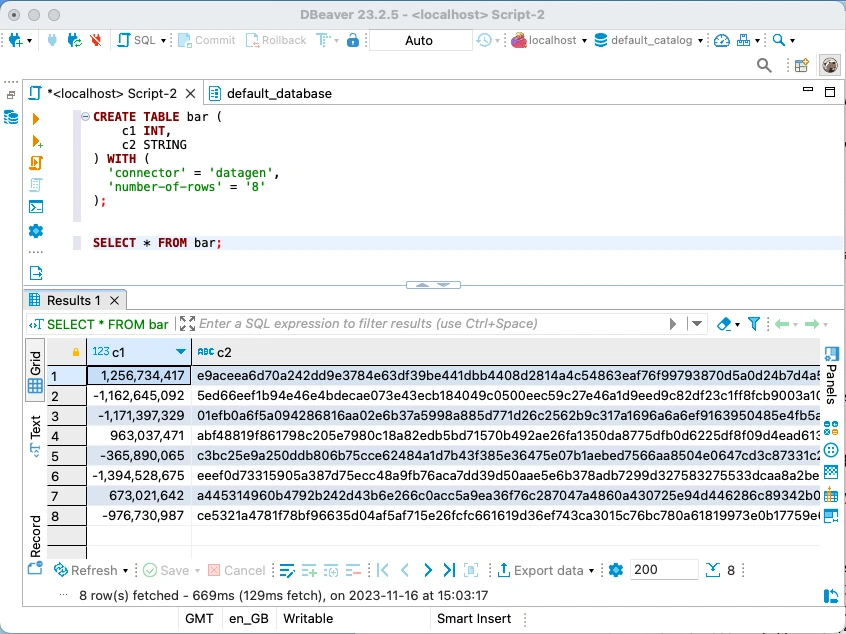
as well as unbounded:
In the case of the unbounded table, it’s hard to tell because of the random nature of datagen’s data whether what I’m seeing is results from one query paged into 200-row chunks, or if each time it goes to get more data it’s the first 200 rows of a new result set that’s shown.
You can add Flink JDBC to DBeaver yourself by modifying plugins/org.jkiss.dbeaver.ext.generic/plugin.xml and rebuilding it (which isn’t as scary as it sounds; it’s documented and just watch out for this issue). I’ve submitted a PR so hopefully by the time you read this it might even be in the downloadable version of the tool :)