Blog Writing for Developers
Writing is one of the most powerful forms of communication, and it’s useful in a multitude of roles and contexts. As a blog-writing, documentation-authoring, twitter-shitposting DevEx engineer I spend …

Writing is one of the most powerful forms of communication, and it’s useful in a multitude of roles and contexts. As a blog-writing, documentation-authoring, twitter-shitposting DevEx engineer I spend …

 Markdown
Markdown
 Documentation
Documentation
 PySpark
PySpark





 dbt
dbt
 Data Engineering
Data Engineering
 DuckDB
DuckDB
 Data Engineering
Data Engineering

 Data Engineering
Data Engineering


 Data Engineering
Data Engineering
 Airtable
Airtable
 DevRel
DevRel

 DevRel
DevRel


 Hugo
Hugo
 Kafka Summit
Kafka Summit
 Productivity
Productivity

 ksqlDB
ksqlDB
 Confluent Cloud
Confluent Cloud
 ksqlDB
ksqlDB
 ActiveMQ
ActiveMQ
 Kafka Connect
Kafka Connect

 Data
Data

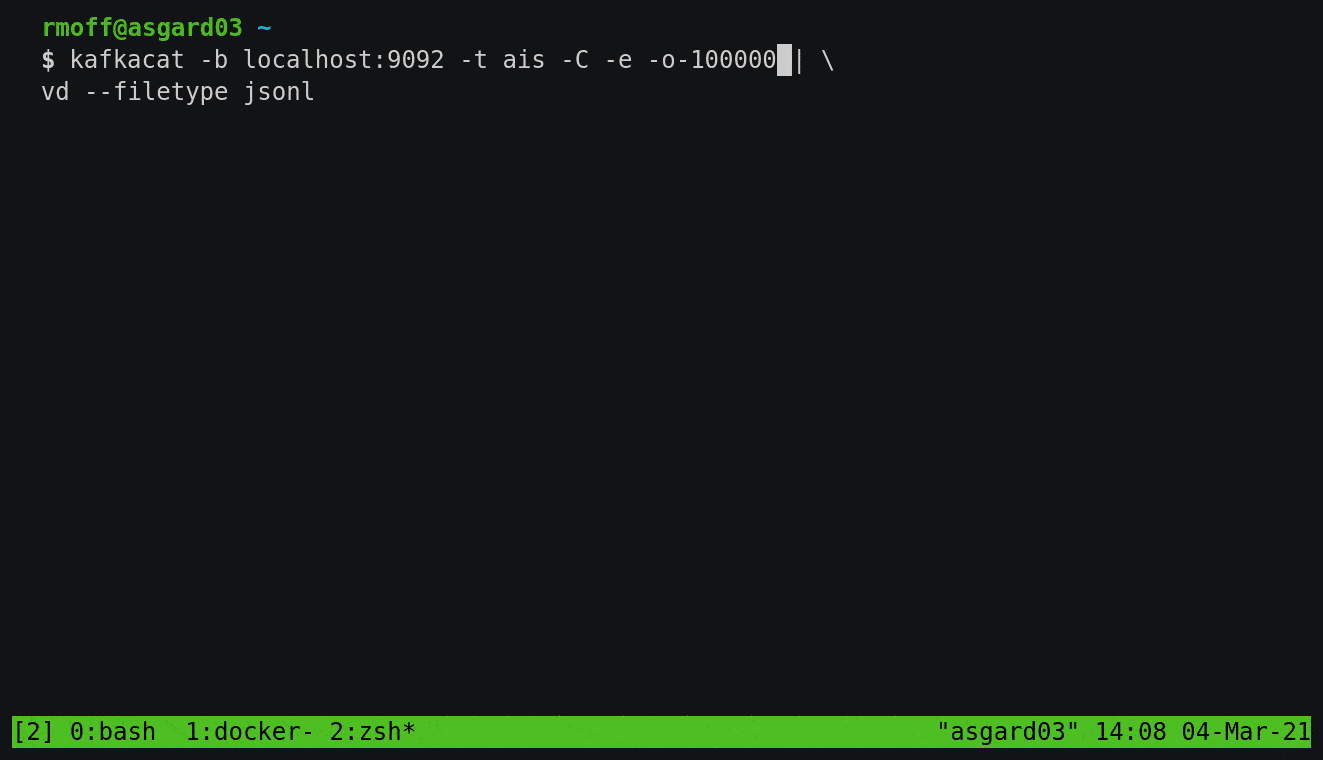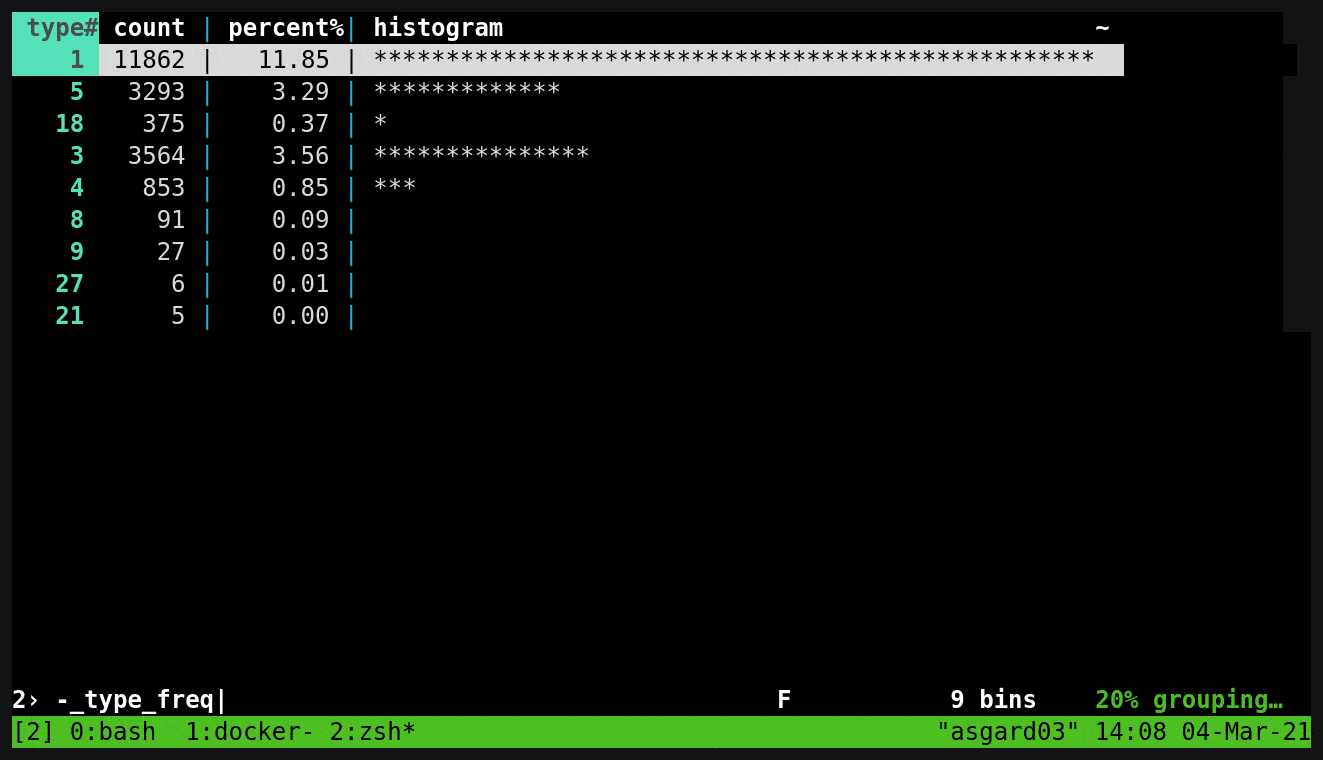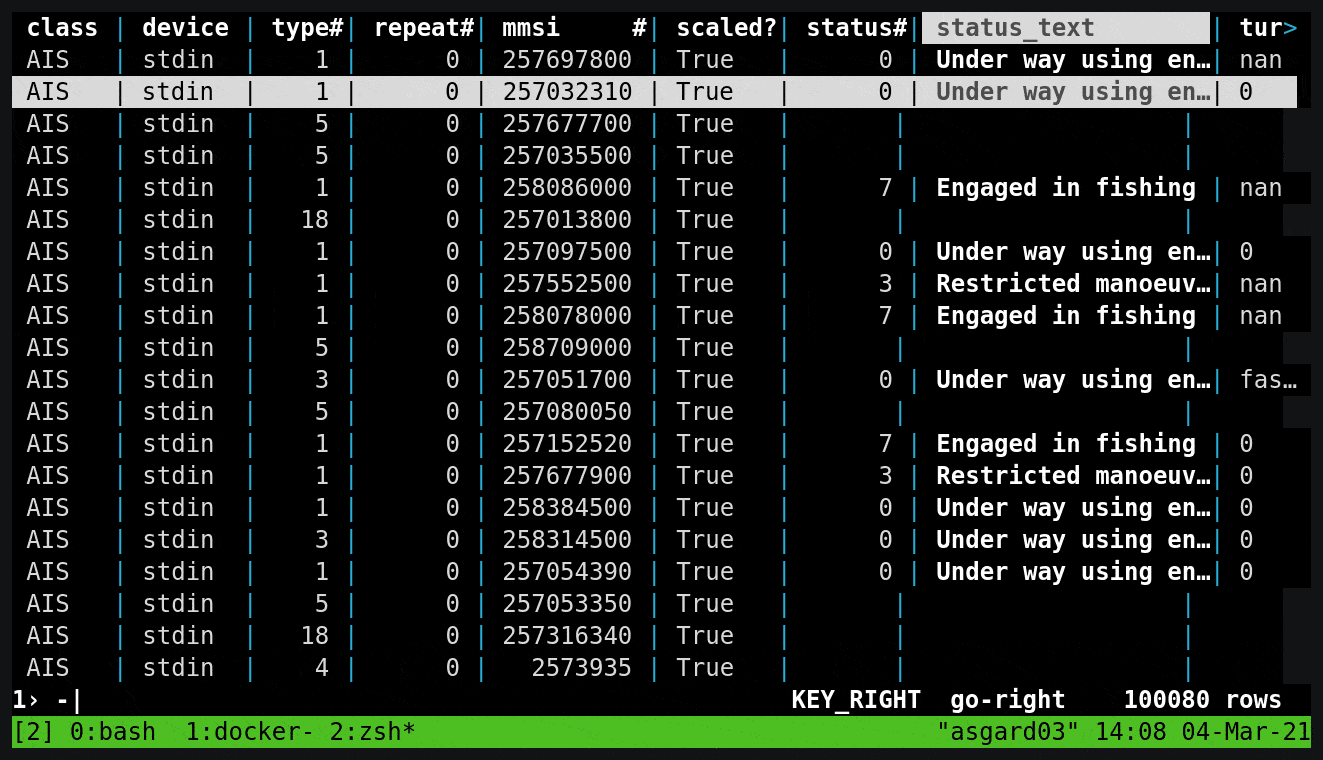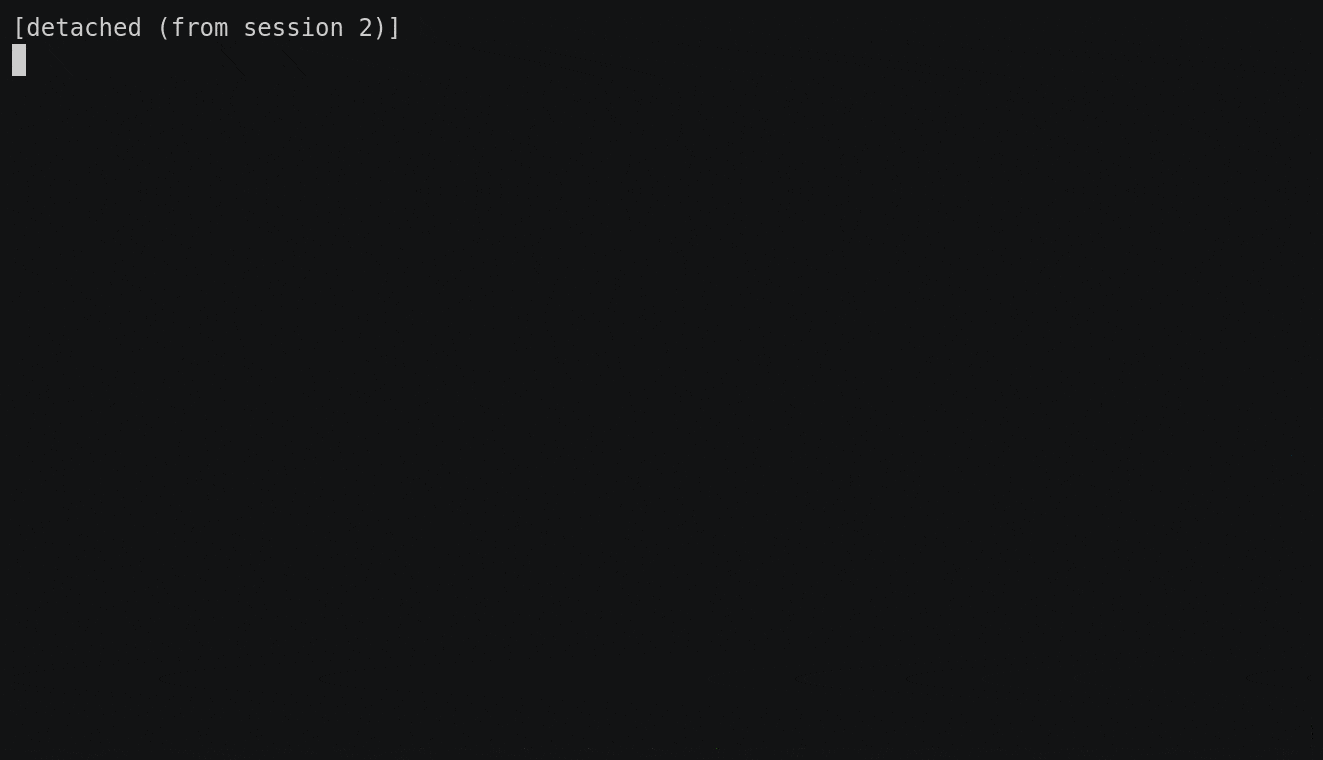
 kcat (kafkacat)
kcat (kafkacat)


 oracle
oracle
 Kafka Connect
Kafka Connect

 Kafka Connect
Kafka Connect
 Kafka Connect
Kafka Connect
 Kafka Connect
Kafka Connect

 Blogging
Blogging

 Kafka Connect
Kafka Connect