
This is a quick blog post to remind me how to connect Apache Flink to a Kafka topic on Confluent Cloud. You may wonder why you’d want to do this, given that Confluent Cloud for Apache Flink is a much easier way to run Flink SQL. But, for whatever reason, you’re here and you want to understand the necessary incantations to get this connectivity to work.
There are two versions of this connectivity - with, and without, using the Schema Registry for Avro.
MVP: Just connect to a Kafka topic; no Avro. 🔗
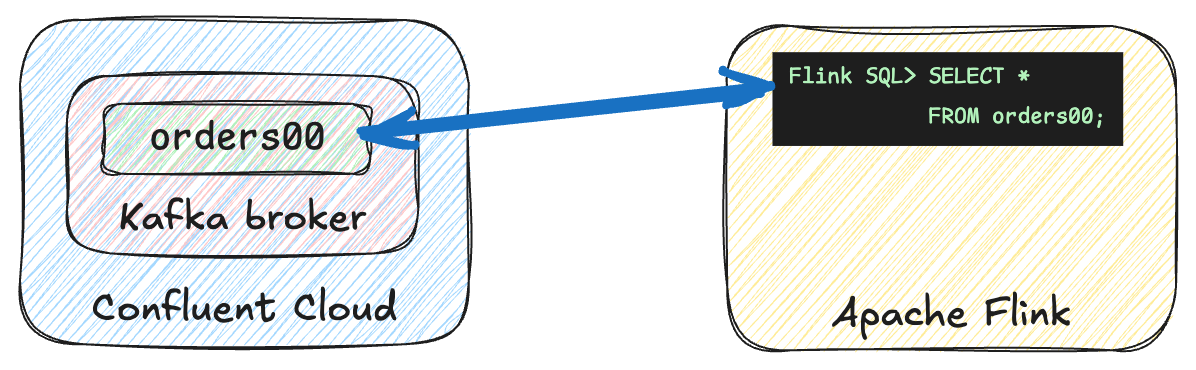
Get the broker endpoint and API key 🔗
First off, you need to get two things:
-
The address of your Confluent Cloud broker
-
An API key pair with authorisation to access the topic that you want to read/write
I’m going to use the Confluent CLI to do this, but you can also use the web interface if you’d prefer (head to the Cluster Overview page).
Get a list of your Kafka clusters on Confluent Cloud:
$ confluent kafka cluster list
Current | ID | Name | Type | Cloud | Region | Availability […]
----------+------------+-----------+-----------+-------+-----------+--------------[…]
* | lkc-qnygo6 | cluster00 | STANDARD | aws | us-west-2 | single-zone […]
| lkc-v2p3j0 | dev | DEDICATED | aws | us-west-2 | single-zone […]Then describe the cluster on which your topic is, to get the Endpoint:
$ confluent kafka cluster describe lkc-qnygo6
+----------------------+---------------------------------------------------------+
| Current | true |
| ID | lkc-qnygo6 |
| Name | cluster00 |
[…]
| Endpoint | SASL_SSL://pkc-rgm37.us-west-2.aws.confluent.cloud:9092 |Now we’ll create an API key for accessing this broker.
Specify the ID of the cluster (e.g. lkc-qnygo6) as the resource to which the API key is to have access.
If you have one already then you can skip this step.
$ confluent api-key create --resource lkc-qnygo6 --description "Flink SQL (Kafka)"
It may take a couple of minutes for the API key to be ready.
Save the API key and secret. The secret is not retrievable later.
+------------+------------------------------------------------------------------+
| API Key | KAFKA_CLUSTER_API_KEY |
| API Secret | KAFKA_CLUSTER_API_SECRET |
+------------+------------------------------------------------------------------+|
In this blog post I’m obviuosly not going to show my real API key details :) Wherever you see So in this line: If your API key value is |
Create the Flink table 🔗
If you’re writing to a topic that doesn’t exist yet you’ll need to create it first:
$ confluent kafka topic create test_table --cluster lkc-qnygo6
Created topic "test_table".Then you can define a table over the topic:
CREATE TABLE test_table (
id INT,
col1 STRING)
WITH (
'topic' = 'test_table',
'connector' = 'kafka',
'scan.bounded.mode' = 'unbounded',
'scan.startup.mode' = 'earliest-offset',
'properties.bootstrap.servers' = 'pkc-rgm37.us-west-2.aws.confluent.cloud:9092', (1)
'properties.security.protocol' = 'SASL_SSL',
'properties.sasl.mechanism' = 'PLAIN',
'properties.sasl.jaas.config' = 'org.apache.flink.kafka.shaded.org.apache.kafka.common.security.plain.PlainLoginModule required username="KAFKA_CLUSTER_API_KEY" password="KAFKA_CLUSTER_API_SECRET";', (2)
'format'='json'
);| 1 | The endpoint of your Kafka cluster |
| 2 | The API key and secret for accessing your Kafka cluster |
…write data to it:
Flink SQL> INSERT INTO test_table VALUES (1,'a');…and query it:
Flink SQL> SELECT * FROM test_table;+----+-------------+--------------------------------+
| op | id | col1 |
+----+-------------+--------------------------------+
| +I | 1 | a |You can check the topic itself by consuming from it:
$ confluent api-key use KAFKA_CLUSTER_API_KEY
Using API Key "KAFKA_CLUSTER_API_KEY".
$ confluent kafka topic consume test_table --from-beginning
Starting Kafka Consumer. Use Ctrl-C to exit.
{"id":1,"col1":"a"}Using Schema Registry and Avro 🔗
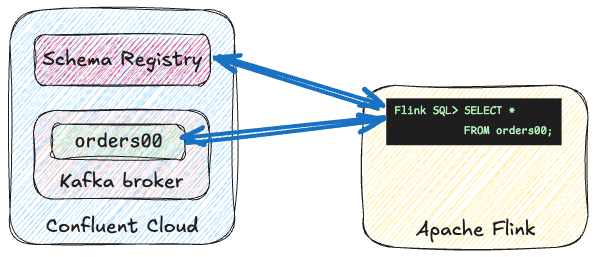
If you want to use the Schema Registry you’ll need to do a few more steps as well as the above.
-
Get the Schema Registry endpoint and API key details
-
Add the necessary JAR file to your Flink cluster
For the Schema Registry endpoint and API key pair it’s similar to what we did above for the Kafka cluster.
Get the Schema Registry endpoint:
$ confluent schema-registry cluster describe
+--------------------------------+----------------------------------------------------+
[…]
| Cluster | lsrc-g70zm3 |
| Endpoint URL | https://psrc-13go8y7.us-west-2.aws.confluent.cloud |Create an API key pair for accessing the Schema Registry, using the Cluster ID of the Schema Registry (not your Kafka cluster ID) as the resource:
$ confluent api-key create --resource lsrc-g70zm3 --description "Flink SQL (SR)"
It may take a couple of minutes for the API key to be ready.
Save the API key and secret. The secret is not retrievable later.
+------------+------------------------------------------------------------------+
| API Key | SCHEMA_REGISTRY_API_KEY |
| API Secret | SCHEMA_REGISTRY_API_SECRET |
+------------+------------------------------------------------------------------+Apache Flink doesn’t ship with support for Schema Registry Avro, but it is supported as a separate component.
If you’re using SQL Client (as I am here) you need to add the flink-sql-avro-confluent-registry JAR file to your deployment (e.g. by putting it in the /lib folder of your Flink cluster nodes).
Make sure that you use the correct version of the file for the version of Flink that you’re running!
The one linked to here is for 1.20.2.
With the JAR installed and your cluster rebooted, you’re ready to create a table on a topic serialised using Schema Registry Avro:
CREATE TABLE orders00 (
`order_id` VARCHAR(2147483647) NOT NULL,
`customer_id` INT NOT NULL,
`product_id` VARCHAR(2147483647) NOT NULL,
`price` DOUBLE NOT NULL
)
WITH (
'topic' = 'orders00',
'connector' = 'kafka',
'scan.bounded.mode' = 'unbounded',
'scan.startup.mode' = 'earliest-offset',
'properties.bootstrap.servers' = 'pkc-rgm37.us-west-2.aws.confluent.cloud:9092', (1)
'properties.security.protocol' = 'SASL_SSL',
'properties.sasl.mechanism' = 'PLAIN',
'properties.sasl.jaas.config' = 'org.apache.flink.kafka.shaded.org.apache.kafka.common.security.plain.PlainLoginModule required username="KAFKA_CLUSTER_API_KEY" password="KAFKA_CLUSTER_API_SECRET";', (2)
'format' = 'avro-confluent',
'avro-confluent.url' = 'https://psrc-13go8y7.us-west-2.aws.confluent.cloud', (3)
'avro-confluent.basic-auth.credentials-source' = 'USER_INFO',
'avro-confluent.basic-auth.user-info' = 'SCHEMA_REGISTRY_API_KEY:SCHEMA_REGISTRY_API_SECRET' (4)
);| 1 | The endpoint of your Kafka cluster |
| 2 | The API key and secret for accessing your Kafka cluster |
| 3 | The endpoint of your Schema Registry |
| 4 | The API key and secret for accessing your Schema Registry |
Query the table:
Flink SQL> SELECT * FROM orders00 LIMIT 5;+----+--------------------------------+-------------+-------------+---------+
| op | order_id | customer_id | product_id | price |
+----+--------------------------------+-------------+-------------+---------+
| +I | 8581b9ab-6c6c-42c0-8d69-252... | 3049 | 1349 | 29.32 |
| +I | 91b69bd2-8c23-4380-b6b4-dc0... | 3160 | 1477 | 43.59 |
| +I | e0f3d4af-a626-47a3-b8a1-c09... | 3245 | 1113 | 37.72 |
| +I | 3eec7aea-ff5a-4852-a357-1ce... | 3220 | 1401 | 92.44 |
| +I | 3fe99471-6ea8-4add-86f8-16e... | 3006 | 1195 | 68.66 |Validating your cluster and API details using kcat 🔗
As well as the Confluent CLI, you can also use kcat to check that the cluster details you’re specifying in your Flink SQL DDL are correct.
Here’s an example of querying the same orders00 topic as above, using kcat:
docker run --rm --tty edenhill/kcat:1.7.1 \
-b pkc-rgm37.us-west-2.aws.confluent.cloud:9092 \
-X security.protocol=sasl_ssl -X sasl.mechanisms=PLAIN \
-X sasl.username=KAFKA_CLUSTER_API_KEY -X sasl.password=KAFKA_CLUSTER_API_SECRET \
-s avro -r https://SCHEMA_REGISTRY_API_KEY:SCHEMA_REGISTRY_API_SECRET@psrc-13go8y7.us-west-2.aws.confluent.cloud \
-C -t orders00 -c5{"order_id": "670214e7-65e9-4d71-aabe-6b67a83c6a94", "customer_id": 3053, "product_id": "1269", "price": 38.409999999999997}
{"order_id": "4785a9f2-2529-4315-8f85-acd01ccf01de", "customer_id": 3205, "product_id": "1268", "price": 34.149999999999999}
{"order_id": "6126f74f-b72a-469e-b4f2-03961950e1aa", "customer_id": 3086, "product_id": "1260", "price": 77.280000000000001}
{"order_id": "f308e7cb-1be3-47bc-8fdc-42b6e8b7035e", "customer_id": 3196, "product_id": "1166", "price": 79.950000000000003}
{"order_id": "9908d516-441f-4db1-8378-f61713118c34", "customer_id": 3139, "product_id": "1429", "price": 48.0}