
Without wanting to mix my temperature metaphors, Iceberg is the new hawtness, and getting data into it from other places is a common task. I wrote previously about using Flink SQL to do this, and today I’m going to look at doing the same using Kafka Connect.
Kafka Connect can send data to Iceberg from any Kafka topic. The source Kafka topic(s) can be populated by a Kafka Connect source connector (such as Debezium), or a regular application producing directly to it.
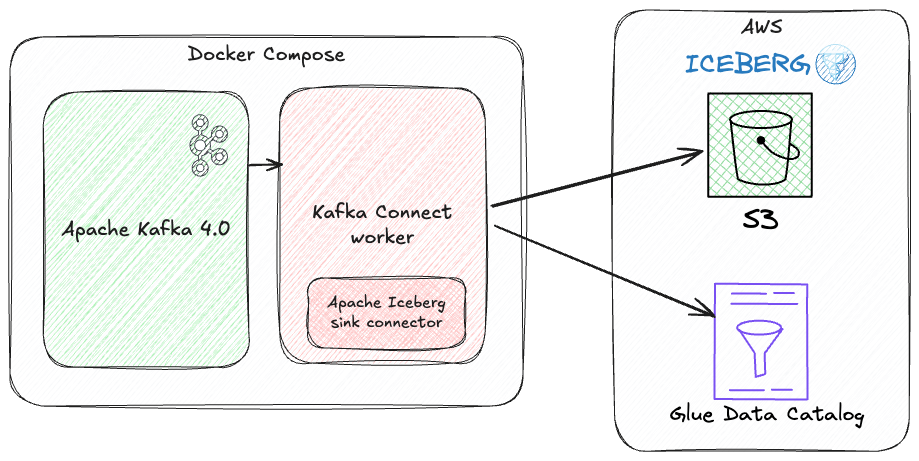
I’m going to use AWS’s Glue Data Catalog, but the sink also works with other Iceberg catalogs.
| You can find the Docker Compose for this article here |
Kafka Connect and the Iceberg Sink Connector 🔗
Kafka Connect is a framework for data integration, and is part of Apache Kafka. There is a rich ecosystem of connectors for getting data in and out of Kafka, and Kafka Connect itself provides a set of features that you’d expect for a resilient data integration platform, including scaling, schema handling, restarts, serialisation, and more.
The Apache Iceberg connector for Kafka Connect was originally created by folk at Tabular and has subsequently been contributed to the Apache Iceberg project (via a brief stint on a Databricks repo following the Tabular acquisition).
For the purposes of this blog I’m still using the Tabular version since it has a pre-built binary available on Confluent Hub which makes it easier to install.
If you want to use the Apache Iceberg version you currently https://iceberg.apache.org/docs/nightly/kafka-connect/#installation[need to build the connector yourself].
There is https://github.com/apache/iceberg/issues/10745[work underway] to make it available on Confluent Hub.
Confluent Hub now hosts the Apache Iceberg version of the connector.
I’m running a Kafka Connect Docker image provided by Confluent because it provides the confluent-hub CLI tool which is a handy way for installing pre-built connectors and saves me having to do it myself.
It’s worth noting that the confluent-hub CLI is being deprecated in favour of the broader confluent CLI tool and confluent connect plugin install to install connectors.
$ confluent-hub install --no-prompt tabular/iceberg-kafka-connect:0.6.19|
If you’re using Docker you can bake this in at runtime like this. |
Let’s check that the connector is installed.
We can use the Kafka Connect REST API for this and the /connector-plugins endpoint:
$ curl -s localhost:8083/connector-plugins|jq '.[].class'
"io.tabular.iceberg.connect.IcebergSinkConnector"
"org.apache.kafka.connect.mirror.MirrorCheckpointConnector"
"org.apache.kafka.connect.mirror.MirrorHeartbeatConnector"
"org.apache.kafka.connect.mirror.MirrorSourceConnector"(Note that it’s io.tabular and not org.apache, since we’re using the Tabular version of the connector for now).
kcctl 🧸 🔗
REST APIs are all very well, but a nicer way of managing Kafka Connect is kcctl.
This is a CLI client built for Kafka Connect.
On the Mac it’s a simple install from Brew: brew install kcctl/tap/kcctl
Once you’ve installed kcctl, configure it to point to the Kafka Connect worker cluster:
$ kcctl config set-context local --cluster http://localhost:8083Now we can easily inspect the cluster:
$ kcctl info
URL: http://localhost:8083
Version: 8.0.0-ccs
Commit: 42dc8a94fe8a158bfc3241b5a93a1adde9973507
Kafka Cluster ID: 5L6g3nShT-eMCtK--X86swWe can also look at the sink connectors installed (which is a subset of those shown above):
$ kcctl get plugins --types=sink
TYPE CLASS VERSION
sink io.tabular.iceberg.connect.IcebergSinkConnector 1.5.2-kc-0.6.191:1 (Sending data from one Kafka topic to an Iceberg table) 🔗
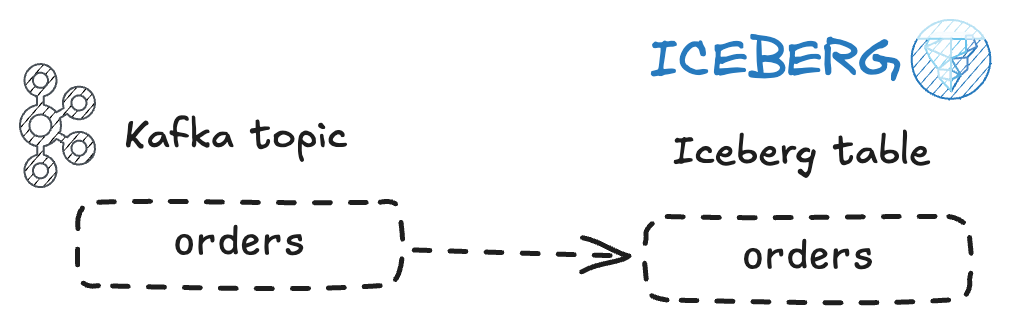
We’ll start by looking at the most simple example, sending data from a Kafka topic to a table in Iceberg.
I’m going to populate a Kafka topic with some dummy data. I’m using JSON to serialise it; bear in mind that an explicitly-declared schema stored in a Schema Registry and the data serialised with something like Avro is often a better approach.
$ echo '{"order_id": "001", "customer_id": "cust_123", "product": "laptop", "quantity": 1, "price": 999.99}
{"order_id": "002", "customer_id": "cust_456", "product": "mouse", "quantity": 2, "price": 25.50}
{"order_id": "003", "customer_id": "cust_789", "product": "keyboard", "quantity": 1, "price": 75.00}
{"order_id": "004", "customer_id": "cust_321", "product": "monitor", "quantity": 1, "price": 299.99}
{"order_id": "005", "customer_id": "cust_654", "product": "headphones", "quantity": 1, "price": 149.99}' | docker compose exec -T kcat kcat -P -b broker:9092 -t ordersConfiguring the Apache Iceberg Kafka Connect sink 🔗
Now let’s instantiate our Iceberg sink. The docs are pretty good, and include details of how to use different catalogs. I’m going to configure the sink thus:
-
Read messages from the
orderstopic -
Write them to the Iceberg table
foo.kc.orders -
Use the AWS Glue Data Catalog to store metadata
-
I’ve passed my local AWS credentials as environment variables to the Kafka Connect docker container. This is not a secure way of doing things, but suffices plenty for these sandbox testing purposes.
-
-
Store the Iceberg files on S3 in the
rmoff-lakehousebucket under the/01path
Using kcctl it looks like this:
$ kcctl apply -f - <<EOF
{
"name": "iceberg-sink-kc_orders",
"config": {
"connector.class": "io.tabular.iceberg.connect.IcebergSinkConnector",
"topics": "orders",
"iceberg.tables": "foo.kc.orders",
"iceberg.catalog.catalog-impl": "org.apache.iceberg.aws.glue.GlueCatalog",
"iceberg.catalog.warehouse": "s3://rmoff-lakehouse/01/",
"iceberg.catalog.io-impl": "org.apache.iceberg.aws.s3.S3FileIO"
}
}
EOFCheck if it worked:
$ kcctl get connectors
NAME TYPE STATE TASKS
iceberg-sink-kc_orders sink RUNNING 0: FAILED
$ kcctl describe connector iceberg-sink-kc_orders
Name: iceberg-sink-kc_orders
Type: sink
State: RUNNING
Worker ID: kafka-connect:8083
Config:
connector.class: io.tabular.iceberg.connect.IcebergSinkConnector
iceberg.catalog.catalog-impl: org.apache.iceberg.aws.glue.GlueCatalog
iceberg.catalog.io-impl: org.apache.iceberg.aws.s3.S3FileIO
iceberg.catalog.warehouse: s3://rmoff-lakehouse/00/
iceberg.tables: foo.kc.orders
name: iceberg-sink-kc_orders
topics: orders
Tasks:
0:
State: FAILED
Worker ID: kafka-connect:8083
Trace: org.apache.kafka.connect.errors.ConnectException: Tolerance exceeded in error handler
at
[…]
Caused by: org.apache.kafka.connect.errors.DataException: JsonConverter with schemas.enable requires "schema" and "payload" fields and may not contain additional fields. If you are trying to deserialize plain JSON data, set schemas.enable=false in your converter configuration.
[…]So, no dice on the first attempt.
(Note also the confusing fact that the connector has a state of RUNNING whilst the task is FAILED—this is just one of those things about how Kafka Connect works 🙃).
The error is to do with how Kafka Connect handles deserialising messages from Kafka topics.
It’s reading JSON, but expecting to find schema and payload elements within it—and these aren’t there.
This blog post explains the issue in more detail.
To fix it we’ll change the connector configuration, which we can do easily with kcctl’s patch:
$ kcctl patch connector iceberg-sink-kc_orders \
-s key.converter=org.apache.kafka.connect.json.JsonConverter \
-s key.converter.schemas.enable=false \
-s value.converter=org.apache.kafka.connect.json.JsonConverter \
-s value.converter.schemas.enable=falseCheck the connector state again:
$ kcctl describe connector iceberg-sink-kc_orders
Name: iceberg-sink-kc_orders
Type: sink
State: RUNNING
Worker ID: kafka-connect:8083
Config:
connector.class: io.tabular.iceberg.connect.IcebergSinkConnector
iceberg.catalog.catalog-impl: org.apache.iceberg.aws.glue.GlueCatalog
iceberg.catalog.io-impl: org.apache.iceberg.aws.s3.S3FileIO
iceberg.catalog.warehouse: s3://rmoff-lakehouse/01/
iceberg.tables: foo.kc.orders
key.converter: org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable: false
name: iceberg-sink-kc_orders
topics: orders
value.converter: org.apache.kafka.connect.json.JsonConverter
value.converter.schemas.enable: false
Tasks:
0:
State: FAILED
[…]
Caused by: org.apache.iceberg.exceptions.NoSuchTableException: Invalid table identifier: foo.kc.ordersThis time the error is entirely self-inflicted.
Hot off my blog post about doing this in Flink SQL, I had in my mind that the table needed a three-part qualification; catalog.database.table.
In fact, we only need to specify database.table.
In addition I’ve realised that the table doesn’t exist already, and by default the connector won’t automagically create it—so let’s fix that too.
$ kcctl patch connector iceberg-sink-kc_orders \
-s iceberg.tables=kc.orders \
-s iceberg.tables.auto-create-enabled=trueWe’re getting closer, but not quite there yet:
[…]
Caused by: software.amazon.awssdk.services.glue.model.EntityNotFoundException: Database kc not found. (Service: Glue, Status Code: 400, Request ID: 16a25fcf-01be-44e9-ba67-cc71431f3945)Let’s see what databases we do have:
$ aws glue get-databases --region us-east-1 --query 'DatabaseList[].Name' --output table
+--------------------+
| GetDatabases |
+--------------------+
| default_database |
| my_glue_db |
| new_glue_db |
| rmoff_db |
+--------------------+So, let’s use a database that does exist (rmoff_db):
$ kcctl patch connector iceberg-sink-kc_orders \
-s iceberg.tables=rmoff_db.ordersNow we’re up and running :)
$ kcctl describe connector iceberg-sink-kc_orders
Name: iceberg-sink-kc_orders
Type: sink
State: RUNNING
Worker ID: kafka-connect:8083
Config:
connector.class: io.tabular.iceberg.connect.IcebergSinkConnector
iceberg.catalog.catalog-impl: org.apache.iceberg.aws.glue.GlueCatalog
iceberg.catalog.io-impl: org.apache.iceberg.aws.s3.S3FileIO
iceberg.catalog.warehouse: s3://rmoff-lakehouse/01/
iceberg.tables: rmoff_db.orders
iceberg.tables.auto-create-enabled: true
key.converter: org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable: false
name: iceberg-sink-kc_orders
topics: orders
value.converter: org.apache.kafka.connect.json.JsonConverter
value.converter.schemas.enable: false
Tasks:
0:
State: RUNNING
Worker ID: kafka-connect:8083
Topics:
ordersExamining the Iceberg table 🔗
Now we’ll have a look at the Iceberg table.
The table has been registered in the Glue Data Catalog:
$ aws glue get-tables \
--region us-east-1 --database-name rmoff_db \
--query 'TableList[].Name' --output table
+----------------+
| GetTables |
+----------------+
| orders |
+----------------+And there’s something in the S3 bucket:
$ aws s3 --recursive ls s3://rmoff-lakehouse/01
2025-06-30 16:44:39 1320 01/rmoff_db.db/orders/metadata/00000-bcbeeafa-4556-4a52-92ee-5dbc34d35d6b.metadata.jsonHowever, this is just the table’s Iceberg metadata—but nothing else.
That’s because Kafka Connect won’t flush the data to storage straight away; by default it’s every 5 minutes.
The configuration that controls this is iceberg.control.commit.interval-ms.
So, if we wait long enough, we’ll see some data:
$ aws s3 --recursive ls s3://rmoff-lakehouse/01
2025-06-30 16:51:35 1635 01/rmoff_db.db/orders/data/00001-1751298279338-409ff5c8-244f-4104-8b81-dfe47fcbb2b3-00001.parquet
2025-06-30 16:44:39 1320 01/rmoff_db.db/orders/metadata/00000-bcbeeafa-4556-4a52-92ee-5dbc34d35d6b.metadata.json
2025-06-30 16:55:09 2524 01/rmoff_db.db/orders/metadata/00001-e8341cee-cf17-4255-bcf1-6e87cf41bbf3.metadata.json
2025-06-30 16:55:08 6950 01/rmoff_db.db/orders/metadata/cbe2651d-7c83-4465-a2e1-d92bb3e0b61d-m0.avro
2025-06-30 16:55:09 4233 01/rmoff_db.db/orders/metadata/snap-6069858821353147927-1-cbe2651d-7c83-4465-a2e1-d92bb3e0b61d.avroAlternatively we can be impatient (and inefficient, if we were to use this for real as you’d get a ton of small files as a result) and override it to commit every second:
$ kcctl patch connector iceberg-sink-kc_orders \
-s iceberg.control.commit.interval-ms=1000Now let’s have a look at this data that we’ve written. The absolute joy of Iceberg is the freedom that it gives you by decoupling storage from engine. This means that we can write the data with one engine (here, Kafka Connect), and read it from another. Let’s use DuckDB. Because, quack.
DuckDB supports AWS Glue Data Catalog for Iceberg metadata. I had some trouble with it, but found a useful workaround (yay open source). There’s also a comprehensive blog post from Tobias Müller on how to get it to work with a ton of IAM, ARN, and WTF (I think I made the last one up)—probably useful if you need to get this to work with any semblance of security.
So, first we create an S3 secret in DuckDB to provide our AWS credentials, which I’m doing via credential_chain which will read them from my local environment variables.
🟡◗ CREATE SECRET iceberg_secret (
TYPE S3,
PROVIDER credential_chain
);Then we attach the Glue data catalog as a new database to the DuckDB session.
Here, 1234 is my AWS account id (which you can get with aws sts get-caller-identity --query Account).
🟡◗ ATTACH '1234' AS glue_catalog (
TYPE iceberg,
ENDPOINT_TYPE glue
);Once you’ve done this you should be able to list the table(s) in your Glue Data Catalog:
-- These are DuckDB databases
🟡◗ SHOW DATABASES;
┌───────────────┐
│ database_name │
│ varchar │
├───────────────┤
│ glue_catalog │
│ memory │
└───────────────┘
🟡◗ SELECT * FROM information_schema.tables
WHERE table_catalog = 'glue_catalog'
AND table_schema='rmoff_db';
┌───────────────┬──────────────┬──────────────────┬────────────┬
│ table_catalog │ table_schema │ table_name │ table_type │
│ varchar │ varchar │ varchar │ varchar │
├───────────────┼──────────────┼──────────────────┼────────────┼
│ glue_catalog │ rmoff_db │ orders │ BASE TABLE │
└───────────────┴──────────────┴──────────────────┴────────────┴Terminology-wise, a catalog in AWS Glue Data Catalog is a database in DuckDB (SHOW DATABASES), and also a catalog (table_catalog).
A Glue database is a DuckDB schema.
And a table is a table in both :)
Let’s finish this section by checking that the data we wrote to Kafka is indeed in Iceberg.
Here’s the source data read from the Kafka topic:
$ docker compose exec -it kcat kcat -b broker:9092 -C -t orders
{"order_id": "001", "customer_id": "cust_123", "product": "laptop", "quantity": 1, "price": 999.99}
{"order_id": "002", "customer_id": "cust_456", "product": "mouse", "quantity": 2, "price": 25.50}
{"order_id": "003", "customer_id": "cust_789", "product": "keyboard", "quantity": 1, "price": 75.00}
{"order_id": "004", "customer_id": "cust_321", "product": "monitor", "quantity": 1, "price": 299.99}
{"order_id": "005", "customer_id": "cust_654", "product": "headphones", "quantity": 1, "price": 149.99}and now the Iceberg table:
🟡◗ USE glue_catalog.rmoff_db;
🟡◗ SELECT * FROM orders;
┌────────────┬──────────┬────────┬─────────────┬──────────┐
│ product │ quantity │ price │ customer_id │ order_id │
│ varchar │ int64 │ double │ varchar │ varchar │
├────────────┼──────────┼────────┼─────────────┼──────────┤
│ laptop │ 1 │ 999.99 │ cust_123 │ 001 │
│ mouse │ 2 │ 25.5 │ cust_456 │ 002 │
│ keyboard │ 1 │ 75.0 │ cust_789 │ 003 │
│ monitor │ 1 │ 299.99 │ cust_321 │ 004 │
│ headphones │ 1 │ 149.99 │ cust_654 │ 005 │
└────────────┴──────────┴────────┴─────────────┴──────────┘Write another row of data to the Kafka topic (order_id: 006):
$ echo '{"order_id": "006", "customer_id": "cust_987", "product": "webcam", "quantity": 1, "price": 89.99}' | docker compose exec -T kcat kcat -P -b broker:9092 -t ordersNow wait a second (or whatever iceberg.control.commit.interval-ms is set to), and check the Iceberg table:
🟡◗ SELECT * FROM orders;
┌────────────┬──────────┬────────┬─────────────┬──────────┐
│ product │ quantity │ price │ customer_id │ order_id │
│ varchar │ int64 │ double │ varchar │ varchar │
├────────────┼──────────┼────────┼─────────────┼──────────┤
│ webcam │ 1 │ 89.99 │ cust_987 │ 006 │ (1)
│ laptop │ 1 │ 999.99 │ cust_123 │ 001 │
│ mouse │ 2 │ 25.5 │ cust_456 │ 002 │
│ keyboard │ 1 │ 75.0 │ cust_789 │ 003 │
│ monitor │ 1 │ 299.99 │ cust_321 │ 004 │
│ headphones │ 1 │ 149.99 │ cust_654 │ 005 │
└────────────┴──────────┴────────┴─────────────┴──────────┘| 1 | The new row of data 🎉 |
Schemas 🔗
Now that we’ve got the basic connection between Kafka and Iceberg using Kafka Connect working, let’s look at it in a bit more detail. The first thing that warrants a bit of attention is the schema of the data.
Here’s the first record of data from our Kafka topic:
{
"order_id": "001",
"customer_id": "cust_123",
"product": "laptop",
"quantity": 1,
"price": 999.99
}Eyeballing it, you and I can probably guess at the data types of the schema. Quantity is an integer, probably. Price, a decimal (unless you don’t realise it’s a currency and guess that it’s a float or double). Product is obviously a character field. What about the order ID though? It looks numeric, but has leading zeros; so a character field also?
My point is, there is no declared schema, only an inferred one. What does it look like written to Iceberg?
$ aws glue get-table --region us-east-1 --database-name rmoff_db --name orders \
--query 'Table.StorageDescriptor.Columns[].{Name:Name,Type:Type}' --output table
+--------------+----------+
| GetTable |
+--------------+----------+
| Name | Type |
+--------------+----------+
| product | string |
| quantity | bigint |
| price | double |
| customer_id | string |
| order_id | string |
+--------------+----------+Not bad—only the price being stored as a DOUBLE is wrong.
What about if we were to use a timestamp in the source data? And a boolean?
Here’s a new dataset in a Kafka topic. It’s roughly based on click behaviour.
{
"click_ts": "2023-02-01T14:30:25Z",
"ad_cost": "1.50",
"is_conversion": "true",
"user_id": "001234567890"
}Using the same Kafka Connect approach as above:
$ kcctl apply -f - <<EOF
{
"name": "iceberg-sink-kc_clicks",
"config": {
"connector.class": "io.tabular.iceberg.connect.IcebergSinkConnector",
"topics": "clicks",
"iceberg.tables": "rmoff_db.clicks",
"iceberg.tables.auto-create-enabled": "true",
"iceberg.catalog.catalog-impl": "org.apache.iceberg.aws.glue.GlueCatalog",
"iceberg.catalog.warehouse": "s3://rmoff-lakehouse/01/",
"iceberg.catalog.io-impl": "org.apache.iceberg.aws.s3.S3FileIO",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": "false",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": "false",
"iceberg.control.commit.interval-ms": "1000"
}
}
EOFit ends up like this in Iceberg:
$ ❯ aws glue get-table --region us-east-1 --database-name rmoff_db --name clicks\
--query 'Table.StorageDescriptor.Columns[].{Name:Name,Type:Type}' --output table
+----------------+----------+
| GetTable |
+----------------+----------+
| Name | Type |
+----------------+----------+
| click_ts | string |
| ad_cost | string |
| user_id | string |
| is_conversion | string |
+----------------+----------+Here we start to see the real flaw if we just rely on inferred schemas.
Holding a currency as a string?
Wat.
Storing a timestamp as a string?
Gross.
Using a string to hold a boolean?
Fine, until someone decides to put a value other than true or false in it. Or True. Or TRuE. And so on.
Data types exist for a reason, and part of good data pipeline hygiene is making use of them.
Enough of the lecturing…How do I use an explicit schema with Kafka Connect? 🔗
One option (but not one I’d recommend) is embedding the schema directly in the message.
This is actually what the JsonConverter was defaulting to in the first example above and through an error because we’d not done it.
Here’s what the above clicks record looks like with embedded schema:
{
"schema": {
"type": "struct",
"fields": [
{
"field": "click_ts",
"type": "int64",
"name": "org.apache.kafka.connect.data.Timestamp",
"version": 1,
"optional": false
},
{
"field": "ad_cost",
"type": "bytes",
"name": "org.apache.kafka.connect.data.Decimal",
"version": 1,
"parameters": {
"scale": "2"
},
"optional": false
},
{
"field": "is_conversion",
"type": "boolean",
"optional": false
},
{
"field": "user_id",
"type": "string",
"optional": false
}
]
},
"payload": {
"click_ts": 1675258225000,
"ad_cost": "1.50",
"is_conversion": true,
"user_id": "001234567890"
}
}Even though our Kafka Connect worker is defaulting to using it, I’m going to explicitly configure schemas.enable just for clarity:
kcctl apply -f - <<EOF
{
"name": "iceberg-sink-kc_clicks_schema",
"config": {
"connector.class": "io.tabular.iceberg.connect.IcebergSinkConnector",
"topics": "clicks_with_schema",
"iceberg.tables": "rmoff_db.clicks_embedded_schema",
"iceberg.tables.auto-create-enabled": "true",
"iceberg.catalog.catalog-impl": "org.apache.iceberg.aws.glue.GlueCatalog",
"iceberg.catalog.warehouse": "s3://rmoff-lakehouse/01/",
"iceberg.catalog.io-impl": "org.apache.iceberg.aws.s3.S3FileIO",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": "true",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": "true",
"iceberg.control.commit.interval-ms": "1000"
}
}
EOFThe first time I try it, it fails:
org.apache.kafka.connect.errors.DataException: Invalid bytes for Decimal field
com.fasterxml.jackson.databind.exc.InvalidFormatException: Cannot access contents of TextNode as binary due to broken Base64 encoding: Illegal character '.' (code 0x2e) in base64 contentThat’s because the ad_cost field is defined as a logical Decimal type, but physically stored as bytes, so I need to write it as that in the topic:
[…]
},
"payload": {
"click_ts": 1675258225000,
"ad_cost": "AJY=", (1)
"is_conversion": true,
"user_id": "001234567890"
}
}|
Where on earth do I get For decimal 1.50 with scale 2, we need to ensure proper signed integer encoding:
|
With the connector restarted reading from a fresh topic with this newly-encoded decimal value in it, things look good in Iceberg:
🟡◗ SELECT * FROM clicks_embedded_schema;
┌──────────────────────────┬───────────────┬───────────────┬──────────────┐
│ click_ts │ ad_cost │ is_conversion │ user_id │
│ timestamp with time zone │ decimal(38,2) │ boolean │ varchar │
├──────────────────────────┼───────────────┼───────────────┼──────────────┤
│ 2023-02-01 13:30:25+00 │ 1.50 │ true │ 001234567890 │ (1)| 1 | Proper data types, yay! |
BUT…this is a pretty heavy way of doing things. Bytes might be cheap, but do we really want to spend over 80% of the message on sending the full schema definition with every single record?
This is where a Schema Registry comes in.
Schema Registry 🔗
A schema registry is basically what it says on the tin. A registry, of schemas.
Instead of passing the full schema each time (like above), a client will have a reference to the schema in the message, and then retrieve the actual schema from the registry.

The most well known of the schema registries in the Kafka ecosystem is Confluent’s Schema Registry. I’ll show you shortly how it is used automatically within a pipeline, but first I’m going to demonstrate its "manual" use.
There are multiple serialisation options available, including:
-
Avro
-
Protobuf
-
JSONSchema
I’m going to demonstrate Avro here.
A schema for the clicks data above looks something like this:
{
"type": "record",
"name": "ClickEvent",
"fields": [
{
"name": "click_ts",
"type": { "type": "long", "logicalType": "timestamp-millis" }
},
{
"name": "ad_cost",
"type": { "type": "bytes", "logicalType": "decimal", "precision": 10, "scale": 2 }
},
{
"name": "is_conversion",
"type": "boolean"
},
{
"name": "user_id",
"type": "string"
}
]
}"Send this to Schema Registry using the REST API:
$ http POST localhost:8081/subjects/clicks-value/versions \
Content-Type:application/vnd.schemaregistry.v1+json \
schema='{"type":"record","name":"ClickEvent","fields":[{"name":"click_ts","type":{"type":"long","logicalType":"timestamp-millis"}},{"name":"ad_cost","type":{"type":"bytes","logicalType":"decimal","precision":10,"scale":2}},{"name":"is_conversion","type":"boolean"},{"name":"user_id","type":"string"}]}'This will return the ID that the schema has been assigned.
Now send the message to Kafka, specifying value.schema.id as the schema ID returned in the step above:
$ printf '{"click_ts": 1675258225000, "ad_cost": "1.50", "is_conversion": true, "user_id": "001234567890"}\n' | \
docker compose exec -T kafka-connect kafka-avro-console-producer \
--bootstrap-server broker:9092 \
--topic clicks_registry \
--property schema.registry.url=http://schema-registry:8081 \
--property value.schema.id=1What we now have is a Kafka topic with a message that holds just the payload plus a pointer to the schema. It’s the best of both worlds; a small message footprint, but a fully-defined schema available for any consumer to use.
|
An Avro-serialised message is smaller than a JSON one holding the same data: |
Let’s finish off by sending this Avro data over to Iceberg:
$ kcctl apply -f - <<EOF
{
"name": "iceberg-sink-clicks-registry",
"config": {
"connector.class": "io.tabular.iceberg.connect.IcebergSinkConnector",
"topics": "clicks_registry",
"iceberg.tables": "rmoff_db.clicks_schema_registry",
"iceberg.tables.auto-create-enabled": "true",
"iceberg.catalog.catalog-impl": "org.apache.iceberg.aws.glue.GlueCatalog",
"iceberg.catalog.warehouse": "s3://rmoff-lakehouse/01/",
"iceberg.catalog.io-impl": "org.apache.iceberg.aws.s3.S3FileIO",
"key.converter": "io.confluent.connect.avro.AvroConverter",
"key.converter.schema.registry.url": "http://schema-registry:8081",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "http://schema-registry:8081",
"iceberg.control.commit.interval-ms": "1000"
}
}
EOFThe data lands in Iceberg with its data types looking good:
🟡◗ SELECT * FROM clicks_schema_registry;
┌──────────────────────────┬───────────────┬───────────────┬──────────────┐
│ click_ts │ ad_cost │ is_conversion │ user_id │
│ timestamp with time zone │ decimal(38,2) │ boolean │ varchar │
├──────────────────────────┼───────────────┼───────────────┼──────────────┤
│ 2023-02-01 13:30:25+00 │ 8251118.56 │ true │ 001234567890 │But…what’s this?
For some reason ad_cost is 8251118.56 even though the source data was 1.50.
|
Decimals…again
Similar to the To represent the decimal
|
With the serialisation of the decimal value corrected thus:
printf '{"click_ts": 1675258225000, "ad_cost": "\\u0000\\u0096" ,"is_conversion": true, "user_id": "001234567890"}\n' | \
docker compose exec -T kafka-connect kafka-avro-console-producer \
--bootstrap-server broker:9092 \
--topic clicks_registry \
--property schema.registry.url=http://schema-registry:8081 \
--property value.schema.id=1I finally got the expected value showing in Iceberg:
🟡◗ SELECT * FROM clicks_schema_registry;
┌──────────────────────────┬───────────────┬───────────────┬──────────────┐
│ click_ts │ ad_cost │ is_conversion │ user_id │
│ timestamp with time zone │ decimal(38,2) │ boolean │ varchar │
├──────────────────────────┼───────────────┼───────────────┼──────────────┤
│ 2023-02-01 13:30:25+00 │ 1.50 │ true │ 001234567890 │Postgres to Iceberg via Kafka Connect 🔗
Let’s put this into practice now. I’m going to use Kafka Connect with the Debezium connector to get data from Postgres and then write it to Iceberg with the same sink connector we’ve used above.
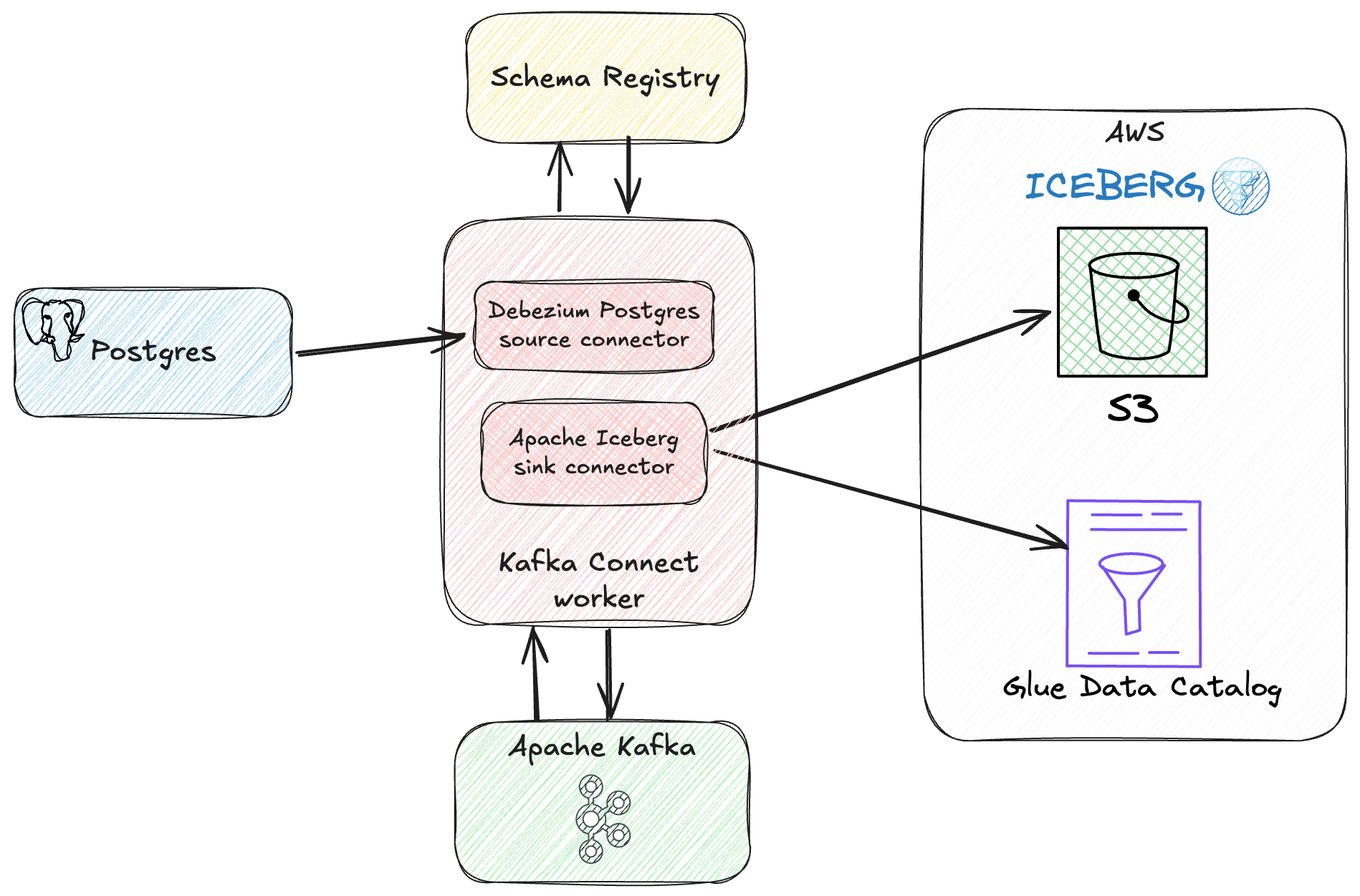
First, create and populate Postgres table:
CREATE TABLE clicks (
click_ts TIMESTAMP WITH TIME ZONE,
ad_cost DECIMAL(38,2),
is_conversion BOOLEAN,
user_id VARCHAR
);
INSERT INTO clicks (click_ts, ad_cost, is_conversion, user_id)
VALUES ('2023-02-01 13:30:25+00', 1.50, true, '001234567890');Then check we’ve got the Debezium connector installed on our Kafka Connect worker:
$ kcctl get plugins --types=source
TYPE CLASS VERSION
source io.debezium.connector.postgresql.PostgresConnector 3.1.2.Finaland create a Debezium source connector:
$ kcctl apply -f - <<EOF
{
"name": "postgres-clicks-source",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "postgres",
"database.port": "5432",
"database.user": "postgres",
"database.password": "Welcome123",
"database.dbname": "postgres",
"table.include.list": "public.clicks",
"topic.prefix": "dbz"
}
}
EOFUsing kcctl we can see that the connector is running, and writing data to a topic:
$ kcctl describe connector postgres-clicks-source
Name: postgres-clicks-source
Type: source
State: RUNNING
[…]
Topics:
dbz.public.clicksIf we take a look at the topic we can quickly see a mistake I’ve made in the configuration of the connector:
$ docker compose exec -T kcat kcat -b broker:9092 -C -t dbz.public.clicks -c1
{"schema":{"type":"struct","fields":[{"type":"struct","fields":[{"type":"string","optional":true,"name":"io.debezium.time.ZonedTimestamp","version":1,"field":"click_ts"},{"type":"bytes","optional":true,"name":"org.apache.kafka.connect.data.Decimal","version":1,"parameters":{"scale":"2","connect.decimal.precision":"38"},"field":"ad_cost"},{"type":"boolean","optional":true,"field":"is_conversion"},{"type":"string","optional":true,"field":"user_id"}],"optional":true,"name":"dbz.public.clicks.Value","field":"before"},{"type":"struct","fields":[{"type":"string","optional":true,"name":"io.debezium.time.ZonedTimestamp","version":1,"field":"click_ts"},{"type":"bytes","optional":true,"name
[…]It’s using the JsonConverter with an embedded schema.
That’s not what we want, so let’s create a new version of the connector.
It’s important to create a new version, because the existing one won’t re-read messages from the topic just because we change its configuration because logically it has processed that data already.
We also need to make sure we write to a different topic; writing JSON and Avro to the same Kafka topic is a recipe for disaster (or at least, wailing and gnashing of teeth when a sink connector spectacularly fails to read the messages).
$ kcctl delete connector postgres-clicks-source
$ kcctl apply -f - <<EOF
{
"name": "postgres-clicks-source-avro",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "postgres",
"database.port": "5432",
"database.user": "postgres",
"database.password": "Welcome123",
"database.dbname": "postgres",
"table.include.list": "public.clicks",
"topic.prefix": "dbz-avro",
"key.converter": "io.confluent.connect.avro.AvroConverter",
"key.converter.schema.registry.url": "http://schema-registry:8081",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "http://schema-registry:8081"
}
}
EOFNow we can see the Avro data in the topic:
$ docker compose exec -T kcat kcat -b broker:9092 -C -t dbz-avro.public.clicks -c1
62023-02-01T13:30:25.000000Z0012345678903.1.2.Finalpostgresqldbz-avroe
firstpostgres"[null,"34511440"]Ђӻ0
public
clicks
reʷӻ0To deserialise it correctly we use -s avro as above, and we see that the payload from Debezium is more complex than a simple message:
$ docker compose exec -T kcat kcat -C -b broker:9092 -t dbz-avro.public.clicks \
-s avro -r http://schema-registry:8081 -c1 | jq '.'{
"before": null,
"after": {
"Value": {
"click_ts": {
"string": "2023-02-01T13:30:25.000000Z"
},
"ad_cost": {
"bytes": ""
},
"is_conversion": {
"boolean": true
},
"user_id": {
"string": "001234567890"
}
}
},
"source": {
"version": "3.1.2.Final",
"connector": "postgresql",
"name": "dbz-avro",
"ts_ms": 1751447315595,
"snapshot": {
"string": "first"
},
"db": "postgres",
[…]Debezium, and any good CDC tool in general, doesn’t just capture the current state of a row; it captures changes.
Since this is the initial snapshot, we have a blank before section, the payload in after (i.e. current state), and then some metadata (source).
You might want all of this raw change data sent to Iceberg, but more likely is that you just want the current state of the record.
To do this you can use a Kafka Connect Single Message Transformation (SMT).
Both Iceberg and Debezium ship with their own SMTs to do this.
Iceberg has DebeziumTransform and Debezium ExtractNewRecordState.
The differences between them that I can tell are:
-
The Iceberg one is marked experimental, whilst the Debezium one has been used in production for years
-
The Iceberg one adds CDC metadata fields (operation type, offset, etc) along with the record state, whilst to do this with the Debezium one you’d need to include the
add.fieldsoption.
Let’s try the Iceberg one, which we’ll configure as part of the new sink connector itself:
$ kcctl apply -f - <<EOF
{
"name": "iceberg-sink-postgres-clicks",
"config": {
"connector.class": "io.tabular.iceberg.connect.IcebergSinkConnector",
"topics": "dbz-avro.public.clicks",
"iceberg.tables": "rmoff_db.postgres_clicks",
"iceberg.tables.auto-create-enabled": "true",
"iceberg.catalog.catalog-impl": "org.apache.iceberg.aws.glue.GlueCatalog",
"iceberg.catalog.warehouse": "s3://rmoff-lakehouse/01/",
"iceberg.catalog.io-impl": "org.apache.iceberg.aws.s3.S3FileIO",
"key.converter": "io.confluent.connect.avro.AvroConverter",
"key.converter.schema.registry.url": "http://schema-registry:8081",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "http://schema-registry:8081",
"iceberg.control.commit.interval-ms": "1000",
"transforms": "dbz",
"transforms.dbz.type": "io.tabular.iceberg.connect.transforms.DebeziumTransform"
}
}
EOFHere’s the resulting Iceberg table:
🟡◗ describe postgres_clicks;
┌───────────────┬──────────────────────────────────────────────────────────────┬
│ column_name │ column_type │
│ varchar │ varchar │
├───────────────┼──────────────────────────────────────────────────────────────┼
│ click_ts │ VARCHAR │
│ ad_cost │ DECIMAL(38,2) │
│ is_conversion │ BOOLEAN │
│ user_id │ VARCHAR │
│ _cdc │ STRUCT(op VARCHAR, ts TIMESTAMP WITH TIME ZONE, │
│ │ "offset" BIGINT, source VARCHAR, target VARCHAR) │
└───────────────┴──────────────────────────────────────────────────────────────┴and data:
🟡◗ SELECT * FROM postgres_clicks;
┌─────────────────────────────┬───────────────┬───────────────┬──────────────┬[…]
│ click_ts │ ad_cost │ is_conversion │ user_id │[…]
│ varchar │ decimal(38,2) │ boolean │ varchar │[…]
├─────────────────────────────┼───────────────┼───────────────┼──────────────┼[…]
│ 2023-02-01T13:30:25.000000Z │ 1.50 │ true │ 001234567890 │[…]Data Type Fun: Timestamps 🔗
One data type issue this time—pun intended.
The click_ts should be a timestamp, but is showing up as a string in Iceberg.
To understand where this is occurring, I’ll start by checking the schema that Debezium wrote to the Schema Registry when it wrote the data to Kafka:
$ http http://localhost:8081/subjects/dbz-avro.public.clicks-value/versions/latest | \
jq '.schema | fromjson'[…]
{
"name": "click_ts",
"type": [
"null",
{
"type": "string",
"connect.version": 1,
"connect.name": "io.debezium.time.ZonedTimestamp"
}
],
"default": null
},
[…]Per the docs, it’s stored as a string, but using the Kafka Connect logical type io.debezium.time.ZonedTimestamp.
Let’s have a look at the TimestampConverter SMT.
This will hopefully let us convert the string type (which holds the timestamp) into a logical Timestamp type as part of the sink connector.
$ kcctl apply -f - <<EOF
{
"name": "iceberg-sink-postgres-clicks-new",
"config": {
"connector.class": "io.tabular.iceberg.connect.IcebergSinkConnector",
"topics": "dbz-avro.public.clicks",
"iceberg.tables": "rmoff_db.postgres_clicks",
"iceberg.tables.auto-create-enabled": "true",
"iceberg.catalog.catalog-impl": "org.apache.iceberg.aws.glue.GlueCatalog",
"iceberg.catalog.warehouse": "s3://rmoff-lakehouse/02/",
"iceberg.catalog.io-impl": "org.apache.iceberg.aws.s3.S3FileIO",
"key.converter": "io.confluent.connect.avro.AvroConverter",
"key.converter.schema.registry.url": "http://schema-registry:8081",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "http://schema-registry:8081",
"iceberg.control.commit.interval-ms": "1000",
"transforms": "dbz,convert_ts", (1)
"transforms.dbz.type": "io.tabular.iceberg.connect.transforms.DebeziumTransform",
"transforms.convert_ts.type" : "org.apache.kafka.connect.transforms.TimestampConverter\$Value",
"transforms.convert_ts.field" : "click_ts",
"transforms.convert_ts.format": "yyyy-MM-dd'T'HH:mm:ss.SSSSSS'Z'",
"transforms.convert_ts.target.type": "Timestamp"
}
}
EOF| 1 | The order of the transformations is important; for the convert_ts transform to work the click_ts field needs to have been unnested, which is what the dbz transform does first. |
With the initial postgres_clicks Iceberg table deleted, and the new version of the connector running (so as to make sure that the table gets recreated with-hopefully—the correct schema), we see this in Iceberg:
🟡◗ describe postgres_clicks;
┌───────────────┬─────────────────────────────────────────────────────────────────[…]
│ column_name │ column_type […]
│ varchar │ varchar […]
├───────────────┼─────────────────────────────────────────────────────────────────[…]
│ click_ts │ TIMESTAMP WITH TIME ZONE […]
│ ad_cost │ DECIMAL(38,2) […]
│ is_conversion │ BOOLEAN […]
│ user_id │ VARCHAR […]
│ _cdc │ STRUCT(op VARCHAR, ts TIMESTAMP WITH TIME ZONE, "offset" BIGINT,[…]
└───────────────┴─────────────────────────────────────────────────────────────────[…]
🟡◗ select click_ts, ad_cost, is_conversion, user_id from postgres_clicks;
┌──────────────────────────┬───────────────┬───────────────┬──────────────┐
│ click_ts │ ad_cost │ is_conversion │ user_id │
│ timestamp with time zone │ decimal(38,2) │ boolean │ varchar │
├──────────────────────────┼───────────────┼───────────────┼──────────────┤
│ 2023-02-01 13:30:25+00 │ 1.50 │ true │ 001234567890 │
└──────────────────────────┴───────────────┴───────────────┴──────────────┘Compare the data types and data to the Postgres source:
postgres=# \d clicks
Table "public.clicks"
Column | Type | Collation | Nullable | Default
---------------+--------------------------+-----------+----------+---------
click_ts | timestamp with time zone | | |
ad_cost | numeric(38,2) | | |
is_conversion | boolean | | |
user_id | character varying | | |
postgres=# select * from clicks;
click_ts | ad_cost | is_conversion | user_id
------------------------+---------+---------------+--------------
2023-02-01 13:30:25+00 | 1.50 | t | 001234567890Perfect!
|
If you’re using and the Iceberg Kafka Connect sink write it, by default, as a You can use the same The only problem is that this ends up in Iceberg as a |
Schema Evolution 🔗
What happens when we add a column to the source data being sent through the Kafka Connect Iceberg sink? Let’s try it!
ALTER TABLE clicks ADD COLUMN campaign_id character varying;
INSERT INTO clicks (click_ts, ad_cost, is_conversion, user_id, campaign_id)
VALUES ('2025-07-03 14:30:00+00', 2.50, true, 'user_12345', 'campaign_summer_2025');The table now looks like this:
postgres=# SELECT * FROM clicks;
click_ts | ad_cost | is_conversion | user_id | campaign_id
------------------------+---------+---------------+--------------+----------------------
2023-02-01 13:30:25+00 | 1.50 | t | 001234567890 | (1)
2025-07-03 14:30:00+00 | 2.50 | t | user_12345 | campaign_summer_2025| 1 | This row existed already, so has no value for the new field, campaign_id |
Over in Iceberg, we can see the new row—but no new column:
🟡◗ select * from postgres_clicks;
┌──────────────────────┬───────────────┬───────────────┬──────────────┬─────────────────────[…]
│ click_ts │ ad_cost │ is_conversion │ user_id │ […]
│ timestamp with tim… │ decimal(38,2) │ boolean │ varchar │ struct(op varchar, […]
├──────────────────────┼───────────────┼───────────────┼──────────────┼─────────────────────[…]
│ 2025-07-03 15:30:0… │ 2.50 │ true │ user_12345 │ {'op': I, 'ts': '202[…]
│ 2023-02-01 13:30:2… │ 1.50 │ true │ 001234567890 │ {'op': I, 'ts': '202[…]
└──────────────────────┴───────────────┴───────────────┴──────────────┴─────────────────────[…]
🟡◗ DESCRIBE postgres_clicks;
┌───────────────┬───────────────────────────────────────────────────────────────────────────[…]
│ column_name │ column_type […]
│ varchar │ varchar […]
├───────────────┼───────────────────────────────────────────────────────────────────────────[…]
│ click_ts │ TIMESTAMP WITH TIME ZONE […]
│ ad_cost │ DECIMAL(38,2) […]
│ is_conversion │ BOOLEAN […]
│ user_id │ VARCHAR […]
│ _cdc │ STRUCT(op VARCHAR, ts TIMESTAMP WITH TIME ZONE, "offset" BIGINT, source VA[…]
└───────────────┴───────────────────────────────────────────────────────────────────────────[…]A quick perusal of the docs points us at iceberg.tables.evolve-schema-enabled, which is false by default.
As a side note, whilst the docs are good, you can also get a quick look at the configuration options a connector has by looking at the Kafka Connect worker log file for IcebergSinkConfig values:
[2025-07-03 09:28:58,309] INFO [iceberg-sink-postgres-clicks-new|task-0] IcebergSinkConfig values:
iceberg.catalog = iceberg
iceberg.connect.group-id = null
iceberg.control.commit.interval-ms = 1000
iceberg.control.commit.threads = 28
iceberg.control.commit.timeout-ms = 1000
iceberg.control.group-id = null
iceberg.control.topic = control-iceberg
iceberg.hadoop-conf-dir = null
iceberg.tables = [rmoff_db.postgres_clicks]
iceberg.tables.auto-create-enabled = true
iceberg.tables.cdc-field = null
iceberg.tables.default-commit-branch = null
iceberg.tables.default-id-columns = null
iceberg.tables.default-partition-by = null
iceberg.tables.dynamic-enabled = false
iceberg.tables.evolve-schema-enabled = false
iceberg.tables.route-field = null
iceberg.tables.schema-case-insensitive = false
iceberg.tables.schema-force-optional = false
iceberg.tables.upsert-mode-enabled = falseSo, let’s create a new version of this connector and test it out. I’m going to follow the same pattern as above; create the initial table and add a row, make sure it syncs to a new Iceberg table, then alter the table and add another row and see if that propagates as expected.
$ kcctl apply -f - <<EOF
{
"name": "iceberg-sink-postgres-clicks01",
"config": {
"connector.class": "io.tabular.iceberg.connect.IcebergSinkConnector",
"topics": "dbz-avro.public.clicks01",
"iceberg.tables": "rmoff_db.postgres_clicks01",
"iceberg.tables.auto-create-enabled": "true",
"iceberg.tables.evolve-schema-enabled": "true",
"iceberg.catalog.catalog-impl": "org.apache.iceberg.aws.glue.GlueCatalog",
"iceberg.catalog.warehouse": "s3://rmoff-lakehouse/02/",
"iceberg.catalog.io-impl": "org.apache.iceberg.aws.s3.S3FileIO",
"key.converter": "io.confluent.connect.avro.AvroConverter",
"key.converter.schema.registry.url": "http://schema-registry:8081",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "http://schema-registry:8081",
"iceberg.control.commit.interval-ms": "1000",
"transforms": "dbz,convert_ts",
"transforms.dbz.type": "io.tabular.iceberg.connect.transforms.DebeziumTransform",
"transforms.convert_ts.type" : "org.apache.kafka.connect.transforms.TimestampConverter\$Value",
"transforms.convert_ts.field" : "click_ts",
"transforms.convert_ts.format": "yyyy-MM-dd'T'HH:mm:ss.SSSSSS'Z'",
"transforms.convert_ts.target.type": "Timestamp"
}
}
EOFThis works exactly as I’d hoped.
The Iceberg table has the new field (campaign_id, after the _cdc metadata):
🟡◗ DESCRIBE postgres_clicks01;
┌───────────────┬───────────────────────────────────────────────────────────────────────────[…]
│ column_name │ column_type […]
│ varchar │ varchar […]
├───────────────┼───────────────────────────────────────────────────────────────────────────[…]
│ click_ts │ TIMESTAMP WITH TIME ZONE […]
│ ad_cost │ DECIMAL(38,2) […]
│ is_conversion │ BOOLEAN […]
│ user_id │ VARCHAR […]
│ _cdc │ STRUCT(op VARCHAR, ts TIMESTAMP WITH TIME ZONE, "offset" BIGINT, source VA[…]
│ campaign_id │ VARCHAR […]
└───────────────┴───────────────────────────────────────────────────────────────────────────[…]and the new data is present too:
🟡◗ select click_ts, ad_cost, is_conversion, user_id, campaign_id from postgres_clicks01;
┌──────────────────────────┬───────────────┬───────────────┬──────────────┬──────────────────[…]
│ click_ts │ ad_cost │ is_conversion │ user_id │ campaign_id […]
│ timestamp with time zone │ decimal(38,2) │ boolean │ varchar │ varchar […]
├──────────────────────────┼───────────────┼───────────────┼──────────────┼──────────────────[…]
│ 2023-02-01 13:30:25+00 │ 1.50 │ true │ 001234567890 │ NULL […]
│ 2025-07-03 15:30:00+01 │ 2.50 │ true │ user_12345 │ campaign_summer_2[…]
└──────────────────────────┴───────────────┴───────────────┴──────────────┴──────────────────[…]N:N (Many-to-Many / Sending data from multiple topics to many Iceberg tables) 🔗
So far I’ve shown you how to get one Postgres table to one Iceberg table. Or to be more precise: one Kafka topic to one Iceberg table. The Kafka Connect Iceberg sink simply reads from a Kafka topic, and that topic can be populated by anything, including Kafka Connect source connectors, or applications directly.
Anyway, what about writing to multiple Iceberg tables. Does that mean multiple Kafka Connect Iceberg sink instances? No!
With Kafka Connect you can specify a list of topics with topics, or a regex with topics.regex.
Let’s try it.
I’m going to stick with Postgres here for my example to populate the multiple topics that we’ll then read from and send to multiple Postgres tables.
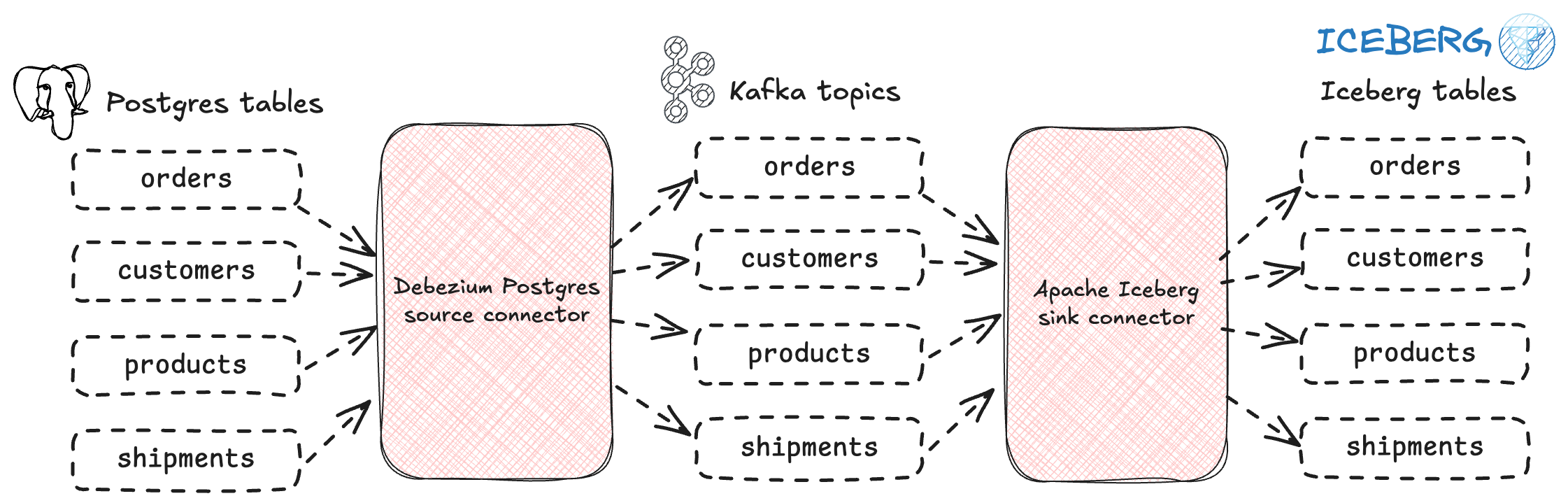
There are four tables in my schema:
postgres=# \dt
List of relations
Schema | Name | Type | Owner
--------+-----------+-------+----------
europe | customers | table | postgres
europe | orders | table | postgres
europe | products | table | postgres
europe | shipments | table | postgresI’ll create a Debezium connector that’s going to pick up all of them ("schema.include.list": "europe",), writing each to its own Kafka topic:
$ kcctl apply -f - <<EOF
{
"name": "postgres-europe",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "postgres",
"database.port": "5432",
"database.user": "postgres",
"database.password": "Welcome123",
"database.dbname": "postgres",
"schema.include.list": "europe",
"topic.prefix": "dbz-avro",
"key.converter": "io.confluent.connect.avro.AvroConverter",
"key.converter.schema.registry.url": "http://schema-registry:8081",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "http://schema-registry:8081"
}
}
EOFWith this running, we can see that it’s writing to four Kafka topics, as expected:
$ kcctl describe connector postgres-europe
Name: postgres-europe
Type: source
State: RUNNING
Worker ID: kafka-connect:8083
[…]
Topics:
dbz-avro.europe.customers
dbz-avro.europe.orders
dbz-avro.europe.products
dbz-avro.europe.shipmentsTo send these to Iceberg we need to tell the sink connector to handle multiple source topics.
For it to read from multiple topics we use topics.regex:
"topics.regex": "dbz-avro.europe.*",When it comes to specifying the target Iceberg table you have two options:
-
Use
iceberg.tables. You can put a comma-separated list of tables here, but as far as I can tell all that will do is write the same source data to each of the target tables (i.e. you end up with multiple Iceberg tables with the same contents). This won’t work for multiple source topics if they have different schemas. -
Set
iceberg.tables.dynamic-enabledtotrue, and then specify iniceberg.tables.route-fieldthe field within the topic that holds the name of the target Iceberg table to write to.
Using dynamic routing works fine if you’ve got a single source topic that holds this field.
The example in the documentation is a list of events with different type values, and each event is routed to a different Iceberg table named based on the event type.
For our purpose here though we need to be a bit more imaginative.
The source data itself doesn’t hold any values that we can use for the table name.
For example, in products, which field name can we use as the target table name?
postgres=# \d products
Table "europe.products"
Column | Type | Collation | Nullable | Default
----------------+------------------------+-----------+----------+--------------------------[…]
id | integer | | not null | nextval('products_id_seq'[…]
product_name | character varying(255) | | not null |
category | character varying(100) | | |
price | numeric(10,2) | | not null |
stock_quantity | integer | | | 0None of them. But what about in the metadata that Debezium provides? Here’s a snippet of the message that Debezium writes to Kafka:
{
"before": null,
"after": {
[…]
"source": {
"version": "3.1.2.Final",
"connector": "postgresql",
"name": "dbz-avro",
[…]
"schema": "europe", (1)
"table": "products", (1)| 1 | Table name and schema! |
Let’s try that in the Iceberg connector:
$ kcctl apply -f - <<EOF
{
"name": "iceberg-sink-postgres-europe",
"config": {
"connector.class": "io.tabular.iceberg.connect.IcebergSinkConnector",
"topics.regex": "dbz-avro.europe.*",
"iceberg.tables.dynamic-enabled": "true",
"iceberg.tables.route-field": "source.table",
"iceberg.tables.auto-create-enabled": "true",
"iceberg.tables.evolve-schema-enabled": "true",
"iceberg.catalog.catalog-impl": "org.apache.iceberg.aws.glue.GlueCatalog",
"iceberg.catalog.warehouse": "s3://rmoff-lakehouse/02/",
"iceberg.catalog.io-impl": "org.apache.iceberg.aws.s3.S3FileIO",
"key.converter": "io.confluent.connect.avro.AvroConverter",
"key.converter.schema.registry.url": "http://schema-registry:8081",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "http://schema-registry:8081",
"iceberg.control.commit.interval-ms": "1000",
"transforms": "dbz",
"transforms.dbz.type": "io.tabular.iceberg.connect.transforms.DebeziumTransform"
}
}
EOFHowever, this fails:
org.apache.kafka.connect.errors.DataException: source is not a valid field nameAfter a bit of Googling around I realised that perhaps the route-field is applied after the DebeziumTransform in the sink, and so need to be thinking about the final record schema.
Fortunately we still have a table as part of that data as part of the _cdc field that the DebeziumTransform adds.
So let’s try it with "iceberg.tables.route-field":"_cdc.target".
Now we get a different error, and one that looks a bit more hopeful:
software.amazon.awssdk.services.glue.model.EntityNotFoundException: Database europe not found.You might wonder why I say that this is more hopeful :)
That’s because it’s found the field!
It’s just not happy with it, because it’s taken the schema from Postgres (europe in our example here) as the Iceberg database.
Fortunately in the docs for the DebeziumTransform we find the configuration option cdc.target.pattern which we’re told defaults to {db}.{table}.
Let’s change it to move the schema to a table prefix (separated by an underscore: {db}_{table}), and hardcode in the database that I want to use, and see what happens:
$ kcctl apply -f - <<EOF
{
"name": "iceberg-sink-postgres-europe",
"config": {
"connector.class": "io.tabular.iceberg.connect.IcebergSinkConnector",
"topics.regex": "dbz-avro.europe.*",
"iceberg.tables.dynamic-enabled": "true",
"iceberg.tables.route-field":"_cdc.target",
"iceberg.tables.auto-create-enabled": "true",
"iceberg.tables.evolve-schema-enabled": "true",
"iceberg.catalog.catalog-impl": "org.apache.iceberg.aws.glue.GlueCatalog",
"iceberg.catalog.warehouse": "s3://rmoff-lakehouse/02/",
"iceberg.catalog.io-impl": "org.apache.iceberg.aws.s3.S3FileIO",
"key.converter": "io.confluent.connect.avro.AvroConverter",
"key.converter.schema.registry.url": "http://schema-registry:8081",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "http://schema-registry:8081",
"iceberg.control.commit.interval-ms": "1000",
"transforms": "dbz",
"transforms.dbz.type": "io.tabular.iceberg.connect.transforms.DebeziumTransform",
"transforms.dbz.cdc.target.pattern": "rmoff_db.{db}_{table}"
}
}
EOFIt works!
Over in Iceberg we have the four tables in the rmoff_db database and a europe_ prefix:
🟡◗ SHOW TABLES;
┌───────────────────────────┐
│ name │
│ varchar │
├───────────────────────────┤
[…]
│ europe_customers │
│ europe_orders │
│ europe_products │
│ europe_shipments │Dynamic routing from topics without a routing field 🔗
The above is neat, but what if we are sending data from Kafka topics that haven’t been populated by Debezium? In that case we won’t be able to rely on having the name of a source table to assume as the name for the target Iceberg table. Consider this Kafka topic, based on the one at the opening of this article:
{
"order_id": "001",
"customer_id": "cust_123",
"product": "laptop",
"quantity": 1,
"price": 999.99
}No target topic name anywhere in the schema.
If it’s just one topic, we can hardcode the iceberg.tables value.
But what about if we’ve got more topics like this, perhaps products_json too?
{
"product_id": "prod_001",
"name": "Gaming Laptop",
"category": "Electronics",
"price": 1299.99,
"stock": 15
}We could run two Kafka Connect Iceberg sinks, but that’d be missing the point of the ability of Kafka Connect to work with multiple sources and targets. We’d also end up with a lot of repeated configuration to align across the sinks. And what about if we then add another table? Create another sink?
Ideally we want to do something like this, and pick up all topics matching a pattern, such as any that end in _json:
"topics.regex": ".*\_json",But how to route them sensibly to an Iceberg table based on their topic name, rather than a field within the payload itself (which is what the Iceberg sink’s dynamic routing is based on).
SMTs to the rescue again!
This time one that’s built into Kafka Connect: InsertField
"transforms" : "insertTopic",
"transforms.insertTopic.type" : "org.apache.kafka.connect.transforms.InsertField$Value",
"transforms.insertTopic.topic.field" : "srcTopic"Putting it together into a Sink connector config looks like this:
$ kcctl apply -f - <<EOF
{
"name": "iceberg-sink-json-topics",
"config": {
"connector.class": "io.tabular.iceberg.connect.IcebergSinkConnector",
"topics.regex": ".*_json",
"iceberg.tables.dynamic-enabled": "true",
"iceberg.tables.route-field":"srcTopic",
"iceberg.tables.auto-create-enabled": "true",
"iceberg.tables.evolve-schema-enabled": "true",
"iceberg.catalog.catalog-impl": "org.apache.iceberg.aws.glue.GlueCatalog",
"iceberg.catalog.warehouse": "s3://rmoff-lakehouse/02/",
"iceberg.catalog.io-impl": "org.apache.iceberg.aws.s3.S3FileIO",
"key.converter":"org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable":"false",
"value.converter":"org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable":"false",
"iceberg.control.commit.interval-ms": "1000",
"transforms" : "insertTopic",
"transforms.insertTopic.type" : "org.apache.kafka.connect.transforms.InsertField\$Value",
"transforms.insertTopic.topic.field" : "srcTopic"
}
}
EOFUnfortunately this fails:
java.lang.IllegalArgumentException: Invalid table identifier: products_jsonThat’s because an Iceberg table needs to be qualified by its database.
There’s no way that I can see in the connector to specify a default database.
There’s also no way in the InsertField SMT to insert both some static text (the database qualifier) and the dynamic topic name
Argh!
Unless…unless…we change the topic name in-flight first:
"transforms" : "addDbPrefix",
"transforms.addDbPrefix.type" : "org.apache.kafka.connect.transforms.RegexRouter",
"transforms.addDbPrefix.regex" : ".*",
"transforms.addDbPrefix.replacement" : "rmoff_db.$0"Let’s chain these together and see.
$ kcctl apply -f - <<EOF
{
"name": "iceberg-sink-json-topics",
"config": {
"connector.class": "io.tabular.iceberg.connect.IcebergSinkConnector",
"topics.regex": ".*_json",
"iceberg.tables.dynamic-enabled": "true",
"iceberg.tables.route-field":"srcTopic",
"iceberg.tables.auto-create-enabled": "true",
"iceberg.tables.evolve-schema-enabled": "true",
"iceberg.catalog.catalog-impl": "org.apache.iceberg.aws.glue.GlueCatalog",
"iceberg.catalog.warehouse": "s3://rmoff-lakehouse/02/",
"iceberg.catalog.io-impl": "org.apache.iceberg.aws.s3.S3FileIO",
"key.converter":"org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable":"false",
"value.converter":"org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable":"false",
"iceberg.control.commit.interval-ms": "1000",
"transforms" : "addDbPrefix, insertTopic",
"transforms.addDbPrefix.type" : "org.apache.kafka.connect.transforms.RegexRouter",
"transforms.addDbPrefix.regex" : ".*",
"transforms.addDbPrefix.replacement" : "rmoff_db.$0",
"transforms.insertTopic.type" : "org.apache.kafka.connect.transforms.InsertField\$Value",
"transforms.insertTopic.topic.field" : "srcTopic"
}
}
EOFWhat happened next may surprise you! It certainly had me scratching my head.
Caused by: java.lang.IllegalArgumentException: Invalid table identifier: rmoff_db.-zshWuuuuh… eh?!
Where has -zsh come from??
In short, I hadn’t escaped the $ of the $0 in my config, meaning that $0 was interpreted as a special shell parameter and replaced with -zsh when it was passed to kcctl.
We can validate this by looking closely at the kcctl describe connector output:
$ kcctl describe connector iceberg-sink-json-topics
Name: iceberg-sink-json-topics
Type: sink
State: RUNNING
Worker ID: kafka-connect:8083
Config:
[…]
transforms.addDbPrefix.replacement: rmoff_db.-zshLet’s escape the $ and try again:
$ kcctl apply -f - <<EOF
{
"name": "iceberg-sink-json-topics",
"config": {
"connector.class": "io.tabular.iceberg.connect.IcebergSinkConnector",
"topics.regex": ".*_json",
"iceberg.tables.dynamic-enabled": "true",
"iceberg.tables.route-field":"srcTopic",
"iceberg.tables.auto-create-enabled": "true",
"iceberg.tables.evolve-schema-enabled": "true",
"iceberg.catalog.catalog-impl": "org.apache.iceberg.aws.glue.GlueCatalog",
"iceberg.catalog.warehouse": "s3://rmoff-lakehouse/02/",
"iceberg.catalog.io-impl": "org.apache.iceberg.aws.s3.S3FileIO",
"key.converter":"org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable":"false",
"value.converter":"org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable":"false",
"iceberg.control.commit.interval-ms": "1000",
"transforms" : "addDbPrefix, insertTopic",
"transforms.addDbPrefix.type" : "org.apache.kafka.connect.transforms.RegexRouter",
"transforms.addDbPrefix.regex" : ".*",
"transforms.addDbPrefix.replacement" : "rmoff_db.\$0",
"transforms.insertTopic.type" : "org.apache.kafka.connect.transforms.InsertField\$Value",
"transforms.insertTopic.topic.field" : "srcTopic"
}
}
EOFAs if by magic:
🟡◗ show tables;
┌───────────────────────────┐
│ name │
│ varchar │
├───────────────────────────┤
│ orders_json │
│ products_json │
[…]|
At this point though, the news isn’t so good. Whilst the tables are created in the catalog as shown above, only the data files and initial metadata are written to storage; no snapshot is created by the commit process. I’ve logged this as a bug (#13457) that seems to be related to the use of SMTs to populate the field used by Dynamic routing does work—as I showed above—if you’re using |
N:1 (Fan In / Writing many topics to one table) 🔗
Let’s now look at a variation on the above. Instead of many topics written each to their own table, what about multiple topics writing to the same table?
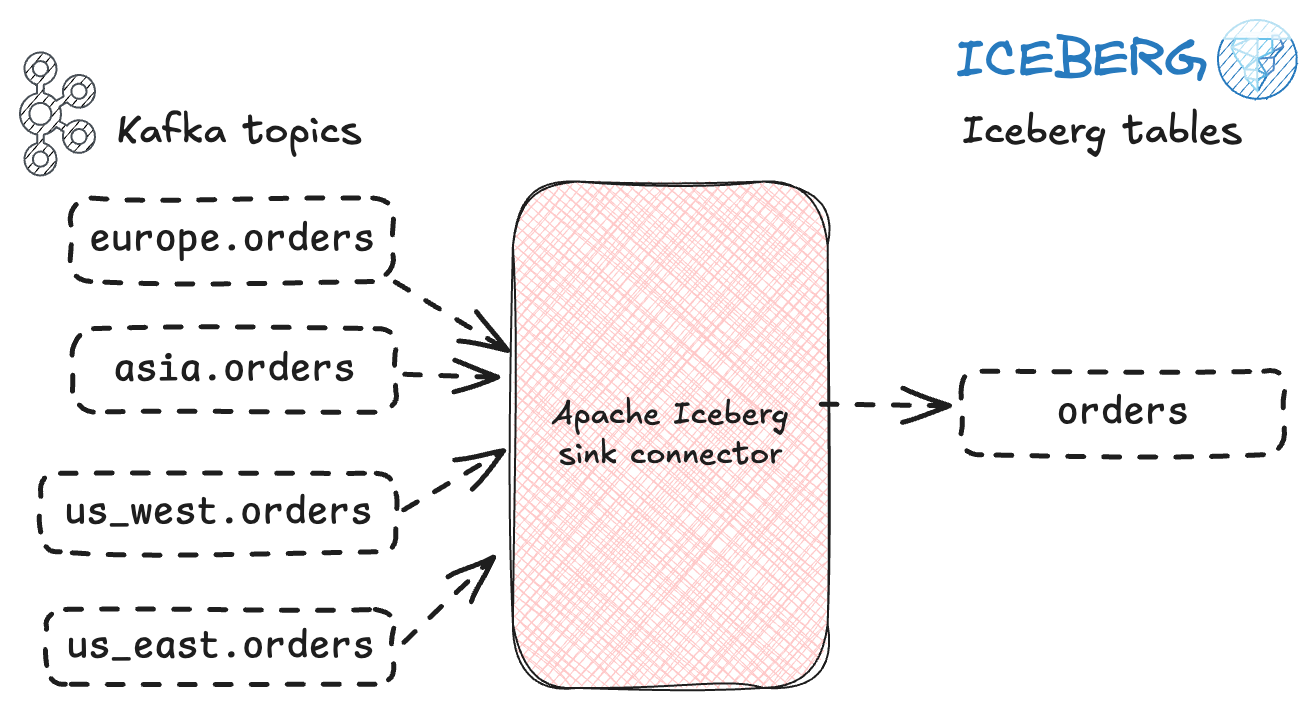
This is a common requirement when data is sharded across geographies or business units, for example. I’m using Postgres again as my source example, but this could equally just be any Kafka topic populated by any application.
In this example there is an instance of the orders table across multiple schemas:
table_schema | table_name
--------------+------------
asia | orders
europe | orders
us_east | orders
us_west | orders
(4 rows)With Debezium we capture these into four Kafka topics (by specifying a regex "table.include.list": ".*orders"):
$ kcctl apply -f - <<EOF
{
"name": "postgres-orders",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "postgres",
"database.port": "5432",
"database.user": "postgres",
"database.password": "Welcome123",
"database.dbname": "postgres",
"table.include.list": ".*orders",
"topic.prefix": "dbz-avro",
"key.converter": "io.confluent.connect.avro.AvroConverter",
"key.converter.schema.registry.url": "http://schema-registry:8081",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "http://schema-registry:8081"
}
}
EOF$ kcctl describe connector postgres-orders
Name: postgres-orders
Type: source
State: RUNNING
Worker ID: kafka-connect:8083
Config:
connector.class: io.debezium.connector.postgresql.PostgresConnector
[…]
Topics:
dbz-avro.asia.orders
dbz-avro.europe.orders
dbz-avro.us_east.orders
dbz-avro.us_west.ordersNow we can create a single Iceberg sink which will read from any orders topic (based on our regex), and write to a single orders Iceberg table.
$ kcctl apply -f - <<EOF
{
"name": "iceberg-sink-postgres-orders",
"config": {
"connector.class": "io.tabular.iceberg.connect.IcebergSinkConnector",
"topics.regex": "dbz-avro..*orders",
"iceberg.tables": "rmoff_db.orders",
"iceberg.tables.auto-create-enabled": "true",
"iceberg.tables.evolve-schema-enabled": "true",
"iceberg.catalog.catalog-impl": "org.apache.iceberg.aws.glue.GlueCatalog",
"iceberg.catalog.warehouse": "s3://rmoff-lakehouse/02/",
"iceberg.catalog.io-impl": "org.apache.iceberg.aws.s3.S3FileIO",
"key.converter": "io.confluent.connect.avro.AvroConverter",
"key.converter.schema.registry.url": "http://schema-registry:8081",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "http://schema-registry:8081",
"iceberg.control.commit.interval-ms": "1000",
"transforms": "dbz",
"transforms.dbz.type": "io.tabular.iceberg.connect.transforms.DebeziumTransform"
}
}
EOFThis works as it should, and we have an orders table on it with the expected data.
Because we have the _cdc field we can also get the source table easily:
🟡◗ SELECT _cdc.source AS src_table, id, customer_name, quantity, price
FROM orders;
┌────────────────┬───────┬──────────────────┬──────────┬───────────────┐
│ src_table │ id │ customer_name │ quantity │ price │
│ varchar │ int32 │ varchar │ int32 │ decimal(38,2) │
├────────────────┼───────┼──────────────────┼──────────┼───────────────┤
│ us_east.orders │ 2 │ Bruce Wayne │ 1 │ 299.99 │
│ us_west.orders │ 1 │ Scott Lang │ 1 │ 179.99 │
│ us_west.orders │ 3 │ Steve Rogers │ 1 │ 249.99 │
│ us_west.orders │ 4 │ Wanda Maximoff │ 1 │ 199.99 │
│ us_west.orders │ 2 │ Natasha Romanoff │ 2 │ 129.99 │
│ us_west.orders │ 5 │ Carol Danvers │ 1 │ 399.99 │
│ asia.orders │ 4 │ Luke Cage │ 1 │ 69.99 │
│ europe.orders │ 2 │ Barry Allen │ 1 │ 79.99 │
│ europe.orders │ 1 │ Arthur Curry │ 1 │ 189.99 │
[…]Let’s check the row counts match too. Here’s the source, in Postgres:
WITH all_tables AS (SELECT COUNT(*) AS ct FROM asia.orders UNION ALL
SELECT COUNT(*) AS ct FROM europe.orders UNION ALL
SELECT COUNT(*) AS ct FROM us_east.orders UNION ALL
SELECT COUNT(*) AS ct FROM us_west.orders)
SELECT SUM(ct) FROM all_tables;
sum
-----
20
(1 row)and the target Iceberg table:
🟡◗ SELECT COUNT(*) from orders;
┌──────────────┐
│ count_star() │
│ int64 │
├──────────────┤
│ 20 │
└──────────────┘|
You may notice that in the above example the Another option is to perform this concatenation in-flight with a custom SMT, or to pre-process the topic using Flink SQL. |
1:N (Fan Out / Writing one topic to many tables) 🔗
The inverse of the above process is taking one topic and writing it out to multiple Iceberg tables.
This is what the built-in Iceberg route-field is designed for, and works simply enough.
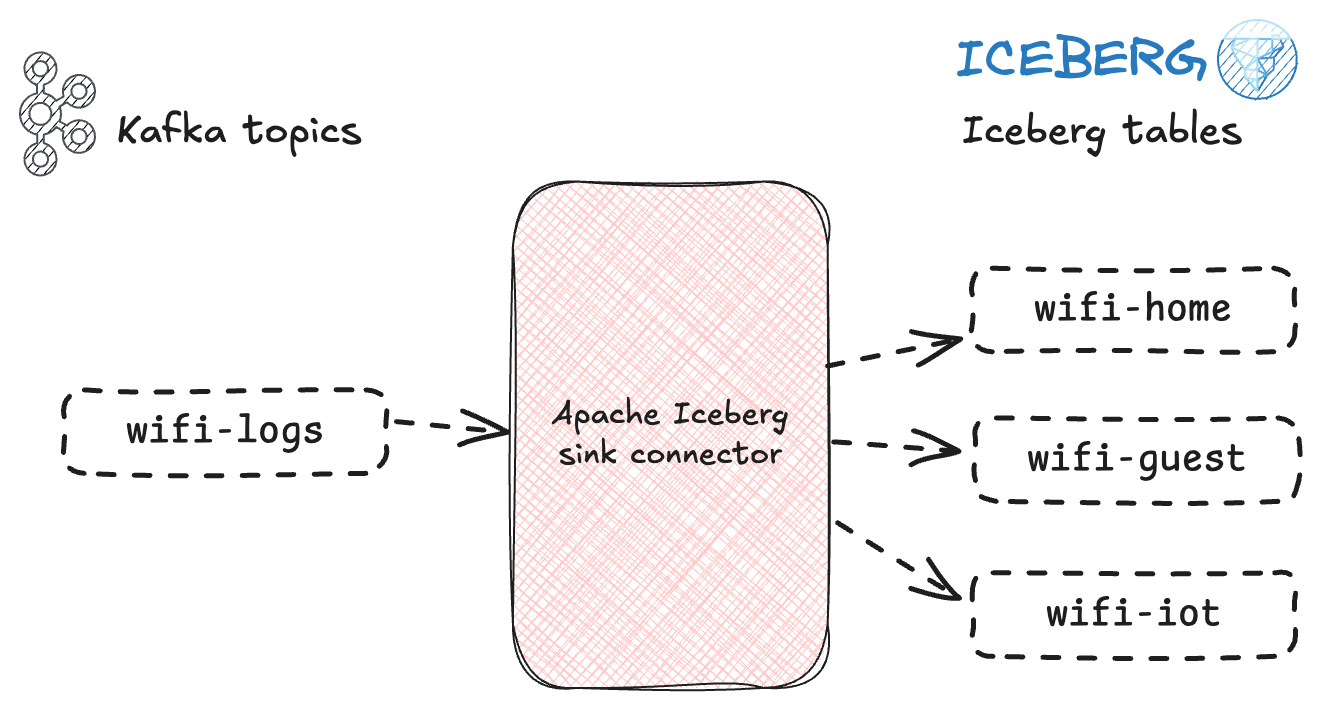
Imagine you’ve got a Kafka topic wifi-logs that holds wifi data:
{"target":"wifi-logs","timestamp":"2025-07-04T10:30:15Z","device_mac":"aa:bb:cc:dd:ee:01","ssid":"HomeNetwork","category":"web_browsing","bytes":1024}
{"target":"wifi-logs","timestamp":"2025-07-04T10:30:45Z","device_mac":"aa:bb:cc:dd:ee:02","ssid":"HomeNetwork","category":"video_streaming","bytes":5120}
{"target":"wifi-logs","timestamp":"2025-07-04T10:31:12Z","device_mac":"aa:bb:cc:dd:ee:03","ssid":"GuestNetwork","category":"social_media","bytes":512}
{"target":"wifi-logs","timestamp":"2025-07-04T10:31:33Z","device_mac":"aa:bb:cc:dd:ee:04","ssid":"HomeNetwork","category":"gaming","bytes":2048}
{"target":"wifi-logs","timestamp":"2025-07-04T10:32:01Z","device_mac":"aa:bb:cc:dd:ee:05","ssid":"HomeNetwork","category":"file_download","bytes":8192}'Now we want to send this data to Iceberg, but split it out by network.
To do this we specify the ssid as the route-field in the Iceberg sink:
$ kcctl apply -f - <<EOF
{
"name": "iceberg-sink-wifi-logs",
"config": {
"connector.class": "io.tabular.iceberg.connect.IcebergSinkConnector",
"topics.regex": "wifi-logs",
"iceberg.tables.dynamic-enabled": "true",
"iceberg.tables.route-field":"ssid",
"iceberg.tables.auto-create-enabled": "true",
"iceberg.tables.evolve-schema-enabled": "true",
"iceberg.catalog.catalog-impl": "org.apache.iceberg.aws.glue.GlueCatalog",
"iceberg.catalog.warehouse": "s3://rmoff-lakehouse/02/",
"iceberg.catalog.io-impl": "org.apache.iceberg.aws.s3.S3FileIO",
"iceberg.control.commit.interval-ms": "1000",
"key.converter":"org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable":"false",
"value.converter":"org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable":"false"
}
}
EOFUnfortunately this hits the same problem as above; the route-field value must be a fully qualified table name.
Caused by: java.lang.IllegalArgumentException: Invalid table identifier: homenetworkWhereas above we had data from Debezium and we could fudge the route-field value to include a database by making use of the DebeziumTransform configuration, here we don’t have that option.
We need an SMT similar to that mentioned just before in the context of unique field values for a Fan-In scenario: an SMT that will concatenate a field’s value with another (or a static value, in this case). That, or the option to specify a default database as part of the Iceberg sink configuration.
But, we’ve still got a job to do—so let’s work around the problem.
Turning to Flink SQL, we can map a Flink table to the original Kafka topic:
CREATE TABLE wifi_logs (
target VARCHAR(50) NOT NULL, `timestamp` VARCHAR(50) NOT NULL,
device_mac VARCHAR(17) NOT NULL, ssid VARCHAR(255) NOT NULL,
category VARCHAR(100) NOT NULL, `bytes` INTEGER NOT NULL
) WITH (
'connector' = 'kafka',
'topic' = 'wifi-logs',
'properties.bootstrap.servers' = 'broker:9092',
'format' = 'json', 'scan.startup.mode' = 'earliest-offset'
);and then populate a new Flink table (writing to a Kafka topic) with the required field:
CREATE TABLE wifi_logs_with_db_tb
WITH (
'connector' = 'kafka',
'topic' = 'wifi_logs_with_db_tb',
'properties.bootstrap.servers' = 'broker:9092',
'format' = 'json', 'scan.startup.mode' = 'earliest-offset'
) AS
SELECT *,
'rmoff_db.' || ssid AS target_table
FROM `wifi_logs`;Here’s a sample message from the resulting topic:
{
"target": "wifi-logs",
"timestamp": "2025-07-04T10:30:15Z",
"device_mac": "aa:bb:cc:dd:ee:01",
"ssid": "HomeNetwork",
"category": "web_browsing",
"bytes": 1024,
"target_table": "rmoff_db.HomeNetwork" (1)
}| 1 | Here’s our new field created for the purpose of the route-field configuration |
Now let’s try it with the Iceberg sink:
$ kcctl apply -f - <<EOF
{
"name": "iceberg-sink-wifi-logs",
"config": {
"connector.class": "io.tabular.iceberg.connect.IcebergSinkConnector",
"topics": "wifi_logs_with_db_tb",
"iceberg.tables.dynamic-enabled": "true", (1)
"iceberg.tables.route-field":"target_table", (2)
"iceberg.tables.auto-create-enabled": "true",
"iceberg.tables.evolve-schema-enabled": "true",
"iceberg.catalog.catalog-impl": "org.apache.iceberg.aws.glue.GlueCatalog",
"iceberg.catalog.warehouse": "s3://rmoff-lakehouse/02/",
"iceberg.catalog.io-impl": "org.apache.iceberg.aws.s3.S3FileIO",
"iceberg.control.commit.interval-ms": "1000",
"key.converter":"org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable":"false",
"value.converter":"org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable":"false"
}
}
EOF| 1 | Use dynamic routing |
| 2 | Use the new target_table to define the target table to which to write the data |
The tables have been created…
$ aws glue get-tables --database-name rmoff_db --region us-east-1 \
--query 'TableList[].Name' --output table
+--------------------+
| GetTables |
+--------------------+
| guestnetwork |
| homenetwork |…and populated 🎉
🟡◗ SELECT * FROM homenetwork;
┌───────────────────┬───────┬──────────────────────┬─────────────────┬─────────────┬────────[…]
│ device_mac │ bytes │ target_table │ category │ ssid │ target[…]
│ varchar │ int64 │ varchar │ varchar │ varchar │ varcha[…]
├───────────────────┼───────┼──────────────────────┼─────────────────┼─────────────┼────────[…]
│ aa:bb:cc:dd:ee:01 │ 1024 │ rmoff_db.HomeNetwork │ web_browsing │ HomeNetwork │ wifi-lo[…]
│ aa:bb:cc:dd:ee:02 │ 5120 │ rmoff_db.HomeNetwork │ video_streaming │ HomeNetwork │ wifi-lo[…]
│ aa:bb:cc:dd:ee:04 │ 2048 │ rmoff_db.HomeNetwork │ gaming │ HomeNetwork │ wifi-lo[…]
│ aa:bb:cc:dd:ee:05 │ 8192 │ rmoff_db.HomeNetwork │ file_download │ HomeNetwork │ wifi-lo[…]
└───────────────────┴───────┴──────────────────────┴─────────────────┴─────────────┴────────[…]
Run Time (s): real 2.671 user 0.181888 sys 0.060846
🟡◗ SELECT * FROM guestnetwork;
┌───────────────────┬───────┬───────────────────────┬──────────────┬──────────────┬─────────[…]
│ device_mac │ bytes │ target_table │ category │ ssid │ target […]
│ varchar │ int64 │ varchar │ varchar │ varchar │ varchar[…]
├───────────────────┼───────┼───────────────────────┼──────────────┼──────────────┼─────────[…]
│ aa:bb:cc:dd:ee:03 │ 512 │ rmoff_db.GuestNetwork │ social_media │ GuestNetwork │ wifi-log[…]
└───────────────────┴───────┴───────────────────────┴──────────────┴──────────────┴─────────[…]
Run Time (s): real 2.544 user 0.108161 sys 0.020404
🟡◗Selective syncing of Kafka records to Iceberg 🔗
The last thing I want to show you is using SMT to conditionally send data to the Iceberg sink.
Looking at the same example of wifi-log data, here’s how you’d create a sink connector to only send records where the ssid is HomeNetwork.
This uses the Filter SMT, combined with an optional Predicate so that Filter will conditionally drop records.
The predicate is built using a community plugin called MatchesJMESPath, and provides a way to specify conditional matches against field values.
$ kcctl apply -f - <<EOF
{
"name": "iceberg-sink-wifi-logs-HomeNetwork",
"config": {
"connector.class": "io.tabular.iceberg.connect.IcebergSinkConnector",
"topics": "wifi-logs",
"iceberg.tables.dynamic-enabled": "false",
"iceberg.tables":"tmp.wifi_logs_home_network_only", (1)
"iceberg.tables.auto-create-enabled": "true",
"iceberg.tables.evolve-schema-enabled": "true",
"iceberg.catalog.catalog-impl": "org.apache.iceberg.aws.glue.GlueCatalog",
"iceberg.catalog.warehouse": "s3://rmoff-lakehouse/05/",
"iceberg.catalog.io-impl": "org.apache.iceberg.aws.s3.S3FileIO",
"iceberg.control.commit.interval-ms": "1000",
"key.converter":"org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable":"false",
"value.converter":"org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable":"false",
"transforms": "filterHomeNetwork", (2)
"transforms.filterHomeNetwork.type": "org.apache.kafka.connect.transforms.Filter", (3)
"transforms.filterHomeNetwork.predicate": "notHomeNetwork", (4)
"predicates": "notHomeNetwork", (5)
"predicates.notHomeNetwork.type": "de.denisw.kafka.connect.jmespath.MatchesJMESPath\$Value", (6)
"predicates.notHomeNetwork.query": "ssid != 'HomeNetwork'" (7)
}
}
EOF| 1 | Write the resulting records to the tmp.wifi_logs_home_network_only table |
| 2 | List of transformation names |
| 3 | Use a Filter transform |
| 4 | Only apply the transform to the current record if the predicate notHomeNetwork is true |
| 5 | List of predicate names |
| 6 | Use the MatchesJMESPath predicate on the Value part of the record (i.e. not the key or header) |
| 7 | The predicate is true if the ssid field does not equal HomeNetwork |
When you run this sink you get an Iceberg table with only the HomeNetwork wifi data in it:
🟡◗ SELECT * FROM wifi_logs_home_network_only;
┌───────────────────┬───────┬─────────────────┬─────────────┬───────────┬──────────────────────┐
│ device_mac │ bytes │ category │ ssid │ target │ timestamp │
│ varchar │ int64 │ varchar │ varchar │ varchar │ varchar │
├───────────────────┼───────┼─────────────────┼─────────────┼───────────┼──────────────────────┤
│ aa:bb:cc:dd:ee:01 │ 1024 │ web_browsing │ HomeNetwork │ wifi-logs │ 2025-07-04T10:30:15Z │
│ aa:bb:cc:dd:ee:02 │ 5120 │ video_streaming │ HomeNetwork │ wifi-logs │ 2025-07-04T10:30:45Z │
│ aa:bb:cc:dd:ee:04 │ 2048 │ gaming │ HomeNetwork │ wifi-logs │ 2025-07-04T10:31:33Z │Appendices 🔗
Debugging 🔗
You can increase the log level of the Kafka Connect worker for specific components:
http PUT localhost:8083/admin/loggers/org.apache.iceberg.metrics Content-Type:application/json level=TRACE
http PUT localhost:8083/admin/loggers/org.apache.iceberg.aws Content-Type:application/json level=TRACESee Changing the Logging Level for Kafka Connect Dynamically for more detail.
It can be useful for inspection of SMTs:
curl -s -X PUT http://localhost:8083/admin/loggers/org.apache.kafka.connect.runtime.TransformationChain -H "Content-Type:application/json" -d '{"level": "TRACE"}'You’ll then see in the logs something like this:
Applying transformation io.tabular.iceberg.connect.transforms.DebeziumTransform to
SinkRecord{kafkaOffset=2, timestampType=CreateTime, originalTopic=dbz-avro.public.clicks_no_tz, originalKafkaPartition=1, originalKafkaOffset=2}
ConnectRecord{topic='dbz-avro.public.clicks_no_tz', kafkaPartition=1, key=null, keySchema=null,
value=Struct{after=Struct{click_ts=1675258225000000,ad_cost=1.50,is_conversion=true,user_id=001234567890},source=Struct{version=3.1.2.Final,connector=postgresql,name=dbz-avro,ts_ms=1751471423083,snapshot=false,db=postgres,sequence=["34643256","34643544"],ts_us=1751471423083360,ts_ns=1751471423083360000,schema=public,table=clicks_no_tz,txId=780,lsn=34643544},op=c,ts_ms=1751471423553,ts_us=1751471423553059,ts_ns=1751471423553059129},
valueSchema=Schema{dbz-avro.public.clicks_no_tz.Envelope:STRUCT}, timestamp=1751471423743, headers=ConnectHeaders(headers=)}
Applying transformation org.apache.kafka.connect.transforms.TimestampConverter$Value to
SinkRecord{kafkaOffset=2, timestampType=CreateTime, originalTopic=dbz-avro.public.clicks_no_tz, originalKafkaPartition=1, originalKafkaOffset=2}
ConnectRecord{topic='dbz-avro.public.clicks_no_tz', kafkaPartition=1, key=null, keySchema=null,
value=Struct{click_ts=1675258225000000,ad_cost=1.50,is_conversion=true,user_id=001234567890,_cdc=Struct{op=I,ts=Wed Jul 02 15:50:23 GMT 2025,offset=2,source=public.clicks_no_tz,target=public.clicks_no_tz}},
valueSchema=Schema{dbz-avro.public.clicks_no_tz.Value:STRUCT}, timestamp=1751471423743, headers=ConnectHeaders(headers=)}You can also use the kafka-connect-simulator sink connector to test your SMTs:
kcctl apply -f - <<EOF
{
"name": "smt-test",
"config": {
"connector.class": "com.github.jcustenborder.kafka.connect.simulator.SimulatorSinkConnector",
"topics": "wifi-logs",
"log.entries": "true",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": "false",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": "false",
"transforms": "addDbPrefix, insertTopic",
"transforms.addDbPrefix.type": "org.apache.kafka.connect.transforms.RegexRouter",
"transforms.addDbPrefix.regex": ".*",
"transforms.addDbPrefix.replacement": "rmoff_db.\$0",
"transforms.insertTopic.type": "org.apache.kafka.connect.transforms.InsertField\$Value",
"transforms.insertTopic.topic.field": "srcTopic"
}
}
EOFWhen you create this you’ll see in the Kafka Connect worker logs the actual records that a sink will be working with after the SMTs have been applied:
[2025-07-04 09:49:41,542] INFO [test2|task-0] record.value={device_mac=aa:bb:cc:dd:ee:01, bytes=1024, srcTopic=rmoff_db.wifi-logs, category=web_browsing, ssid=HomeNetwork, target=wifi-logs, timestamp=2025-07-04T10:30:15Z} (com.github.jcustenborder.kafka.connect.simulator.SimulatorSinkTask:50) │
[2025-07-04 09:49:41,542] INFO [test2|task-0] record.value={device_mac=aa:bb:cc:dd:ee:02, bytes=5120, srcTopic=rmoff_db.wifi-logs, category=video_streaming, ssid=HomeNetwork, target=wifi-logs, timestamp=2025-07-04T10:30:45Z} (com.github.jcustenborder.kafka.connect.simulator.SimulatorSinkTask:50) │
[2025-07-04 09:49:41,542] INFO [test2|task-0] record.value={device_mac=aa:bb:cc:dd:ee:03, bytes=512, srcTopic=rmoff_db.wifi-logs, category=social_media, ssid=GuestNetwork, target=wifi-logs, timestamp=2025-07-04T10:31:12Z} (com.github.jcustenborder.kafka.connect.simulator.SimulatorSinkTask:50) │Kafka Connect version problems 🔗
I saw this error from the connector:
java.lang.NoSuchMethodError: 'org.apache.kafka.clients.admin.ListConsumerGroupOffsetsOptions org.apache.kafka.clients.admin.ListConsumerGroupOffsetsOptions.requireStable(boolean)'
at io.tabular.iceberg.connect.channel.CommitterImpl.fetchStableConsumerOffsets(CommitterImpl.java:116)
at io.tabular.iceberg.connect.channel.CommitterImpl.<init>(CommitterImpl.java:97)
at io.tabular.iceberg.connect.channel.CommitterImpl.<init>(CommitterImpl.java:70)
at io.tabular.iceberg.connect.channel.CommitterImpl.<init>(CommitterImpl.java:62)
at io.tabular.iceberg.connect.channel.TaskImpl.<init>(TaskImpl.java:37)
at io.tabular.iceberg.connect.IcebergSinkTask.open(IcebergSinkTask.java:56)
at org.apache.kafka.connect.runtime.WorkerSinkTask.openPartitions(WorkerSinkTask.java:637)
at org.apache.kafka.connect.runtime.WorkerSinkTask.access$1200(WorkerSinkTask.java:72)This happened with cp-kafka-connect 7.2.15.
Switching to 8.0.0 resolved the problem.
Documentation and Links 🔗
-
Confluent Hub: Apache Iceberg sink
-
This blog: SMT articles