-
 04 Oct 2023 cd: string not in pwdzsh
04 Oct 2023 cd: string not in pwdzsh -
 02 Oct 2023 Learning Apache Flink S01E02: What is Flink?Apache Flink
02 Oct 2023 Learning Apache Flink S01E02: What is Flink?Apache Flink -
 29 Sep 2023 Learning Apache Flink S01E01: Where Do I Start?Apache Flink
29 Sep 2023 Learning Apache Flink S01E01: Where Do I Start?Apache Flink -
 Streaming
Streaming
-
 19 Jul 2023 Blog Writing for DevelopersDevRel
19 Jul 2023 Blog Writing for DevelopersDevRel -
 23 May 2023 What Does This DevEx Engineer Do?devrel
23 May 2023 What Does This DevEx Engineer Do?devrel -
 Markdown
Markdown
-
 Documentation
Documentation
-
 PySpark
PySpark
-
 14 Mar 2023 Quickly Convert CSV to Parquet with DuckDBDuckDB
14 Mar 2023 Quickly Convert CSV to Parquet with DuckDBDuckDB -
 03 Mar 2023 Making the move from Alfred to RaycastAlfred
03 Mar 2023 Making the move from Alfred to RaycastAlfred -
 03 Mar 2023 Aligning mismatched Parquet schemas in DuckDBDuckDB
03 Mar 2023 Aligning mismatched Parquet schemas in DuckDBDuckDB -
 09 Dec 2022 Looking Forwards, and Looking BackwardsCareer
09 Dec 2022 Looking Forwards, and Looking BackwardsCareer -
 08 Nov 2022 Data Engineering in 2022: ELT toolsELT
08 Nov 2022 Data Engineering in 2022: ELT toolsELT -
 dbt
dbt
-
 Data Engineering
Data Engineering
-
 DuckDB
DuckDB
-
 Data Engineering
Data Engineering
-
 26 Sep 2022 Current 2022 - 5k Fun RunKafka Summit
26 Sep 2022 Current 2022 - 5k Fun RunKafka Summit -
 Data Engineering
Data Engineering
-
 14 Sep 2022 Data Engineering: ResourcesData Engineering
14 Sep 2022 Data Engineering: ResourcesData Engineering -
 14 Sep 2022 Data Engineering in 2022: Storage and AccessData Engineering
14 Sep 2022 Data Engineering in 2022: Storage and AccessData Engineering -
 Data Engineering
Data Engineering
-
 Airtable
Airtable
-
 DevRel
DevRel
-
 31 Aug 2022 ⚡️ Writing an abstract for a lightning talk ⚡️DevRel
31 Aug 2022 ⚡️ Writing an abstract for a lightning talk ⚡️DevRel -
 DevRel
DevRel
-
 07 Apr 2022 Remote-First Developer AdvocacyDevRel
07 Apr 2022 Remote-First Developer AdvocacyDevRel -
 07 Apr 2022 Hanging up my Boarding Passes and Jetlag…for nowDevRel
07 Apr 2022 Hanging up my Boarding Passes and Jetlag…for nowDevRel -
 Hugo
Hugo
-
 Kafka Summit
Kafka Summit
-
 Productivity
Productivity
-
 29 Jul 2021 Why I use Alfred App (and maybe you should too)Productivity
29 Jul 2021 Why I use Alfred App (and maybe you should too)Productivity -
 ksqlDB
ksqlDB
-
 Confluent Cloud
Confluent Cloud
-
 ksqlDB
ksqlDB
-
 ActiveMQ
ActiveMQ
-
 Kafka Connect
Kafka Connect
-
 11 Mar 2021 Kafka Connect - SQLSyntaxErrorException: BLOB/TEXT column … used in key specification without a key lengthKafka Connect
11 Mar 2021 Kafka Connect - SQLSyntaxErrorException: BLOB/TEXT column … used in key specification without a key lengthKafka Connect -
 Data
Data
-
 04 Mar 2021 Using Open Sea Map data in Kibana mapsKibana
04 Mar 2021 Using Open Sea Map data in Kibana mapsKibana -
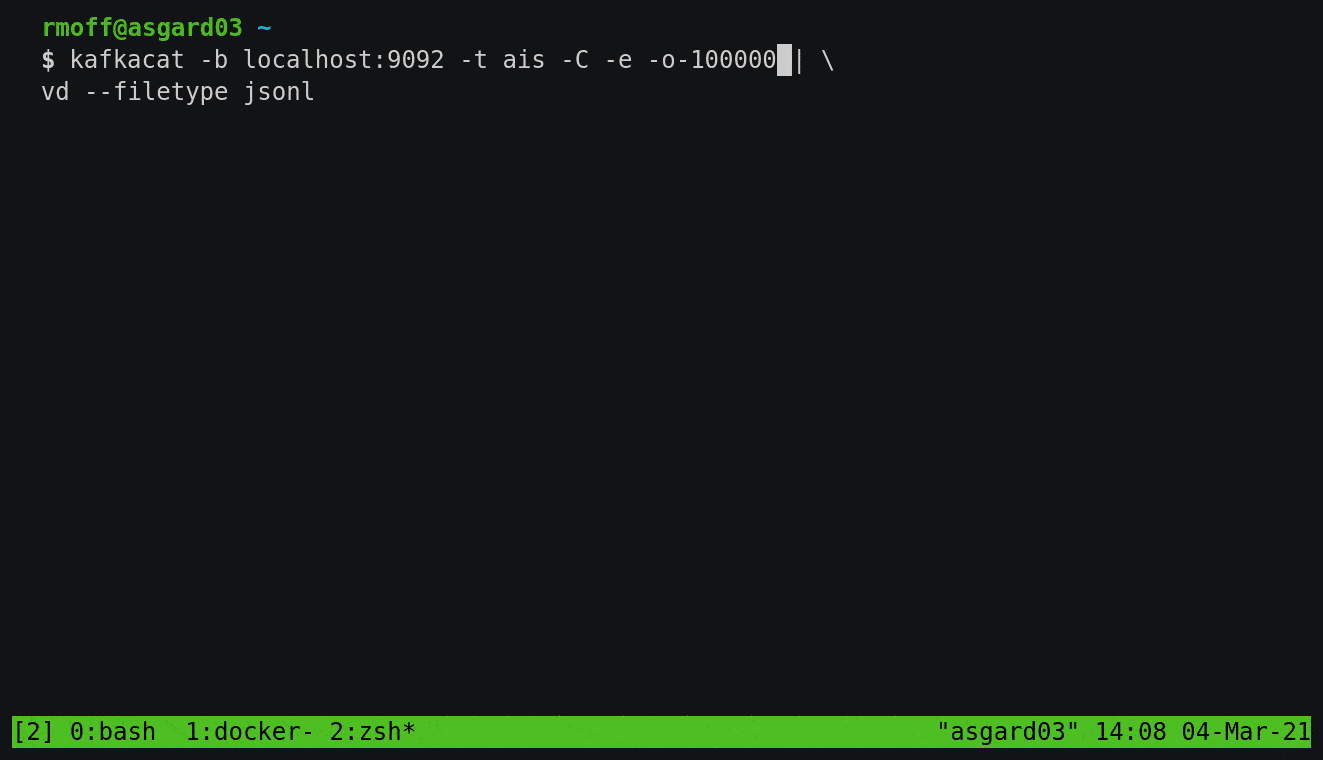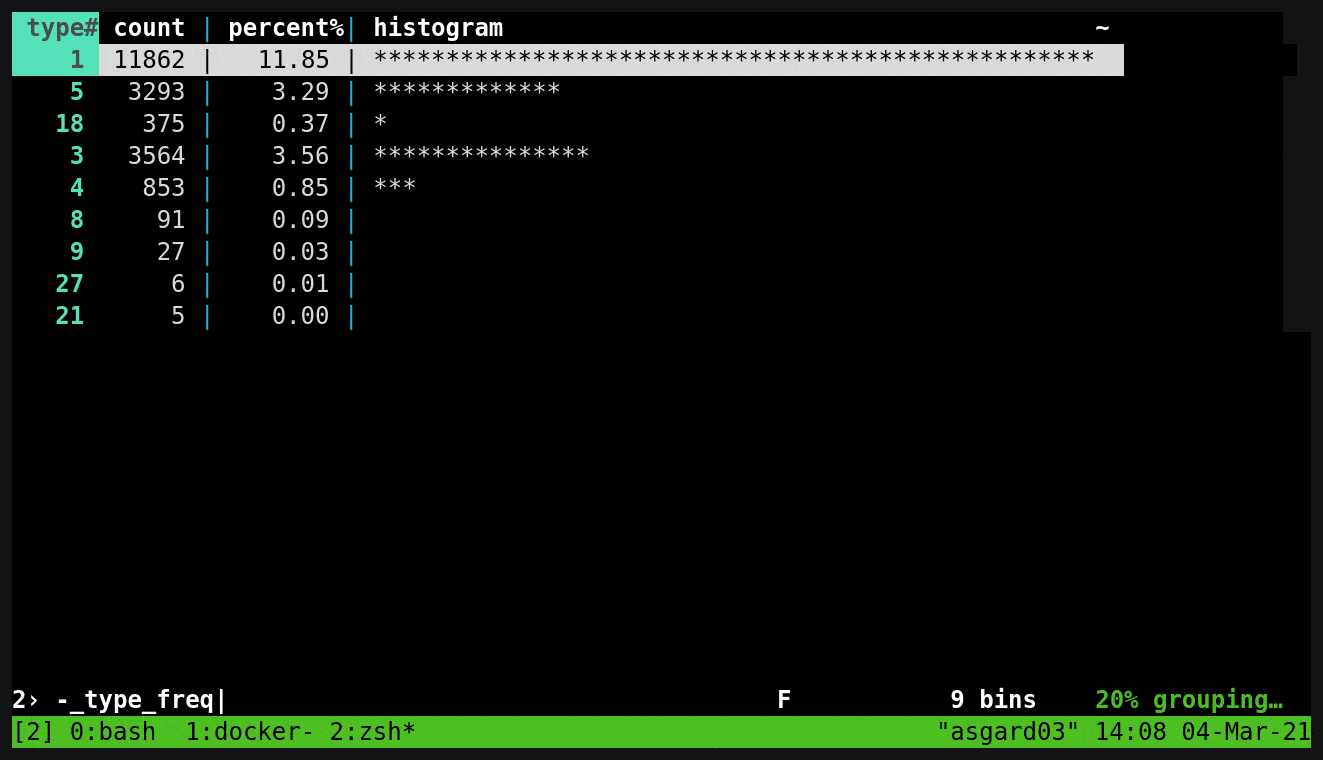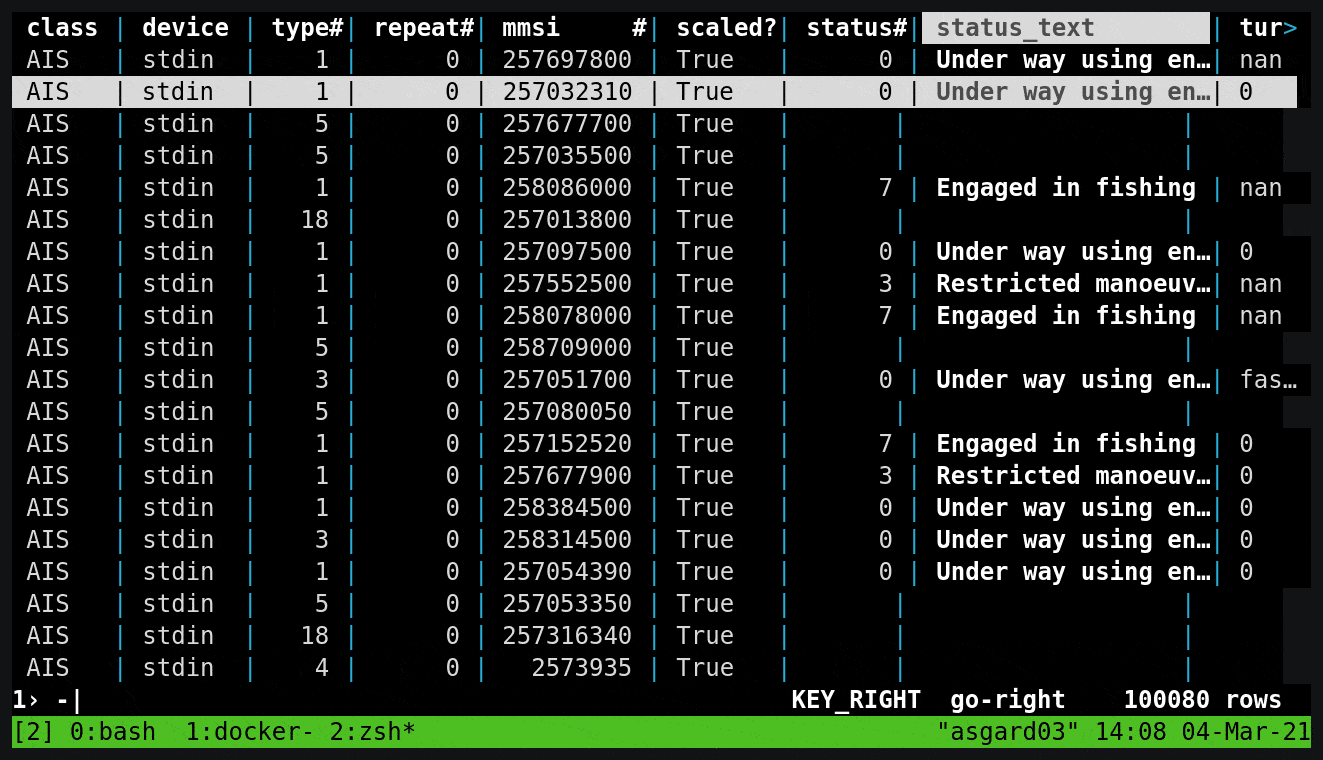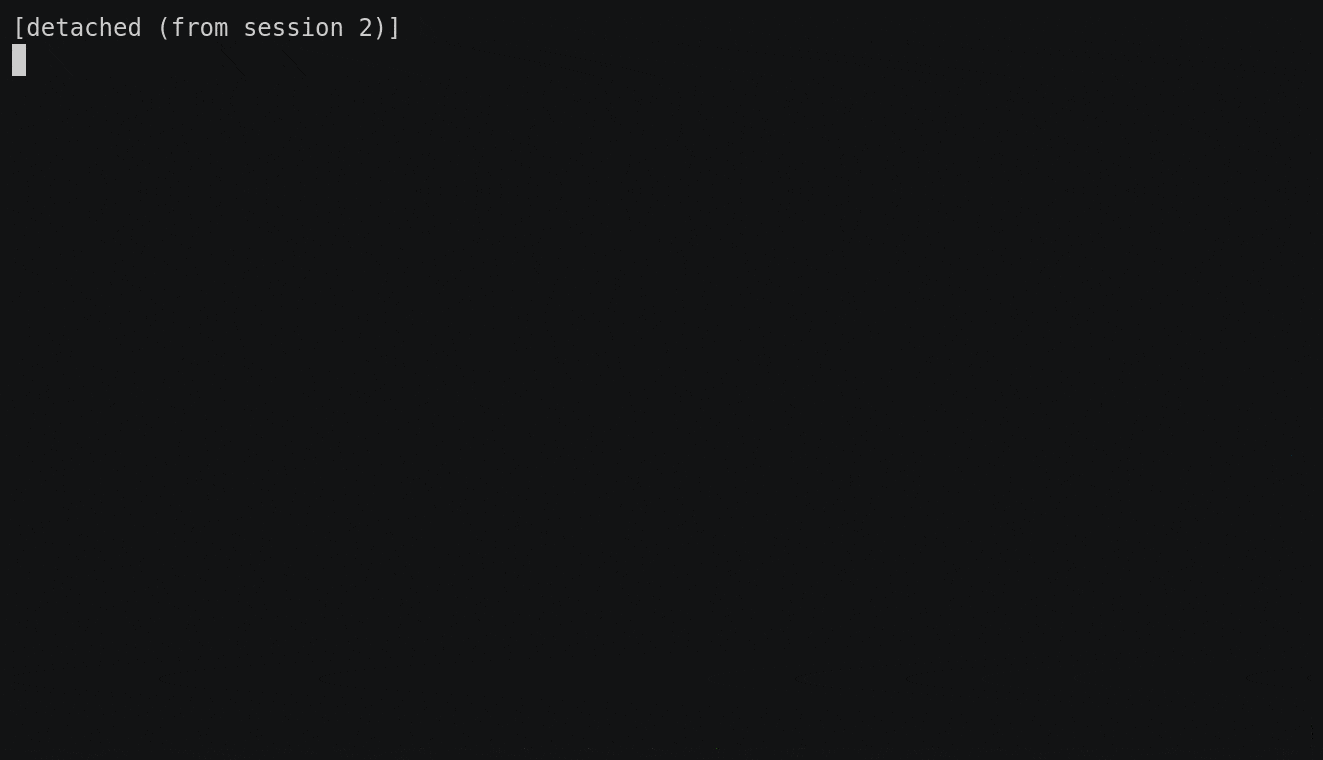
 kcat (kafkacat)
kcat (kafkacat)
-
 17 Feb 2021 📼 ksqlDB HOWTO - A mini video series 📼ksqlDB
17 Feb 2021 📼 ksqlDB HOWTO - A mini video series 📼ksqlDB -
 02 Feb 2021 Performing a GROUP BY on data in bashData Engineering
02 Feb 2021 Performing a GROUP BY on data in bashData Engineering -
 oracle
oracle
-
 Kafka Connect
Kafka Connect
-
 06 Jan 2021 Creating topics with Kafka ConnectKafka Connect
06 Jan 2021 Creating topics with Kafka ConnectKafka Connect -
 Kafka Connect
Kafka Connect
-
 Kafka Connect
Kafka Connect
-
 Kafka Connect
Kafka Connect