Why Do We Need Streaming ETL?
(This is an expanded version of the intro to an article I posted over on the Confluent blog. Here I get to be as verbose as I like ;)) My first job from university was building a datawarehouse for a …

(This is an expanded version of the intro to an article I posted over on the Confluent blog. Here I get to be as verbose as I like ;)) My first job from university was building a datawarehouse for a …
 apache kafka
apache kafka

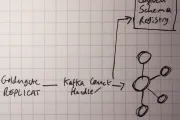

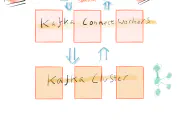
 Apache Kafka
Apache Kafka
 goldengate
goldengate
 conferences
conferences

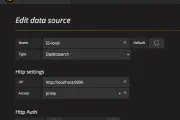 lsblk
lsblk
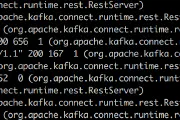 Apache Kafka
Apache Kafka
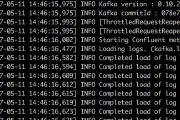 Apache Kafka
Apache Kafka
 vmdk
vmdk


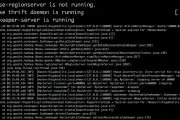
 Apache Kafka
ogg
Apache Kafka
Apache Kafka
ogg
Apache Kafka
 Apache Kafka
Apache Kafka
 ogg
Apache Kafka
ogg
Apache Kafka

 spark
spark
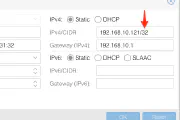 apache drill
apache drill
 mogodb
mogodb
 lxc
lxc
 edgemax
edgemax
 docker
docker
 proxmox
proxmox


 OBIEE
OBIEE
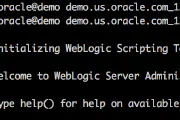 OBIEE
OBIEE

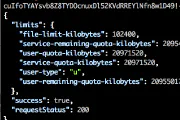 OBIEE
OBIEE