Ever tried to hammer a nail in with a potato?
Nor me, but that’s what I’ve felt like I’ve been attempting to do when trying to really understand agents, as well as to come up with an example agent to build.
As I wrote about previously, citing Simon Willison, an LLM agent runs tools in a loop to achieve a goal. Unlike building ETL/ELT pipelines, these were some new concepts that I was struggling to fit to an even semi-plausible real world example.
That’s because I was thinking about it all wrong.
My comfort zone 🔗
For the last cough 20 cough years I’ve built data processing pipelines, either for real or as examples based on my previous experience. It’s the same pattern, always:
-
Data comes in
-
Data gets processed
-
Data goes out
Maybe we fiddle around with the order of things (ELT vs ETL), maybe a particular example focusses more on one particular point in the pipeline—but all the concepts remain pleasingly familiar. All I need to do is figure out what goes in the boxes:
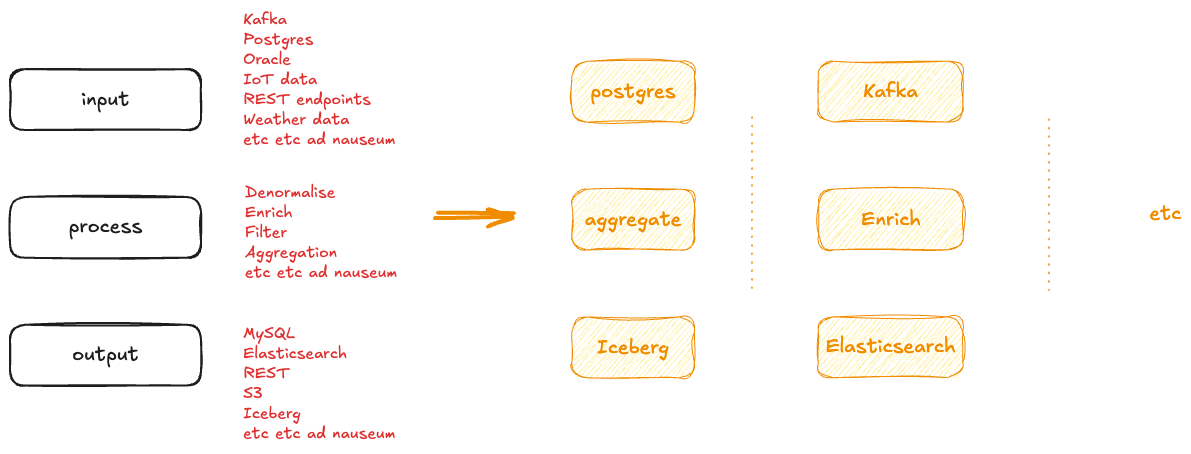
I’ve even extended this to be able to wing my way through talking about applications and microservices (kind of). We get some input, we make something else happen.

Somewhat stretching beyond my experience, admittedly, but it’s still the same principles. When this thing happens, make a computer do that thing.
Enter the Agents problem 🔗
Perhaps I’m too literal, perhaps I’m cynical after too many years of vendor hype, or perhaps it’s just how my brain is wired—but I like concrete, tangible, real examples of something.
So when it comes to agents, particularly with where we’re at in the current hype-cycle, I really wanted to have some actual examples on which to build my understanding. In addition, I wanted to build some of my own. But where to start?
Here was my mental model; literally what I sketched out on a piece of paper as I tried to think about what real-world example could go in each box to make something plausible:
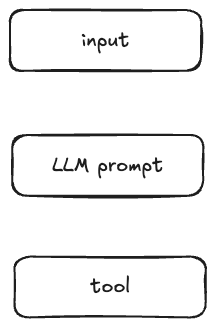
But this is where I got stuck, and spun my proverbial wheels on for several days. Every example I could think of ended up with me uttering, exasperated…but why would you do it like that.
My first mistake was focussing on the LLM bit as needing to do something with the input data.
I had a whole bunch of interesting data sources (like river levels, for example) but my head blocked on "but that’s numbers, what can you get an LLM to do with those?!". The LLM bit of an agent, I mistakenly thought, demanded unstructured input data for it to make any sense. After all, if it’s structured, why aren’t we just processing it with a regular process—no need for magic fairy dust here.
This may have been an over-fitting of an assumption based on my previous work with an LLM to summarise human-input data in a conference keynote.
What a tool 🔗
The tool bit baffled me just as much. With hindsight, the exact problem turned out to be the solution. Let me explain…
Whilst there are other options, in many cases an agent calling a tool is going to do so using MCP. Thus, grabbing the dog firmly by the tail and proceeding to wag it, I went looking for MCP servers.
Looking down a list of hosted MCP servers that I found, I found about a half-dozen that were open, including GlobalPing, AlphaVantage, and CoinGecko.
Flummoxed, I cast around for an actual use of one of these, with an unstructured data source. Oh jeez…are we really going to do the 'read a stream of tweets and look up the stock price/crypto-token' thing again?
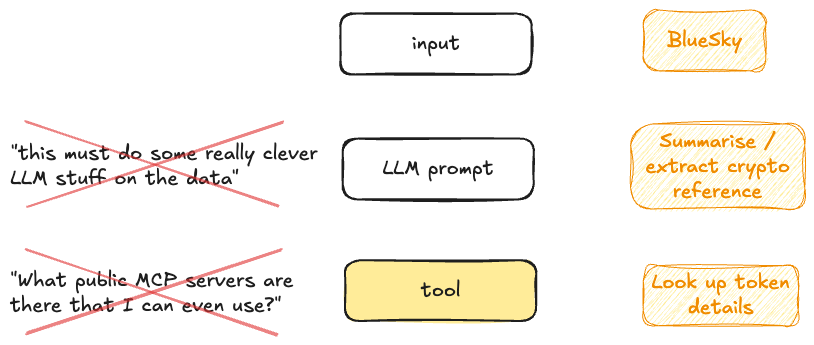
Shifting focus 🔗
The mistake I made was this: I’d focussed on the LLM bit of the agent definition:
an LLM agent runs tools in a loop to achieve a goal
Actually, what an agent is about is this:
[…] runs tools
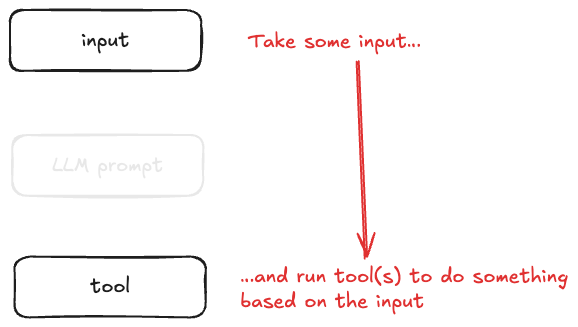
The LLM bit can do fancy LLM stuff—but it’s primarily there to invoke the tool(s) and decide when they’ve done what they need to do.
A tool is quite often just a wrapper on an API. So what we’re saying is, with MCP, we have a common interface to APIs. That’s…all.
We can define agents to interact with systems, and the way they interact is through a common protocol: MCP. When we load a web page, we don’t concern ourselves with what Chrome is doing, and unless we stop and think about it we don’t think about the TCP and HTTP protocols being used. It’s just the common way of things talking to each other.
And that’s the idea with MCP, and thus tool calling from agents. (Yes, there are ways you can call tools from agents, but MCP is the big one, at the moment).
Now it makes sense 🔗
Given this reframing, it makes sense why there are so few open MCP servers. If an MCP server is there to offer access to an API, who leaves their API open for anyone to use?
Well, read-only data provided like CoinGecko and AlphaVantage, perhaps. But in general, the really useful thing we can do with tools is change the state of systems. That’s why any SaaS platform worth its salt is rushing to provide an MCP server. Not to jump on the AI bandwagon per-se, but because if this is going to be the common protocol by which things get to be automated with agents, you don’t want to be there offering betamax when everyone else has VHS. SaaS platforms will still provide their APIs for direct integration, but they will also provide MCP servers. There’s also no reason why applications developed within an organisation wouldn’t offer MCP either, in theory.
Isn’t this just a hack? 🔗
No, not really. It actually makes a bunch of sense to me. I also like it a lot, from a not-really-a-real-coder point of view.
Let me explain.
If you want to respond to something that’s happened by interacting with another external system, you have two choices now:
-
Write custom code to call the API. Handle failures, retries, monitoring, etc.
If you want to interact with a different system, you now need to understand its API, work out calling it, write new code to do so.
-
Write an agent that responds to the thing that happened, and have it call the tool. The agent framework now standardises handling failures, retries, and all the rest of it.
If you want to call a different system, the agent stays pretty much the same. The only thing that you change is the MCP server and tool that you call.
You could write custom code—and there are good examples of where you’ll continue to. But you no longer have to.
For Kafka folk, my analogy here would be data integration with Kafka Connect. Kafka Connect provides the framework that handles all of the sticky and messy things about data integration (scale, error handling, types, connectivity, restarts, monitoring, schemas, etc etc etc). You just use the appropriate connector with it and configure it. Different system? Just swap out the connector. You want to re-invent the wheel and re-solve and solved-problem? Go ahead; maybe you’re special. Or maybe NIH is real ;P
The light dawns 🔗
So…what does an actual agent look like now, given this different way of looking at it? How about this:

Sure, the LLM could do a bunch of clever stuff with the input. But it can also just take our natural language expression of what we want to happen, and make it so.
Extending this to Streaming Agents 🔗
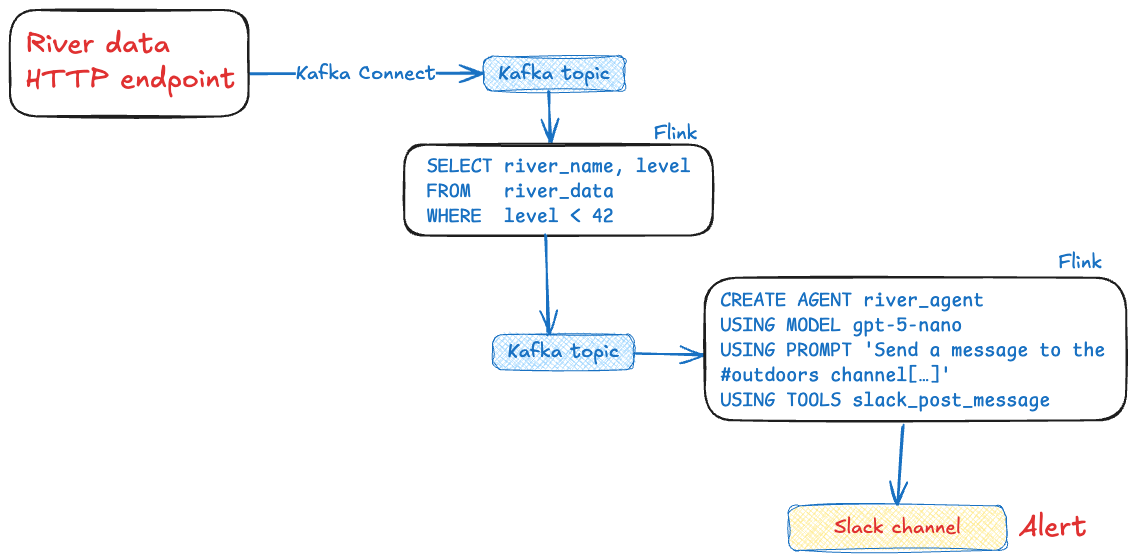
Confluent launched Streaming Agents earlier this year. They’re part of the fully-managed Confluent Cloud platform and provide a way to run agents like I’ve described above, driven by events in a Kafka topic.
Here’s what the above agent would look like as a Streaming Agent:
Is this over-engineered? Do you even need an agent? Why not just do this?
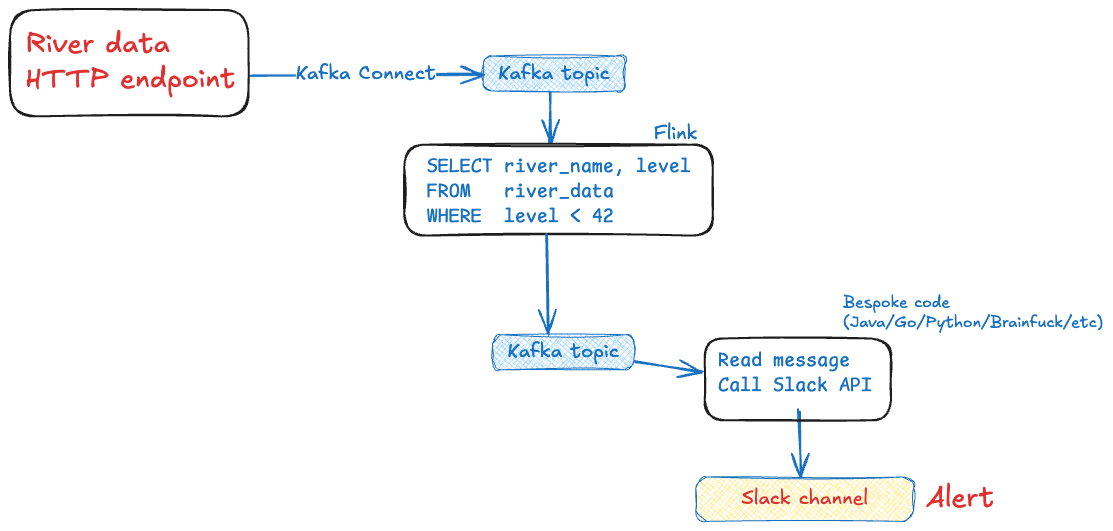
or this?
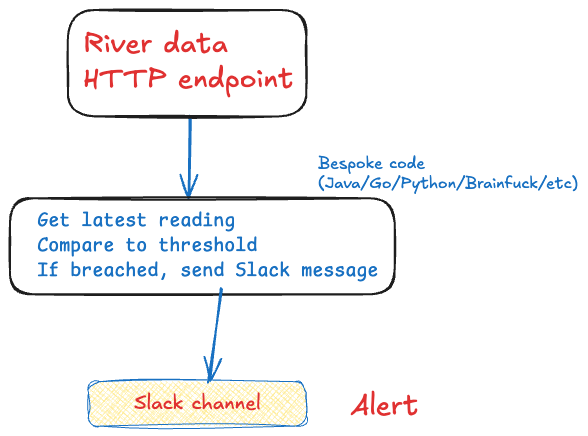
You can. Maybe you should. But…don’t forget failure conditions. And restarts. And testing. And scaling.
All these things are taken care of for you by Flink.
<< wrap up >>
