In my last post I wrote all about watermarks in Apache Flink. As you’ll have realised—or been aware of already—it can get fairly hairy. That’s why I’m keen to see how Confluent Cloud for Apache Flink deals with watermarks, to see if it makes life any easier for the developer.
As a quick recap, watermarks in Flink are used to mark the latest point in time for which data can be considered to be complete. Without a watermark, Flink won’t issue the results of temporal queries, which includes windowed aggregations and joins.
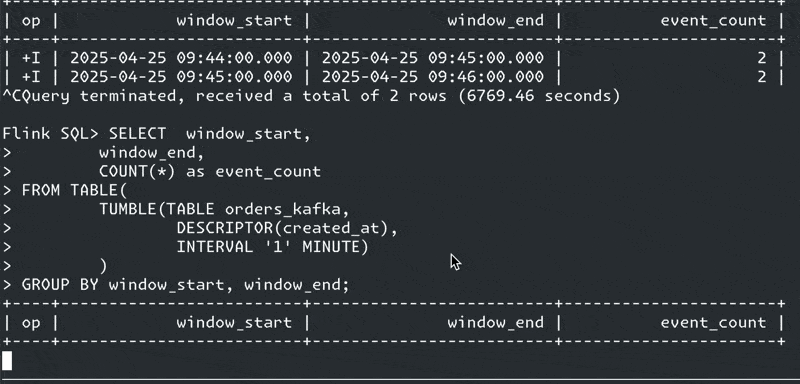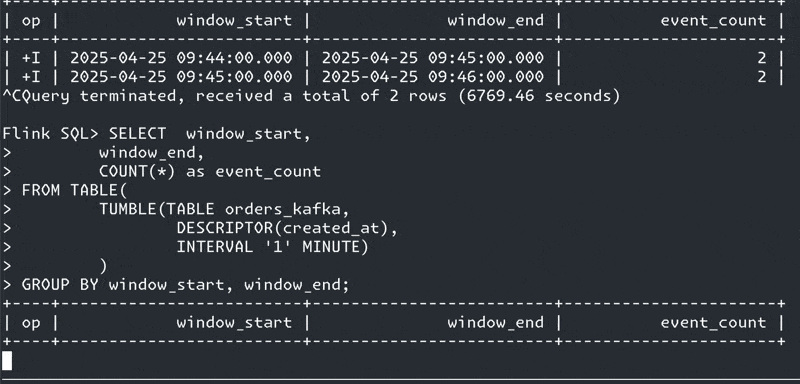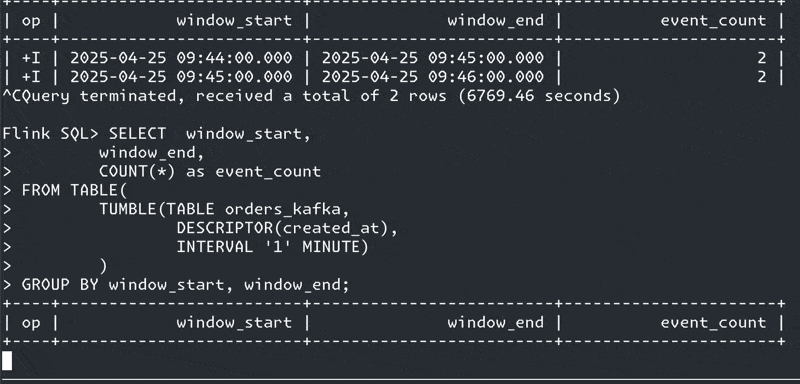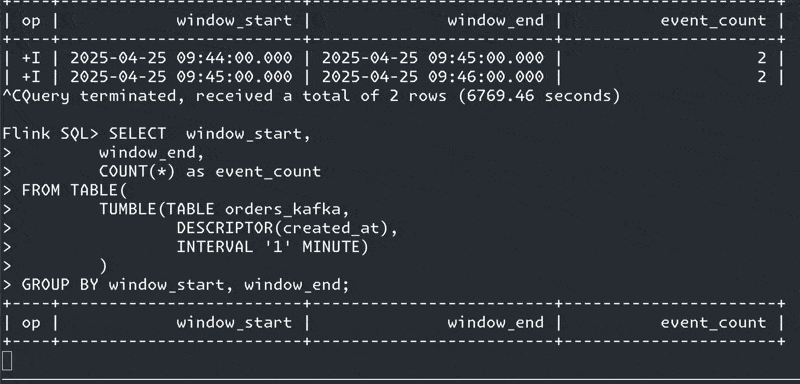
If you’re sat starting at a screen that looks like this yet have data flowing into the source table, watermarks are often your problem:
On Confluent Cloud for Apache Flink watermarks are handled differently. Let’s see how!
| If you’re not familiar with how watermarks work in Apache Flink, please do go back over my previous article. You’ll also find a lot of good content on Confluent Developer, including these videos from David Anderson and Wade Waldron. In this post I’m going to go straight into the detail, talking about things like event time and idle partitions and watermark strategy. |
Quick recap: What’s a watermark strategy? 🔗
A Flink watermark strategy defines when a watermark is generated, and the strategy of what value for the watermark is generated.
-
What value is defined by the
WATERMARKDDL on a table. For example:WATERMARK FOR `created_at` AS `created_at` - INTERVAL '5' SECONDThis is what is often referred to as the watermark generation strategy. Here the value of the watermark will be whatever
created_atis, minus five seconds.It is important to put in place because without it Flink won’t treat the column against which its defined as an event time attribute.
-
When a watermark is generated (or "emitted") based on the watermark emit strategy configuration, which can be set as a property for the table or as a query hint.
The Data 🔗
I’ve populated a topic using the Postgres CDC connector on Confluent Cloud, streaming records into a topic called pg.public.orders.
Here’s the first record in the topic:
kcat -q -b $CNFL_KAFKA_BROKER \
-X security.protocol=sasl_ssl -X sasl.mechanisms=PLAIN \
-X sasl.username=$CNFL_KC_API_KEY -X sasl.password=$CNFL_KC_API_SECRET \
-s avro -r https://$CNFL_SR_API_KEY:$CNFL_SR_API_SECRET@$CNFL_SR_HOST \
-C -t pg.public.orders -c1 -f '\nKey (%K bytes): %k
Value (%S bytes): %s
Timestamp: %T
Partition: %p
Offset: %o
Headers: %h\n'Key (6 bytes): {"order_id": 1}
Value (76 bytes): {
"order_id": 1,
"customer_id": 1001,
"total_amount": ":\u0097",
"status": "pending",
"created_at": {
"long": 1745574265000000
},
"shipped_at": null,
"shipping_address": {
"string": "221B Baker Street, London"
},
"payment_method": {
"string": "Credit Card"
},
"__deleted": {
"string": "false"
}
}
Timestamp: 1746012695220
Partition: 0
Offset: 0
Headers:From this we can see we’ve got three possible timestamps to work with:
|
|
Represents the time at which an event (placing an order) happened. |
|
null |
Represents the time at which an event (shipping an order) happened. |
|
|
Ingest time of the record into the Kafka topic. |
The query 🔗
We’re going to create a windowed aggregation to calculate how many orders were created per minute. Let’s fire up Confluent Cloud for Apache Flink and see what happens.
The aggregation is a straightforward one—it’s a COUNT over a tumbling window, which we implement using a Table-Valued Function (TVF).
Before we run the query we need to figure out watermarks.
Confluent Cloud for Apache Flink implements a default watermarking strategy based on the $rowtime column (mapped to the Kafka message timestamp).
However, in our query we want to aggregate based on created_at (when the Order record was created, set by the source application)—not the Kafka message timestamp (which could be very different from when the order was placed, depending on how we’re getting the data into Kafka and various latencies along the way).
Since there is a default, changing the watermark strategy in Confluent Cloud for Apache Flink is known as creating a custom watermark strategy.
If we don’t do this then the aggregation based on created_at will fail with the error The window function requires the timecol is a time attribute type.
Setting a custom watermark strategy is done by using running some ALTER TABLE…MODIFY WATERMARK DDL:
ALTER TABLE `rmoff`.`cluster00`.`pg0.public.orders`
MODIFY WATERMARK FOR `created_at` AS `created_at` - INTERVAL '5' SECOND;Now we can run the query:
SELECT window_start,
window_end,
COUNT(*) as event_count
FROM TABLE(
TUMBLE(TABLE `rmoff`.`cluster00`.`pg0.public.orders`,
DESCRIPTOR(created_at),
INTERVAL '1' MINUTE)
)
GROUP BY window_start,
window_end;and get a windowed aggregation result :)
╔═══════════════════════════════════════════════════════════╗
║window_start window_end event_count║
║2025-04-25 10:44:00.000 2025-04-25 10:45:00.000 2 ║The rest of the watermark behaviour is the same as when I dug into it using Apache Flink. The results above show two events in the window 10:44-10:45—but what about the rest of my data? Let’s look at the table data:
╔════════════════════════════════════════════════════════════════════╗
║order_id customer_id total_amount status created_at ║
║1 1001 149.99 pending 2025-04-25 10:44:25.000║
║2 1003 199.50 pending 2025-04-25 10:44:28.000║
║3 1005 42.00 delivered 2025-04-25 10:45:33.000║
║4 1002 89.95 processing 2025-04-25 10:45:38.000║
║5 1004 125.50 delivered 2025-04-25 10:46:03.000║Eyeballing this we can see three windows:
-
10:44-10:45 (2 events)
-
10:45-10:46 (2 events)
-
10:46-10:47 (1 events)
So why is the query only emitting one of these windows?
Because the watermark strategy says to generate a watermark five seconds behind the value of created_at:
WATERMARK FOR `created_at` AS `created_at` - INTERVAL '5' SECOND;Let’s do that calculation looking at the table data, and we’ll see the problem:
SELECT order_id, created_at, created_at - INTERVAL '5' SECOND AS expected_watermark
FROM `pg0.public.orders`;╔═══════════════════════════════════════════════════════════╗
║order_id created_at expected_watermark ║
║1 2025-04-25 10:44:25.000 2025-04-25 10:44:20.000 ║
║2 2025-04-25 10:44:28.000 2025-04-25 10:44:23.000 ║
║3 2025-04-25 10:45:33.000 2025-04-25 10:45:28.000 ║
║4 2025-04-25 10:45:38.000 2025-04-25 10:45:33.000 ║
║5 2025-04-25 10:46:03.000 2025-04-25 10:45:58.000 ║Note that expected_watermark only goes up to 10:45:58, meaning that Flink does not yet consider the window ending at 10:46 has closed yet.
If we add another row of data to the table:
╔═══════════════════════════════════════════════════════════╗
║order_id created_at expected_watermark ║
║1 2025-04-25 10:44:25.000 2025-04-25 10:44:20.000 ║
║2 2025-04-25 10:44:28.000 2025-04-25 10:44:23.000 ║
║3 2025-04-25 10:45:33.000 2025-04-25 10:45:28.000 ║
║4 2025-04-25 10:45:38.000 2025-04-25 10:45:33.000 ║
║5 2025-04-25 10:46:03.000 2025-04-25 10:45:58.000 ║
║6 2025-04-25 10:46:51.000 2025-04-25 10:46:46.000 ║The created_at of 10:46:51 pushes the watermark forward to 10:46:46, thus meaning that Flink can close the previous window, and we get our result:
╔═══════════════════════════════════════════════════════════╗
║window_start window_end event_count║
║2025-04-25 10:44:00.000 2025-04-25 10:45:00.000 2 ║
║2025-04-25 10:45:00.000 2025-04-25 10:46:00.000 2 ║