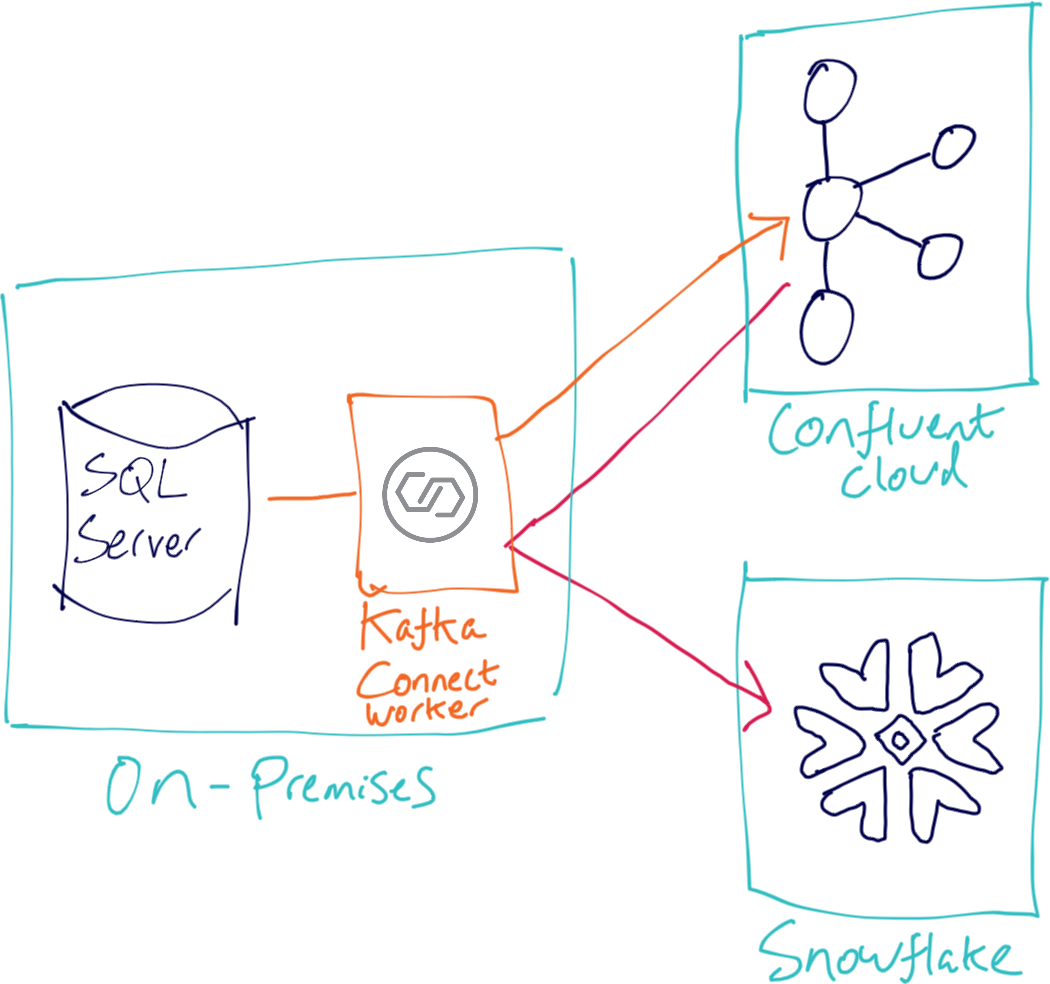
Common mistakes made when configuring multiple Kafka Connect workers
Kafka Connect can be deployed in two modes: Standalone or Distributed. You can learn more about them in my Kafka Summit London 2019 talk.
I usually recommend Distributed for several reasons:
-
It can scale
-
It is fault-tolerant
-
It can be run on a single node sandbox or a multi-node production environment
-
It is the same configuration method however you run it
I usually find that Standalone is appropriate when:
-
You need to guarantee locality of task execution, such as picking up a log file from a folder on a specific machine
-
You don’t care about scale or fault-tolerance ;-)
-
You like re-learning how to configure something when you realise that you do care about scale or fault-tolerance X-D