Automatically restarting failed Kafka Connect tasks
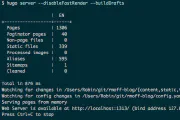
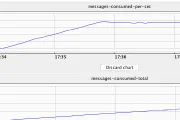
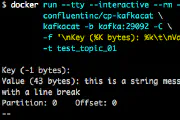
Here’s a hacky way to automatically restart Kafka Connect connectors if they fail. Restarting automatically only makes sense if it’s a transient failure; if there’s a problem with your pipeline (e.g. …