
You’ve got data in Apache Kafka.
You want to get that data into Apache Iceberg.
What’s the best way to do it?

Perhaps invariably, the answer is: IT DEPENDS. But fear not: here is a guide to help you navigate your way to choosing the best solution for you 🫵.
The Candidates 🔗
I’m considering three technologies in this blog post:
-
Apache Flink SQL (open source)
-
Kafka Connect (open source)
There are others, and I’ll mention those at the end. The one that I’ve really not looked at, and is perhaps conspicuous by its absence, is Apache Spark. If you’re interested in Spark, check out this video from Danica Fine in which she covers it.
| Disclaimer: I work for Confluent, but will do my best to remain impartial in this article. 😀 |
The Approach 🔗
I’ve framed this blog post around the key areas that you can use as the basis for making your decision. Some of these will be show-stoppers and rule a particular option out, whilst others are simply gentle nudges that one tool might be preferred over another.
I’m going to break the areas of consideration down into two (and a bit) areas:
-
Your data: including where it’s from, what you’re doing with it, how it’s structured, and how many topics
-
Living with it: important factors such as what’s your existing deployment (if any), preference for self-managed vs SaaS, and table maintenance
-
Other: licensing, support for other formats, other bits and pieces
Tool overview 🔗
Before we get into it, let’s take a quick look at what the three tools are and how they integrate with Iceberg.
Apache Flink SQL 🔗
| Read more: Writing to Apache Iceberg using Flink SQL |
Flink SQL jobs run on a Flink cluster. They do not require Kafka (unless you are specifically reading or writing to it—such as in this article).
Source and targets are defined as tables using DDL, with the integration (such as Kafka or Iceberg) specified as a connector type.
Target tables are loaded as a stream using either CREATE TABLE … AS SELECT or a standalone INSERT INTO after defining the target table first.
There are some connectors available within Flink, along with notable standalone connectors including Flink CDC.
Kafka Connect 🔗
Kafka Connect runs on a Kafka Connect worker cluster. It is a pluggable ecosystem, providing an integration runtime that handles common tasks whilst individual connectors handle the technology-specific requirements. It uses a Kafka broker to track configuration and processing status.
You define connector jobs using JSON configuration, submitted using a REST API. There are hundreds of connectors available for Kafka Connect.
Tableflow 🔗
Tableflow is a managed service as part of Confluent Cloud for streaming data from Apache Kafka topics into Apache Iceberg tables. You can use it with any topic in Confluent Cloud that has a schema.
Confluent Cloud also provides managed connectors (giving you access to a huge ecosystem of source connectors) and managed Flink SQL (for doing any processing on the data before sending it to Iceberg).
Your Data 🔗
Let’s start off the comparison by thinking about the data that we’ve got in Kafka and want to get into Iceberg.
Where is the data coming from? 🔗
This article is focussed on data in Kafka, but that data came from somewhere. Perhaps it’s applications writing directly to it, in which case it has no bearing on your technology of choice. However, if your data is coming into Kafka from other systems, you’ll find that Kafka Connect and Confluent Cloud (for Tableflow) have a richer set of connectors than Flink. Flink does have several, including Flink CDC (which is built on Debezium).
Under this consideration also think about whether you want the data in Kafka for other purposes. Flink can take data directly from a source (e.g. RDBMS) directly into Iceberg and not write it in Kafka. This might simplify your pipeline, but it also means the same source data isn’t then available for use by other integrations or applications.
How many topics do you have? 🔗
There are two variants of this.
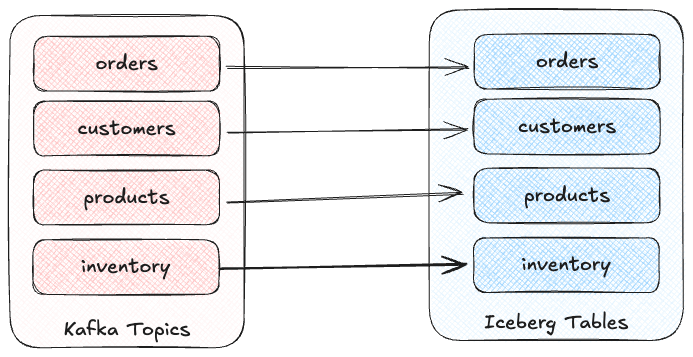
The first is where you have multiple topics for different entities.
For example, you’ve got orders, customers, products, inventory…they’re all different, and they’re all going to their own respective Iceberg table.
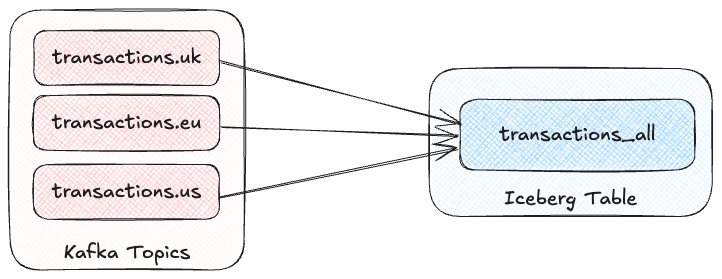
The second is where it’s multiple instances of the same entity.
This is very common in multi-tenant architectures.
Maybe each customer has their own transactions topic, and you’re wanting to populate a single consolidated Iceberg table from them.
Another example of this would be where topics are geographically isolated (perhaps across Kafka different clusters, and then replicated into a central one), from where they’re all to be written to a single Iceberg table.
So, if either of these scenarios apply to your data, how does it impact your tool choice?
In Flink SQL every unique source schema must be explicitly defined. There’s no automagic population from a schema registry. This means that if you have four different topics you need to declare eight Flink SQL tables. Bear in mind with Flink SQL it’s not only the table name but its schema too that needs specifying.
CREATE TABLE src.orders ( orderID INT, customerID INT, product STRING, quantity INT, orderTS TIMESTAMP(3) )
WITH ('connector'='kafka', 'topic'='orders', […]);
CREATE TABLE src.customers ( customerID INT, firstName STRING, lastName STRING, email STRING, createdTS TIMESTAMP(3) )
WITH ('connector'='kafka', 'topic'='customers', […]);
CREATE TABLE src.products ( productID INT, sku STRING, name STRING, unitPrice DECIMAL(10,2), updatedTS TIMESTAMP(3) )
WITH ('connector'='kafka', 'topic'='products', […]);
CREATE TABLE src.inventory ( productID INT, locationID STRING, onHand INT, reserved INT, invTS TIMESTAMP(3) )
WITH ('connector'='kafka', 'topic'='inventory', […]);Now if you want to write these to Iceberg tables, you need to declare an Iceberg table for each:
CREATE dest.orders WITH ('connector'='iceberg', […]) AS SELECT * FROM src.orders;
CREATE dest.customers WITH ('connector'='iceberg', […]) AS SELECT * FROM src.customers;
CREATE dest.products WITH ('connector'='iceberg', […]) AS SELECT * FROM src.products;
CREATE dest.inventory WITH ('connector'='iceberg', […]) AS SELECT * FROM src.inventory;However, if you’ve got multiple topics with the same schema then things are a bit easier since the Kafka connector in Flink SQL does support wildcards (topic-pattern) or a list of topics (topic with semi-colon separated topics).
You can also add topic as a metadata column to your source table so that it is exposed for writing to Iceberg—important if you want to retain the lineage information of your data.
Here’s an example of fan-in (N:1) in Flink SQL.
First, create the source table reading from multiple topics:
CREATE TABLE src.kafka_transactions_all (
transaction_id STRING, user_id STRING, amount DECIMAL(10, 2), currency STRING, merchant STRING, transaction_time TIMESTAMP(3),
src_topic STRING METADATA FROM 'topic' (1)
) WITH (
'connector' = 'kafka', 'properties.bootstrap.servers' = 'broker:9092', 'format' = 'json', 'scan.startup.mode' = 'earliest-offset',
'topic-pattern' = 'transactions\..*' (2)
);| 1 | Topic metadata column included in the table definition |
| 2 | Wildcard pattern for source Kafka topics |
Now let’s write that to a single Iceberg table:
CREATE TABLE my_iceberg_catalog.my_glue_db.transactions_all AS
SELECT * FROM src.kafka_transactions_all;You can also do fan-in (N:1) in Flink SQL using the UNION ALL operator.
For example, if the above Kafka topics were defined as individual Flink SQL tables (perhaps with slightly different schemas that need unifying), you could do something like this to write them all to a single Iceberg table:
CREATE TABLE my_iceberg_catalog.my_glue_db.transactions_all AS
SELECT 'uk' as src_topic, transaction_id, user_id, amount, currency, merchant, transaction_time FROM src.kafka_transactions_uk
UNION ALL
SELECT 'eu' as src_topic, transaction_id, user_id, amount, currency, merchant, transaction_time FROM src.kafka_transactions_eu
[…]Further more to Flink SQL’s flexibility is the statement sets feature, which you can use for fan-out (1:N)—routing data from the same source table to different target tables.
Moving onto Kafka Connect, it supports wildcards and can do fan-in (N:1) using the topics.regex parameter:
"topics.regex": "src.*",It can also do fan-out (1:N) using the iceberg.tables.route-field parameter for the Iceberg sink connector, described here.
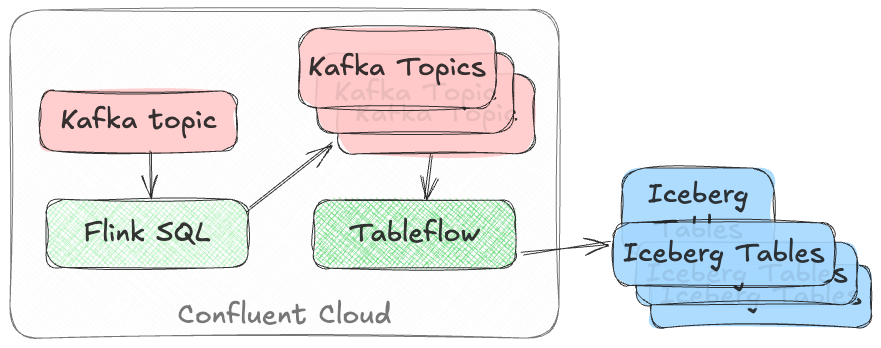
Tableflow has a 1:1 relationship between Kafka topics and Iceberg tables. It can be enabled for multiple topics easily either through the UI, or from the CLI:
# Write topics `my_topic[1-5]` to an Iceberg table
$ confluent tableflow topic create my_topic1
$ confluent tableflow topic create my_topic2
$ confluent tableflow topic create my_topic3
$ confluent tableflow topic create my_topic4
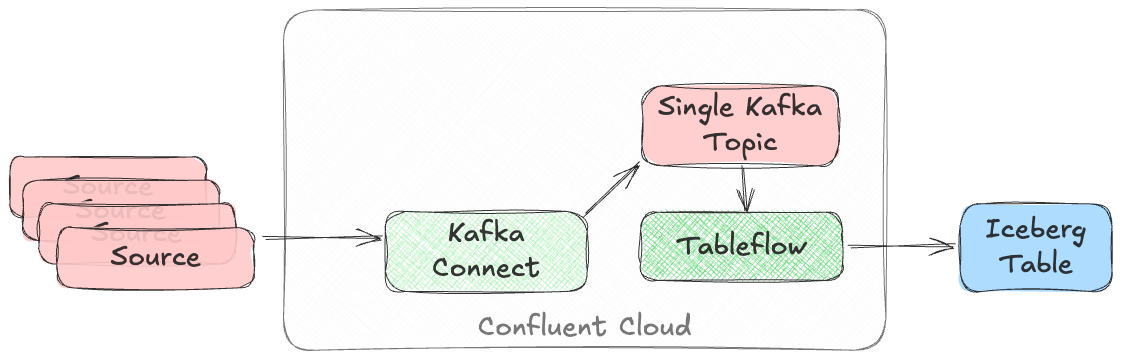
$ confluent tableflow topic create my_topic5You can achieve fan-in either by using Kafka Connect on Confluent Cloud to ingest to a single topic from multiple sources
or using Confluent Cloud for Apache Flink to UNION multiple topics into one.
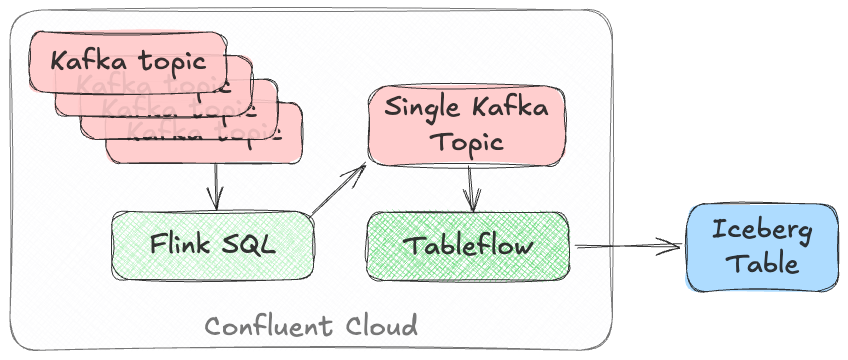
Similarly, fan-out can be done using Flink to route the source topics into multiple destination ones, each of which is then enabled for Tableflow.
Whither Schema? 🔗
Sure, your data has a schema. But does it have a schema?
If your data is just a lump of JSON like this:
{
"click_ts": "2023-02-01T14:30:25Z",
"ad_cost": "1.50",
"is_conversion": "true",
"user_id": "001234567890"
}What should the target Iceberg table look like?
One option is that you manually created it first. Doing this you can at least make sure that the data types are set correctly.
If you’re using Flink SQL to write to Iceberg you have to declare the datatypes as part of the source Flink table DDL. For every. single. table. But at least they’ll be correct (so long as you didn’t make a mistake in typing out all that DDL!).
Kafka Connect will give you the option to play fast-and-loose with your schema if you want, and YOLO it by guessing. It might work, but you might also get this:
+----------------+----------+
| Name | Type |
+----------------+----------+
| click_ts | string | (3)
| ad_cost | string | (2)
| user_id | string |
| is_conversion | string | (1)
+----------------+----------+| 1 | Storing a boolean as a string? not ideal. |
| 2 | Storing a currency as a string? not good. |
| 3 | Storing a timestamp as a string? gross. |
A better way all round to do this if you’re using Kafka Connect or Tableflow is to have your topics' schemas in the Schema Registry. This way the target Iceberg table can be defined correctly based on the actual schema of the data—not a guess at it:
+----------------+-----------------+
| Name | Type |
+----------------+-----------------+
| click_ts | timestamp |
| ad_cost | decimal(38,2) |
| user_id | string |
| is_conversion | boolean |
+----------------+-----------------+Schema Evolution 🔗
Nothing is stable, even what is close to us in time
Another consideration to bear in mind is what happens when your schema changes. And at some point, your schema will change. So how do you make sure that the target Iceberg reflects those changes?
In Flink SQL there is no way to do this without duplicating records.
You’d need to make sure that you’re using scan.startup.mode=group-offsets and have set properties.group.id in your original DDL, then cancel the job, amend the table DDL to reflect the new schema, and then restart the job (with an INSERT INTO if you were using a CREATE TABLE…AS SELECT originally).
Even then, you’re going to duplicate the records that were written before Flink checkpointed and saved the Kafka topic offset that it had got to.
The Kafka Connect Iceberg sink supports schema evolution, just make sure you’ve set iceberg.tables.evolve-schema-enabled=true.
Tableflow supports schema evolution out of the box.
Do you want some processing to go with that? 🔗
Perhaps you’re just wanting a big 'ole dumb pipe through which to dump your data into Iceberg. Perhaps, however, you’ve decided that it would be useful to mask a few columns or filter some rows. Maybe, even, you’ve decided to shift left and move a bunch of your batch workload out of the datalake and closer to the point at which the data’s created (per Roche’s maxim)
This can contribute a significant amount of weighting to your tool choice.
|
An added dimension to consider is what kind of processing you’re doing (or plausibly would want to do in the future without needing to change your architecture). Stateless means literally what it says; there is no state. If you can process each record as it arrives without needing to build up state (like a counter, for example, or a lookup table), it’s stateless. Stateful, on the other hand, is where you do use state.
Common examples would be an aggregation ( |
If integration is Kafka Connect’s raison d’être, processing is Flink’s. It’s where Flink SQL really comes into its own, particularly for stateful transformations.
If you can express it in SQL, you can probably do it in Flink. Joining to other data (whether in Kafka, or other systems), time-based aggregations (orders per hour, for example), sessionising and pattern matching—all of this is Flink’s bread and butter. Flink SQL can also do stateless processing (filtering, schema projection, etc) too, and compared to Kafka Connect’s Single Message Transforms (see below) definitely easier to configure (it’s just SQL) and also richer in functionality. You’ll sometimes find with Single Message Transforms that there’s a particular transformation that you need and it just doesn’t exist yet.
Kafka Connect can do stateless processing using Single Message Transforms. These are configured through bits of JSON configuration, and whilst not the most intuitive way to express a transformation, they are remarkably powerful. For example, to drop named fields from the source table so that they aren’t included in the Iceberg table schema, you’d add this to your connector configuration:
{
"connector.class": "org.apache.iceberg.connect.IcebergSinkConnector",
[…]
"transforms" : "dropCC",
"transforms.dropCC.type" : "org.apache.kafka.connect.transforms.ReplaceField$Value",
"transforms.dropCC.exclude" : "col1, col4"
}There are lots of other transformations available, many part of Apache Kafka itself, others provided by the community. I wrote a blog series about these previously: Twelve Days of SMT
Tableflow is part of Confluent Cloud which means you already have access to Confluent Cloud for Apache Flink for your processing—the best of both worlds!
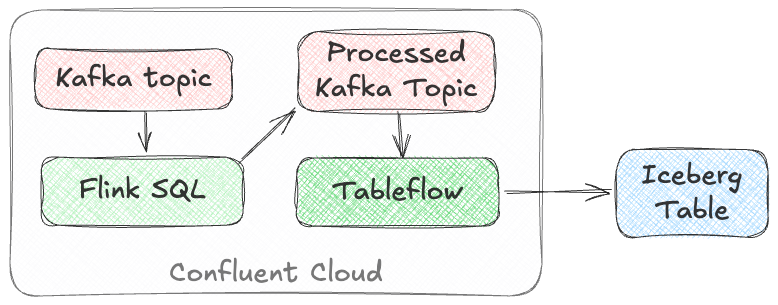
If your Kafka data is coming from Kafka Connect upstream using a managed connector in Confluent Cloud you can also use Single Message Transforms at ingest.
INSERT OVERWRITE and UPSERT 🔗
Just as schemas may change, so may the data itself.
This could be an aggregate (such as a COUNT) for which more records have been received and so needs updating, or late-arriving data or data that’s been restated and needs to replace what’s there.
For whatever reason, you’ll need to plan how you’re going to handle this in your Iceberg table.
One option is using UPSERT or INSERT OVERWRITE semantics:
-
UPSERTis a portmanteau of the operation that it describes: attempt toUPDATEa key’s value, and if the key doesn’t exist thenINSERTit instead. This is a common pattern used in data engineering when loading data. -
INSERT OVERWRITEtakes a more extreme approach, and does what it says on the tin: insert values, and overwrite what’s there currently. This would more likely be used for data housekeeping (e.g. replacing the contents of a day’s partition with a restatement of the data once late data has arrived), or dimension table repopulation (replace the entire contents of the table with the latest version of the dimension).
Flink SQL supports both UPSERT and INSERT OVERWRITE (the latter in batch mode only, understandably).
Kafka Connect does not support either of these operations.
|
The current (v1.10) version of the Apache Iceberg connector for Kafka Connect does not support This means that you may see mention of the functionality, including configuration options such as For more information and latest status, see the PR to add the functionality, the GitHub issue, and a mailing list discussion. |
Tableflow will support UPSERT soon.
Delivery Semantics 🔗
Flink SQL reading from Kafka and writing to Iceberg will have exactly-once semantics so long as you enable checkpointing:
SET 'execution.checkpointing.interval' = '30s';Kafka Connect and Tableflow both have out-of-the-box support for exactly-once semantics for writing to Iceberg.
Living with it 🔗
So far I’ve looked at the areas to think about with regards to the data that you’re sending to Iceberg. That’s only part of the puzzle though. It might be a fun science experiment to put together random technologies based on their feature-support alone, but in the real world we have to live with the design choices we make too. Let’s look at some more factors to include in our weighing up of options.
Existing Ecosystem 🔗
If you already run Apache Flink or Kafka Connect (or are already a Confluent Cloud user) then that should be your assumed default. From that default position you can then weigh in the other factors described in this article and decide if any warrant deploying new technology.
Iceberg Housekeeping 🔗
Iceberg does some things—but not all. One of the things that it doesn’t do out of the box is its own housekeeping. Particularly with streaming ingest into Iceberg, you can very quickly end up with lots of small data and metadata files, which will become a problem over time for performance. I wrote more about this here.
If you’re using Apache Flink or Kafka Connect to get your data into Iceberg, you’ll need to do the housekeeping yourself. This could be a custom job using something like Trino or Apache Spark, or a tool such as Apache Amoro or Nimtable.
Tableflow includes built-in table maintenance.
Ease of Use 🔗
There’s a reason I gave a conference talk called The Joy of JARs.

Flink SQL is SQL on the surface, but a morass of Java underneath, which matters for users and operators alike. If you’re already using Flink SQL then you’ll know what I’m talking about. If you’re not and you’re looking for a warm fuzzy SQL-embrace, forget it.
Kafka Connect is built on Java too, but generally isolates the user from it. You can use Confluent Hub to install the Iceberg connector (or build it yourself, if that’s what you like doing). Configuration isn’t pretty, but it is "just" JSON. Use kcctl to make your life easier.
Tableflow is ridiculously simple to use. Click "Enable Tableflow", and that’s it.
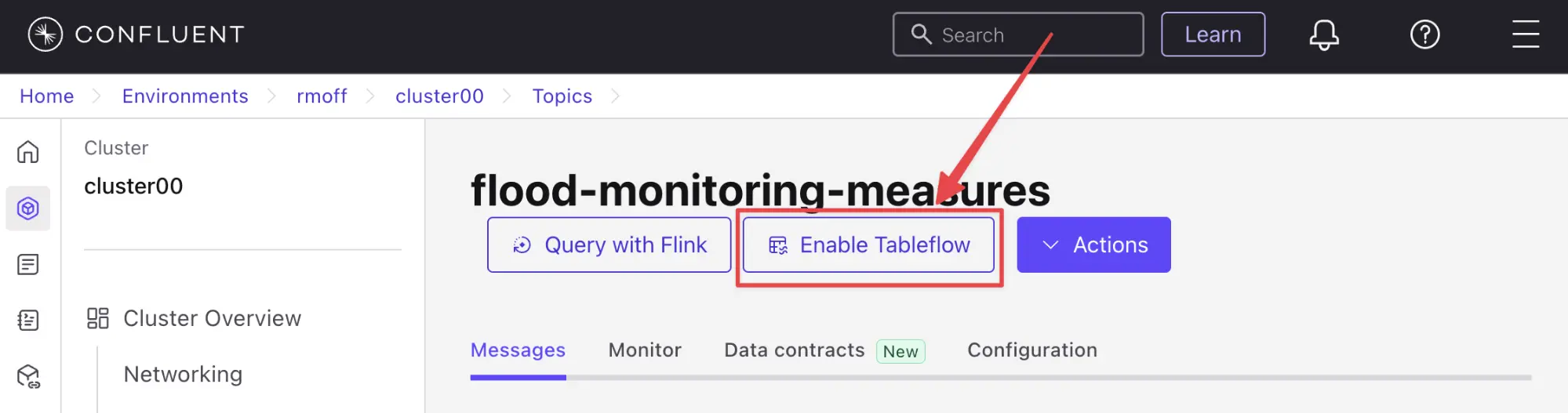
You can use the Confluent CLI instead if you’d rather:
$ confluent tableflow topic create my_topic1Self-Managed vs Fully-Managed 🔗
Tableflow is available on Confluent Cloud, which is a fully-managed option and includes Kafka brokers and Flink SQL (plus Kafka Connect if you want it for ingest).
If you want to self-manage then both Flink SQL and Kafka Connect (plus the necessary Apache Kafka) can be hosted yourself either on-premises or on a cloud provider. Plenty of people do this so you’ll not have a shortage of content online to help you set this up and keep it running.
Cost 🔗
Apache Flink, Apache Kafka (of which Kafka Connect is part), and the Apache Iceberg connector for Kafka Connect are all Apache 2.0 open source, owned by the Apache Software Foundation. You’re free to run them and modify them as you want (and you’re also then reliant on the community for any support requirements).
Tableflow is a proprietary component of Confluent Cloud and usage of it is billed.
I used to be indecisive…now I’m not so sure… 🔗
Can’t decide between Apache Iceberg and Delta Lake as your open table format of choice? Want to leave options open for the future, or other teams in your organisation?
Flink SQL has a Delta Lake connector (open source).
There is a Delta Lake connector for Kafka Connect but it is not open source and requires a paid Confluent subscription.
The kafka-delta-ingest project is part of the Delta project and open source, but does not use the Kafka Connect framework.
Tableflow has support for both Apache Iceberg and Delta Lake.
bUt wHaT aBoUt tHiS oThEr tOoL? 🔗
The aim of this blog post is not to give a comprehensive listing of all the ways of getting data into Iceberg from Kafka, but to look in more detail at the most common options that I see in use.
As well as Flink SQL, Kafka Connect, and Tableflow, other options include:
-
Apache Spark (Danica Fine covers this in her video here)
-
Flink CDC added a pipeline connector for Iceberg in the 3.5 release. There’s no source connector for Kafka, but if your data is coming from Postgres or MySQL this might be an interesting option to look into.
-
The Debezium Iceberg Consumer is a community project that integrates with Debezium Server as a sink to Iceberg. Similar to Flink CDC Pipelines, you’d not use it for reading from Kafka but if you’ve got a Debezium-supported RDBMS as source and you’re not already running Kafka, this could be worth a look.
-
Aiven recently published a whitepaper describing
Iceberg Topics for Apache Kafka. It’s very early days and it has yet to be proven in production, and has significant gaps including lack of schema evolution. It’ll be interesting to see how the project develops and the traction that it’ll get.
tl;dr 🔗
-
Flink SQL is fantastic if you want to process data before sending it to Iceberg, typically as part of an analytics pipeline. If you just need a "dumb pipe" it’s less easy to justify.
-
Kafka Connect excels as a "dumb pipe", and also has support for stateless transformations. If you want to do stateful processing you’ll want to pair it with a stream processor (hey, such as Flink SQL!).
-
Tableflow is a fully-managed tool for getting data from Kafka into Iceberg. It’s part of Confluent Cloud so you also have access to Flink SQL through Confluent Cloud for Apache Flink if you want to pre-process any of the data before sending it to Iceberg. Tableflow includes table maintenance, which you’d have to do yourself if using Flink SQL or Kafka Connect to send the data to Iceberg.
References 🔗
-
Keeping your Data Lakehouse in Order: Table Maintenance in Apache Iceberg
-
Writing to Apache Iceberg on S3 using Flink SQL with Glue catalog
-
Writing to Apache Iceberg on S3 using Kafka Connect with Glue catalog
-
🎥 Tableflow: Not Just Another Kafka-to-Iceberg Connector! (Alex Sorokoumov)
-
📑 No More Fragile Pipelines: Kafka and Iceberg the Declarative Way - Adi Polak (🎥 Video)
-
🎥 Iced Kaf-fee: Chilling Kafka Data into Iceberg Tables by Danica Fine