🎄 Twelve Days of SMT 🎄 - Day 7: TimestampRouter
Just like the RegExRouter, the TimeStampRouter can be used to modify the topic name of messages as they pass through Kafka Connect. Since the topic name is usually the basis for the naming of the …

Just like the RegExRouter, the TimeStampRouter can be used to modify the topic name of messages as they pass through Kafka Connect. Since the topic name is usually the basis for the naming of the …




 Kafka Connect
Kafka Connect
 Kafka Connect
Kafka Connect
 DevRel
DevRel


 Kafka
Kafka
 Kafka Connect
Kafka Connect
 ksqlDB
ksqlDB
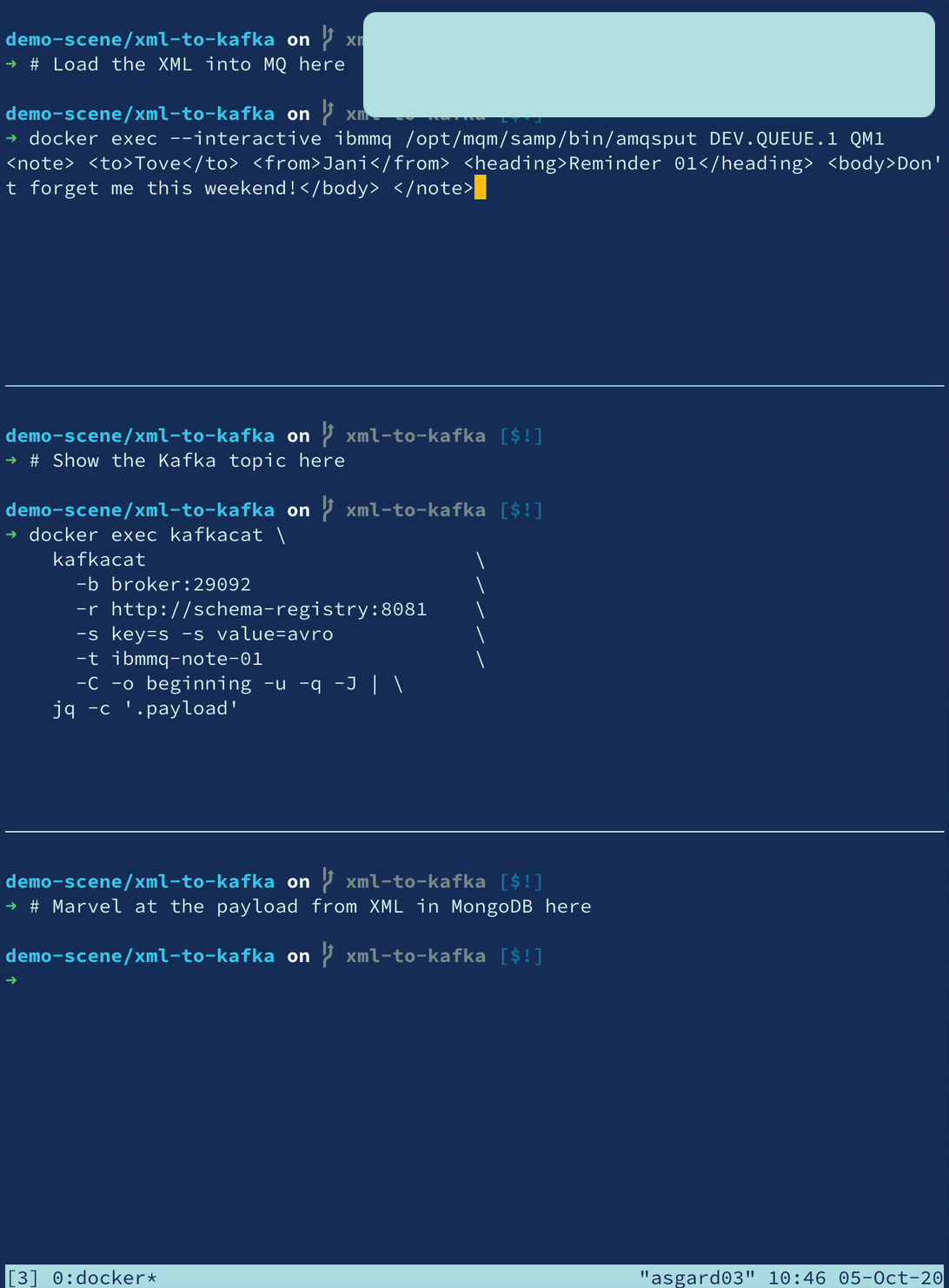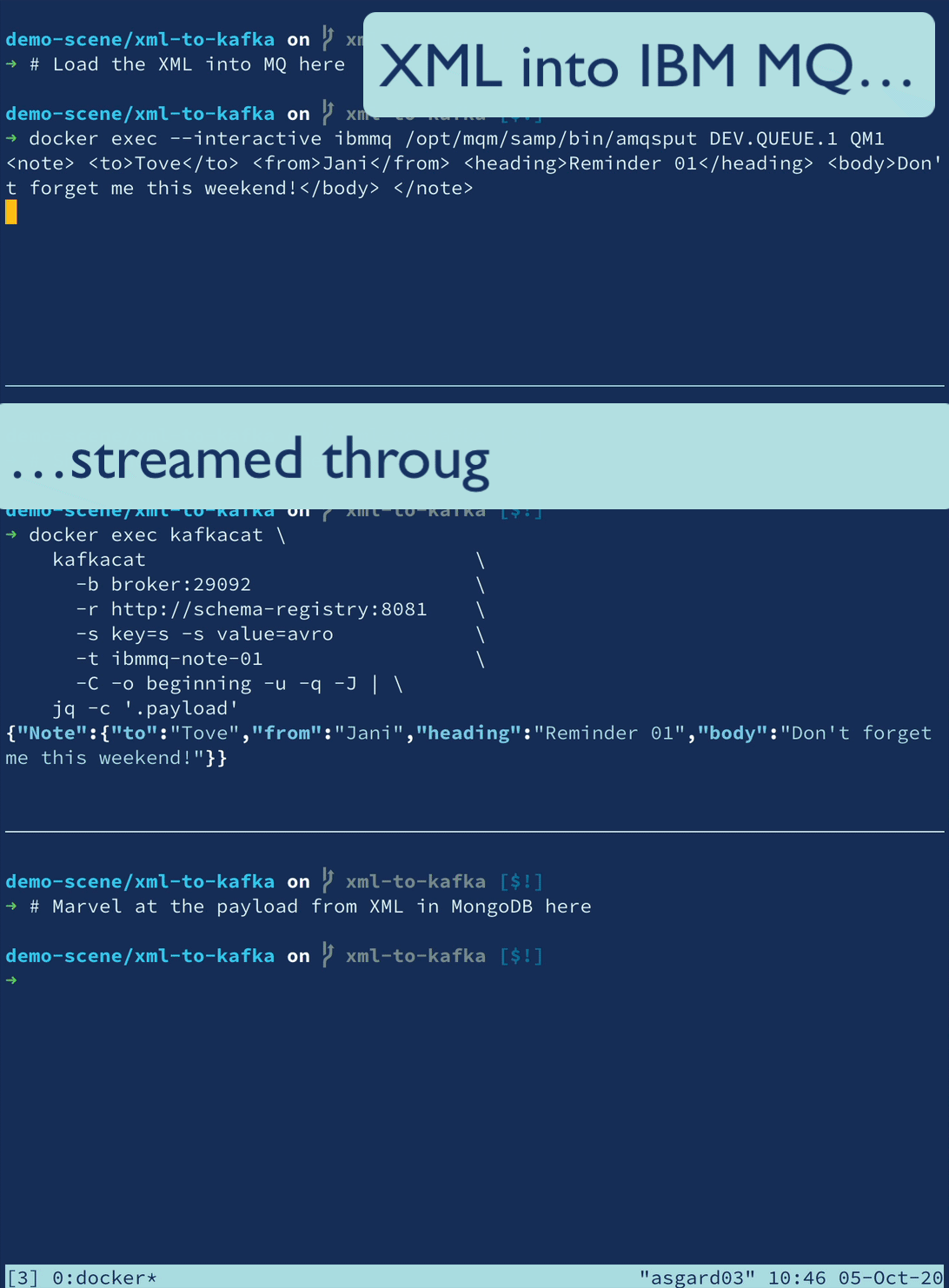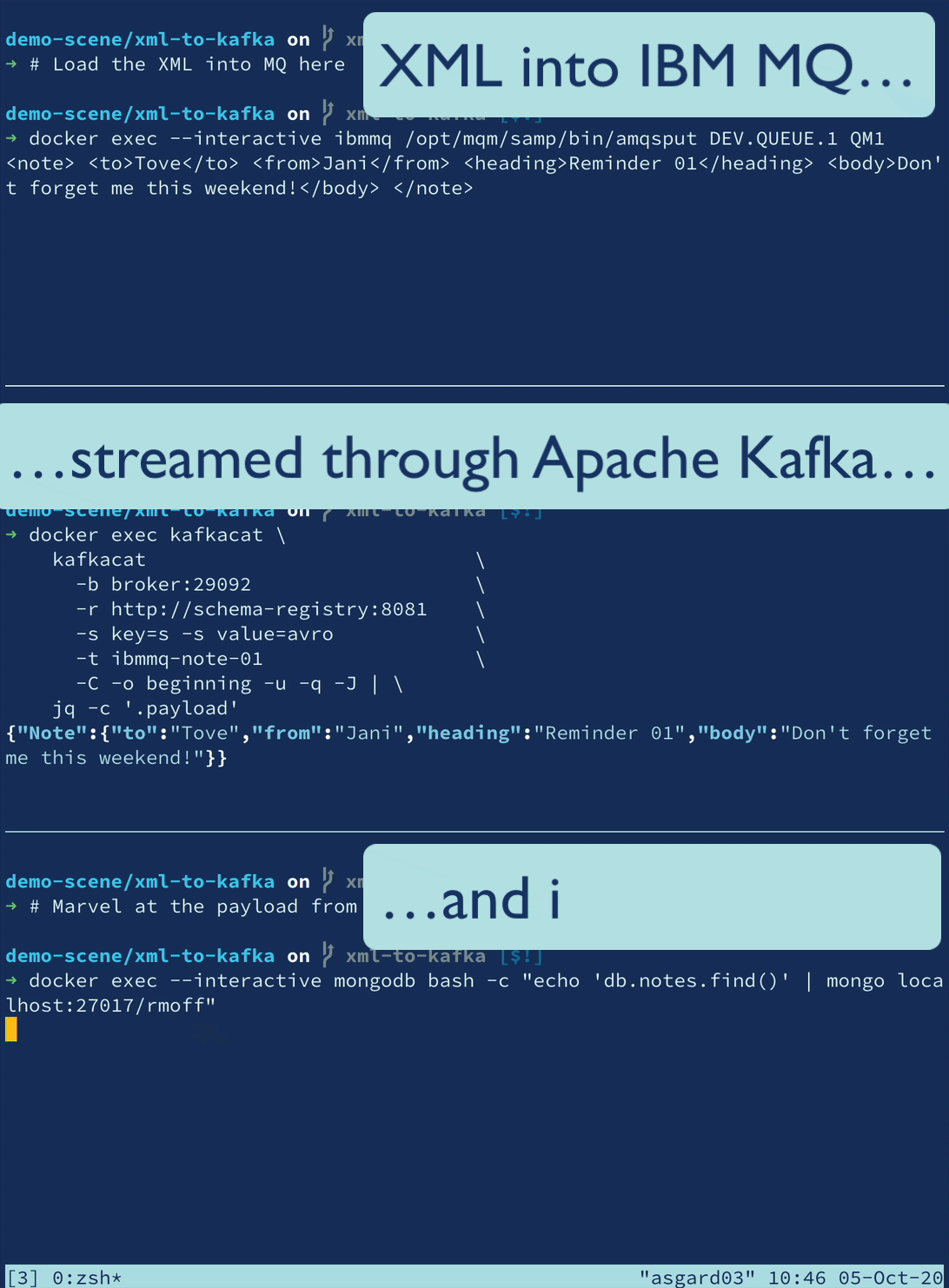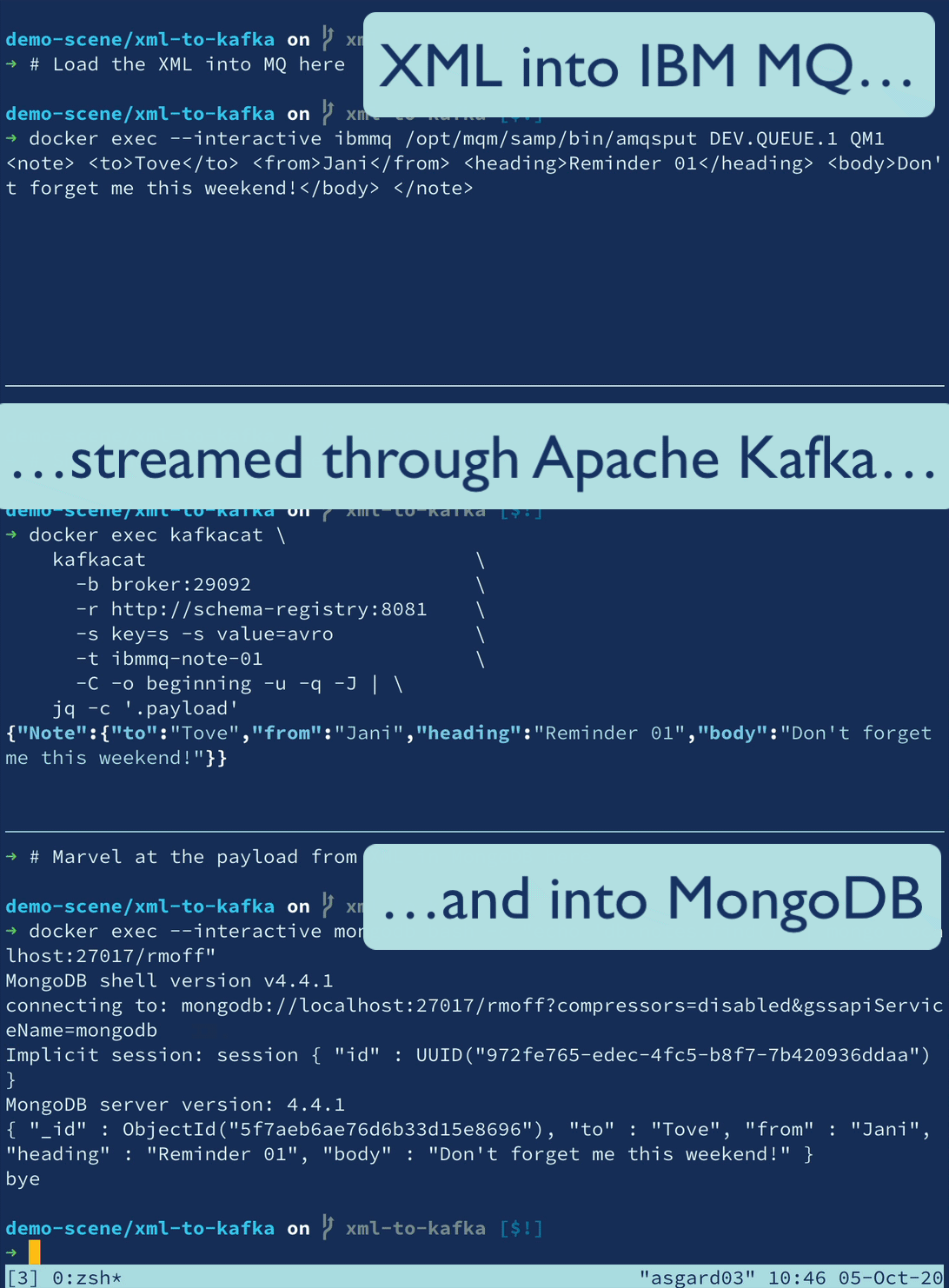 XML
XML
 XML
XML
XML
abcde
XML
XML
XML
abcde
 jq
jq

 MS SQL
MS SQL
 Hugo
Hugo


 sqlite
sqlite
 Go
Go
 Go
Go
Go
Go
Go
Go
Go
Go
Go
Go
Go
Go
Go
Go
Go
Go
 Go
Go
 kcat (kafkacat)
Go
Go
Go
Go
Go
Go
Go
Go
kcat (kafkacat)
Go
Go
Go
Go
Go
Go
Go
Go