
I’ve been wanting to try out dbt for some time now, and a recent long-haul flight seemed like the obvious opportunity to do so. Except many of the tutorials with dbt that I found were based on using Cloud, and airplane WiFi is generally sucky or non-existant. Then I found the DuckDB-based demo of dbt, which seemed to fit the bill (🦆 geddit?!) perfectly, since DuckDB runs locally. In addition, DuckDB had appeared on my radar recently and I was keen to check it out.
The README for jaffle_shop_duckdb is comprehensive and well-written. Kudos to the author for providing copy-paste for all the steps needed to get set up including an isolated Python virtual environment.
My starting point for this was pretty much zero knowledge of dbt, and I used this opportunity to poke around it and understand it better. I could go and read the docs and the training material, but that’d be too obvious ;)
| If you’re interested in DuckDB make sure to also check out the noodling around with it that I did in a notebook recently. |
Mach Speed 🔗
The first execution option of the demo is called Mach Speed and basically has you simply run the whole thing end-to-end with dbt build — and that’s it.
$ dbt build
16:29:22 Running with dbt=1.1.1
16:29:22 Found 5 models, 20 tests, 0 snapshots, 0 analyses, 167 macros, 0 operations, 3 seed files, 0 sources, 0 exposures, 0 metrics
16:29:22
16:29:22 Concurrency: 1 threads (target='dev')
16:29:22
16:29:22 1 of 28 START seed file main.raw_customers ..................................... [RUN]
16:29:22 1 of 28 OK loaded seed file main.raw_customers ................................. [INSERT 100 in 0.14s]
16:29:22 2 of 28 START seed file main.raw_orders ........................................ [RUN]
16:29:23 2 of 28 OK loaded seed file main.raw_orders .................................... [INSERT 99 in 0.04s]
16:29:23 3 of 28 START seed file main.raw_payments ...................................... [RUN]
16:29:23 3 of 28 OK loaded seed file main.raw_payments .................................. [INSERT 113 in 0.04s]
16:29:23 4 of 28 START view model main.stg_customers .................................... [RUN]
[…]
16:29:23 28 of 28 START test unique_orders_order_id ..................................... [RUN]
16:29:23 28 of 28 PASS unique_orders_order_id ........................................... [PASS in 0.03s]
16:29:23
16:29:23 Finished running 3 seeds, 3 view models, 20 tests, 2 table models in 1.16s.
16:29:23
16:29:23 Completed successfully
16:29:23
16:29:23 Done. PASS=28 WARN=0 ERROR=0 SKIP=0 TOTAL=28
16:29:34 Error sending message, disabling trackingThat’s a lot of things it’s just done, with the resulting data loaded into DuckDB. The path of the database file is set in the profiles.yml dbt configuration file:
outputs:
dev:
type: duckdb
path: 'jaffle_shop.duckdb'If we check in DuckDB we can see there’s data been loaded and transformed in various forms - magic!
jaffle_shop.duckdb> \dt
+---------------+
| name |
+---------------+
| customers |
| orders |
| raw_customers |
| raw_orders |
| raw_payments |
| stg_customers |
| stg_orders |
| stg_payments |
+---------------+
Time: 0.020sThe source of the data is the CSV 'seed' data in /seed - the demo’s author notes that this is not an idiomatic way to work with dbt and typically the data will already be in the database.
As a side note - make sure to check out duckcli, which gives DuckDB one of the most beautiful interactive CLI tools out of the box for any database that I’ve used.
Step-by-Step 🔗
Whilst the README says very clearly :
What this repo is not: A tutorial
I’m still wanting to use it to understand a bit about dbt (and DuckDB), so I’m going to run each step at a time to understand a bit more about what dbt is and what it does. The collection of steps here is what dbt build executes automagically for you.
To start with I’ll delete the DuckDB database that was created above, and then create a new one (since it doesn’t exist when I launch the CLI it’ll get created).
$ rm jaffle_shop.duckdb
$ duckcli jaffle_shop.duckdb
Version: 0.0.1
GitHub: https://github.com/dbcli/duckcli
jaffle_shop.duckdb>Confirm that it’s empty:
jaffle_shop.duckdb> \dt
Time: 0.006sdbt seed 🔗
Let’s do the first bit of the processing (as shown in the build output above), which is going to be loading the sample data ('seed' data). I’m not 100% sure of the definition of a model at this point but I’m going to guess it’s the CSV files.
|
The docs are rather good. Instead of just guessing I could look up
|
The help text says you can use --models to specify one or more models. There are three seed files:
$ ls -l seeds
total 24
-rw-r--r-- 1 rmoff staff 1302 27 Sep 21:33 raw_customers.csv
-rw-r--r-- 1 rmoff staff 2723 27 Sep 21:33 raw_orders.csv
-rw-r--r-- 1 rmoff staff 2560 27 Sep 21:33 raw_payments.csvSo lets take one of the CSV filenames and use that:
$ dbt seed --models raw_customers
16:59:27 Running with dbt=1.1.1
16:59:28 Found 5 models, 20 tests, 0 snapshots, 0 analyses, 167 macros, 0 operations, 3 seed files, 0 sources, 0 exposures, 0 metrics
16:59:28
16:59:28 Concurrency: 1 threads (target='dev')
16:59:28
16:59:28 1 of 1 START seed file main.raw_customers ...................................... [RUN]
16:59:28 1 of 1 OK loaded seed file main.raw_customers .................................. [INSERT 100 in 0.08s]
16:59:28
16:59:28 Finished running 1 seed in 0.17s.
16:59:28
16:59:28 Completed successfully
16:59:28
16:59:28 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
16:59:28 Error sending message, disabling trackingNote the INSERT 100. I’m guessing this is what it says on the tin - that it’s inserted 100 rows. Let’s check DuckDB:
jaffle_shop.duckdb> \dt
+---------------+
| name |
+---------------+
| raw_customers |
+---------------+
Time: 0.018s
jaffle_shop.duckdb> select count(*) from raw_customers;
+--------------+
| count_star() |
+--------------+
| 100 |
+--------------+
1 row in set
Time: 0.007s
jaffle_shop.duckdb>The table’s been created by dbt, but I’m not sure using what schema definition. Here’s how it looks in DuckDB:
+-----+------------+---------+---------+------------+-------+
| cid | name | type | notnull | dflt_value | pk |
+-----+------------+---------+---------+------------+-------+
| 0 | id | INTEGER | False | <null> | False |
| 1 | first_name | VARCHAR | False | <null> | False |
| 2 | last_name | VARCHAR | False | <null> | False |
+-----+------------+---------+---------+------------+-------+Perhaps it just takes a best guess from the CSV file - the fields all being nullable would make sense, and the field names match the CSV header
$ head -n1 seeds/raw_customers.csv
id,first_name,last_nameI wonder if dbt will overwrite the data that’s there if you re-run the seed step. Let’s muck about with the data and see what happens.
jaffle_shop.duckdb> update raw_customers set last_name='Astley';
+-------+
| Count |
+-------+
| 100 |
+-------+
1 row in set
Time: 0.012s
jaffle_shop.duckdb> select last_name,count(*) from raw_customers group by last_name;
+-----------+--------------+
| last_name | count_star() |
+-----------+--------------+
| Astley | 100 |
+-----------+--------------+
1 row in set
Time: 0.011sRe-run the seed step:
$ dbt seed --models raw_customers
17:06:50 Running with dbt=1.1.1
17:06:50 Found 5 models, 20 tests, 0 snapshots, 0 analyses, 167 macros, 0 operations, 3 seed files, 0 sources, 0 exposures, 0 metrics
17:06:50
17:06:50 Concurrency: 1 threads (target='dev')
17:06:50
17:06:50 1 of 1 START seed file main.raw_customers ...................................... [RUN]
17:06:51 1 of 1 OK loaded seed file main.raw_customers .................................. [INSERT 100 in 0.16s]
17:06:51
17:06:51 Finished running 1 seed in 0.32s.
17:06:51
17:06:51 Completed successfully
17:06:51
17:06:51 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
17:06:51 Error sending message, disabling trackingCheck the data:
jaffle_shop.duckdb> select last_name,count(*) from raw_customers group by last_name;
+-----------+--------------+
| last_name | count_star() |
+-----------+--------------+
| Astley | 100 |
+-----------+--------------+
1 row in set
Time: 0.011s
jaffle_shop.duckdb>So it looks like it’s not changed. BUT…if we re-launch the DuckDB CLI you’ll see something different:
jaffle_shop.duckdb>
Goodbye!
$ duckcli jaffle_shop.duckdb
Version: 0.0.1
GitHub: https://github.com/dbcli/duckcli
jaffle_shop.duckdb> select last_name,count(*) from raw_customers group by last_name;
+-----------+--------------+
| last_name | count_star() |
+-----------+--------------+
| P. | 7 |
| M. | 8 |
| C. | 7 |
| R. | 13 |
| F. | 5 |
| W. | 11 |
| S. | 3 |
| D. | 3 |
| H. | 11 |
| K. | 4 |
| A. | 6 |
| G. | 4 |
| B. | 5 |
| O. | 4 |
| T. | 2 |
| J. | 3 |
| N. | 2 |
| L. | 1 |
| E. | 1 |
+-----------+--------------+
19 rows in set
Time: 0.023s
jaffle_shop.duckdb>So, the CLI queries the state of the DuckDB file as it was on launch, perhaps? But for sure, we can say that the dbt seed operation will reset the seed data and fix any changes that have been made.
Let’s run the rest of the seed steps (including the one we’ve been changing):
$ dbt seed
17:11:30 Running with dbt=1.1.1
17:11:30 Found 5 models, 20 tests, 0 snapshots, 0 analyses, 167 macros, 0 operations, 3 seed files, 0 sources, 0 exposures, 0 metrics
17:11:30
17:11:31 Concurrency: 1 threads (target='dev')
17:11:31
17:11:31 1 of 3 START seed file main.raw_customers ...................................... [RUN]
17:11:31 1 of 3 OK loaded seed file main.raw_customers .................................. [INSERT 100 in 0.16s]
17:11:31 2 of 3 START seed file main.raw_orders ......................................... [RUN]
17:11:31 2 of 3 OK loaded seed file main.raw_orders ..................................... [INSERT 99 in 0.08s]
17:11:31 3 of 3 START seed file main.raw_payments ....................................... [RUN]
17:11:31 3 of 3 OK loaded seed file main.raw_payments ................................... [INSERT 113 in 0.06s]
17:11:31
17:11:31 Finished running 3 seeds in 0.44s.
17:11:31
17:11:31 Completed successfully
17:11:31
17:11:31 Done. PASS=3 WARN=0 ERROR=0 SKIP=0 TOTAL=3
17:11:31 Error sending message, disabling trackingRe-launch the DuckDB CLI and observe that the three seed tables now exist and have data in them:
$ duckcli jaffle_shop.duckdb
Version: 0.0.1
GitHub: https://github.com/dbcli/duckcli
jaffle_shop.duckdb> \dt
+---------------+
| name |
+---------------+
| raw_customers |
| raw_orders |
| raw_payments |
+---------------+
Time: 0.021s
jaffle_shop.duckdb> select * from raw_payments limit 1;
+----+----------+----------------+--------+
| id | order_id | payment_method | amount |
+----+----------+----------------+--------+
| 1 | 1 | credit_card | 1000 |
+----+----------+----------------+--------+
1 row in set
Time: 0.007s
jaffle_shop.duckdb> select * from raw_customers limit 1;
+----+------------+-----------+
| id | first_name | last_name |
+----+------------+-----------+
| 1 | Michael | P. |
+----+------------+-----------+
1 row in set
Time: 0.007s
jaffle_shop.duckdb> select * from raw_orders limit 1;
+----+---------+------------+----------+
| id | user_id | order_date | status |
+----+---------+------------+----------+
| 1 | 1 | 2018-01-01 | returned |
+----+---------+------------+----------+
1 row in set
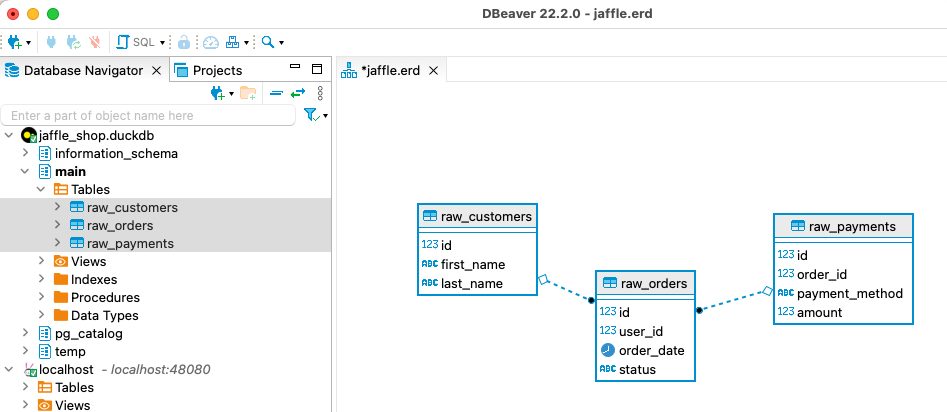
Time: 0.067sUsing DBeaver you can open the DuckDB database and visualise the tables with their FK relationships (I added these; they’re not defined by default)
The next bit we’ll poke at, based on the build docs is dbt run.
But before we quite get to that, the docs for dbt run say in turn:
dbt runexecutes compiled sql model files against the currenttargetdatabase
Which makes me think it would be interesting to first check out dbt compile.
dbt compile 🔗
dbt compilegenerates executable SQL from sourcemodel,test, andanalysisfiles. You can find these compiled SQL files in thetarget/directory of your dbt project.
I noted that target/ is in the .gitignore so I figure can be deleted (from being created in the dbt build above) and then observed to see the output in each step.
$ rm -rf targetWhilst there are three source file types described above (model, test, and analysis) I only see /models present (the paths, as before, are defined in dbt_project.yml):
$ ls -l models tests analysis
ls: analysis: No such file or directory
ls: tests: No such file or directory
models:
total 40
-rw-r--r-- 1 rmoff staff 1195 27 Sep 21:33 customers.sql
-rw-r--r-- 1 rmoff staff 1068 27 Sep 21:33 docs.md
-rw-r--r-- 1 rmoff staff 970 27 Sep 21:33 orders.sql
-rw-r--r-- 1 rmoff staff 272 27 Sep 21:33 overview.md
-rw-r--r-- 1 rmoff staff 2311 27 Sep 21:33 schema.yml
drwxr-xr-x 6 rmoff staff 192 27 Sep 21:33 stagingLet’s compile one of the models. If I take a look at the top of customers.sql it’s clearly referencing something else:
$ head models/customers.sql
with customers as (
select * from {{ ref('stg_customers') }}
),
[…]So where’s stg_customers defined? In models/staging/stg_customers.sql:
with source as (
{#-
Normally we would select from the table here, but we are using seeds to load
our data in this project
#}
select * from {{ ref('raw_customers') }}
),
renamed as (
select
id as customer_id,
first_name,
last_name
from source
)
select * from renamedSo this pulls from the raw_customers that was loaded in the seed step and changes a column name (id to customer_id). Let’s dbt compile it and see what happens.
$ dbt compile --model models/staging/stg_customers.sql
16:14:53 Running with dbt=1.1.1
16:14:53 Partial parse save file not found. Starting full parse.
16:14:54 Found 5 models, 20 tests, 0 snapshots, 0 analyses, 167 macros, 0 operations, 3 seed files, 0 sources, 0 exposures, 0 metrics
16:14:54
16:14:54 Concurrency: 1 threads (target='dev')
16:14:54
16:14:54 Done.If we head over to target/ (which we removed before the compile, so whatever we see was created by this step) we see a bunch of new content:
$ ls -lR target
total 984
drwxr-xr-x 3 rmoff staff 96 11 Oct 17:14 compiled
-rw-r--r-- 1 rmoff staff 23490 11 Oct 17:14 graph.gpickle
-rw-r--r-- 1 rmoff staff 239522 11 Oct 17:14 manifest.json
-rw-r--r-- 1 rmoff staff 232476 11 Oct 17:14 partial_parse.msgpack
-rw-r--r-- 1 rmoff staff 2077 11 Oct 17:14 run_results.json
target/compiled:
total 0
drwxr-xr-x 3 rmoff staff 96 11 Oct 17:14 jaffle_shop
target/compiled/jaffle_shop:
total 0
drwxr-xr-x 3 rmoff staff 96 11 Oct 17:14 models
target/compiled/jaffle_shop/models:
total 0
drwxr-xr-x 4 rmoff staff 128 11 Oct 17:14 staging
target/compiled/jaffle_shop/models/staging:
total 8
drwxr-xr-x 4 rmoff staff 128 11 Oct 17:14 schema.yml
-rw-r--r-- 1 rmoff staff 202 11 Oct 17:14 stg_customers.sql
target/compiled/jaffle_shop/models/staging/schema.yml:
total 16
-rw-r--r-- 1 rmoff staff 96 11 Oct 17:14 not_null_stg_customers_customer_id.sql
-rw-r--r-- 1 rmoff staff 187 11 Oct 17:14 unique_stg_customers_customer_id.sqlIf we look at the compiled version of the compiled/jaffle_shop/models/staging/stg_customers.sql model that we saw above you’ll see the reference is now resolved, with the rest of the file remaining the same:
with source as (
select * from "main"."main"."raw_customers"
),
renamed as (
select
id as customer_id,
first_name,
last_name
from source
)
select * from renamedAnother SQL file that you’ll notice has appeared is under target/compiled/jaffle_shop/models/staging/schema.yml (yes it’s a folder, even if its got a .yml extension, welcome to UNIX):
$ ls -lR target/compiled/jaffle_shop/models/staging/schema.yml
total 16
-rw-r--r-- 1 rmoff staff 96 11 Oct 17:14 not_null_stg_customers_customer_id.sql
-rw-r--r-- 1 rmoff staff 187 11 Oct 17:14 unique_stg_customers_customer_id.sqlThese two SQL files look like they’re to check two different constraints (NOT NULL and uniqueness):
$ head target/compiled/jaffle_shop/models/staging/schema.yml/*
==> target/compiled/jaffle_shop/models/staging/schema.yml/not_null_stg_customers_customer_id.sql <==
select customer_id
from "main"."main"."stg_customers"
where customer_id is null
==> target/compiled/jaffle_shop/models/staging/schema.yml/unique_stg_customers_customer_id.sql <==
select
customer_id as unique_field,
count(*) as n_records
from "main"."main"."stg_customers"
where customer_id is not nullBut where are these constraints defined? It’s not in the staging/stg_customers.sql because we saw that above and there was no DDL there. Instead the clue is in the name of the folder - staging/schema.yml. If we head back to the models folder and look at staging/schema.yml we’ll see the constraints defined in YAML:
$ cat models/staging/schema.yml
version: 2
models:
- name: stg_customers
columns:
- name: customer_id
tests:
- unique
- not_null
[…]So this is starting to come together (it would still be easier to learn if I just read the docs instead of reverse engineering this stuff…but that’s how I learn by poking things and see what yelps 🤷♂️): the schema.yml defines the names of the objects in a schema folder (my assumption is that staging is seen as a schema, and the parent folder under models another schema), and then the .sql files in that folder define the objects themselves and their derivations from their source. The source is referenced and resolved and compilation time.
The only other files under target/ at this point look like runtime info, metadata, and other such stuff. For example, here’s run_results.json:
$ jq '.' target/run_results.json
{
"metadata": {
"dbt_schema_version": "https://schemas.getdbt.com/dbt/run-results/v4.json",
"dbt_version": "1.1.1",
"generated_at": "2022-10-11T16:14:54.519780Z",
"invocation_id": "3363ffe7-90aa-4fc1-9a4b-306b180414b8",
"env": {}
},
"results": [
{
"status": "success",
"timing": [
{
"name": "compile",
"started_at": "2022-10-11T16:14:54.419911Z",
"completed_at": "2022-10-11T16:14:54.423616Z"
},
[…]dbt run 🔗
Having poked around what goes on during compilation, let’s look at dbt run. Before I do that I’ll just double-check the state of the database first:
$ duckdb jaffle_shop.duckdb -c show
┌───────────────┬────────────────────────────────────────┬──────────────────────────────────────┬───────────┐
│ table_name │ column_names │ column_types │ temporary │
├───────────────┼────────────────────────────────────────┼──────────────────────────────────────┼───────────┤
│ raw_customers │ [first_name, id, last_name] │ [VARCHAR, INTEGER, VARCHAR] │ false │
│ raw_orders │ [id, order_date, status, user_id] │ [INTEGER, DATE, VARCHAR, INTEGER] │ false │
│ raw_payments │ [amount, id, order_id, payment_method] │ [INTEGER, INTEGER, INTEGER, VARCHAR] │ false │
└───────────────┴────────────────────────────────────────┴──────────────────────────────────────┴───────────┘Only the seed tables are there, as we’d expect (from the dbt seed step; the dbt compile doesn’t execute any data movement). Now we run - I’m going to run it just for one of the models (customers) to start with:
dbt run --models raw_customersThe response to doing something daft (running the raw_customers model, instead of customers) is pleasingly forgiving ([WARNING]: Nothing to do) and informative (Try checking your model configs and model specification args):
$ dbt run --models raw_customers
09:39:14 Running with dbt=1.1.1
09:39:14 Found 5 models, 20 tests, 0 snapshots, 0 analyses, 167 macros, 0 operations, 3 seed files, 0 sources, 0 exposures, 0 metrics
09:39:14
09:39:14 [WARNING]: Nothing to do. Try checking your model configs and model specification argsLet’s try the correct one:
$ dbt run --models customers
09:40:59 Running with dbt=1.1.1
09:41:00 Found 5 models, 20 tests, 0 snapshots, 0 analyses, 167 macros, 0 operations, 3 seed files, 0 sources, 0 exposures, 0 metrics
09:41:00
09:41:00 Concurrency: 1 threads (target='dev')
09:41:00
09:41:00 1 of 1 START table model main.customers ........................................ [RUN]
09:41:00 1 of 1 ERROR creating table model main.customers ............................... [ERROR in 0.05s]
09:41:00
09:41:00 Finished running 1 table model in 0.18s.
09:41:00
09:41:00 Completed with 1 error and 0 warnings:
09:41:00
09:41:00 Runtime Error in model customers (models/customers.sql)
09:41:00 Catalog Error: Table with name stg_customers does not exist!
09:41:00 Did you mean "raw_customers"?
09:41:00
09:41:00 Done. PASS=0 WARN=0 ERROR=1 SKIP=0 TOTAL=1Agh, still not quite there. There’s probably a reason the docs exist.
Table with name stg_customers does not exist tells us that stg_customers is needed first, so let’s cross our fingers for third-time-lucky:
$ dbt run --models stg_customers
09:49:04 Running with dbt=1.1.1
09:49:04 Found 5 models, 20 tests, 0 snapshots, 0 analyses, 167 macros, 0 operations, 3 seed files, 0 sources, 0 exposures, 0 metrics
09:49:04
09:49:04 Concurrency: 1 threads (target='dev')
09:49:04
09:49:04 1 of 1 START view model main.stg_customers ..................................... [RUN]
09:49:04 1 of 1 OK created view model main.stg_customers ................................ [OK in 0.07s]
09:49:04
09:49:04 Finished running 1 view model in 0.18s.
09:49:04
09:49:04 Completed successfully
09:49:04
09:49:04 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1🎉🎉
It’s almost like flailing around without reading the docs can be productive 🤔
If we look at what’s changed in the local folder we can see a few interesting things:
$ find . -mtime -5m -print
.
./target/graph.gpickle
./target/compiled/jaffle_shop/models/staging/stg_customers.sql
./target/run_results.json
./target/manifest.json
./target/run/jaffle_shop/models
./target/run/jaffle_shop/models/staging
./target/run/jaffle_shop/models/staging/stg_customers.sql
./jaffle_shop.duckdb.wal
./jaffle_shop.duckdb
./logs/dbt.logThere’s the same ./target/compiled/jaffle_shop/models/staging/stg_customers.sql which we saw above when we ran dbt compile — although its timestamp shows that it was updated when we just ran dbt run. Alongside this ./target/compiled file there a ./target/run of the same name
$ cat ./target/run/jaffle_shop/models/staging/stg_customers.sql
create view "main"."stg_customers__dbt_tmp" as (
with source as (
select * from "main"."main"."raw_customers"
),
renamed as (
select
id as customer_id,
first_name,
last_name
from source
)
select * from renamed
);You’ll notice here that we’ve actually got some DML: create view … as. Other than that, the run version of the SQL is the same as the compile version. If we head over to DuckDB we can see there’s now a view which performs the described transformation (rename id to customer_id):
jaffle_shop.duckdb> select table_name, table_type from information_schema.tables;
+---------------+------------+
| table_name | table_type |
+---------------+------------+
| raw_payments | BASE TABLE |
| raw_customers | BASE TABLE |
| raw_orders | BASE TABLE |
| stg_customers | VIEW |
+---------------+------------+
4 rows in set
jaffle_shop.duckdb> select definition from pg_views where viewname='stg_customers';
+-------------------------------------------------------------------------------------------------------------------------------------------------+
| definition |
+-------------------------------------------------------------------------------------------------------------------------------------------------+
| /* {"app": "dbt", "dbt_version": "1.1.1", "profile_name": "jaffle_shop", "target_name": "dev", "node_id": "model.jaffle_shop.stg_customers"} */ |
| create view "main"."stg_customers__dbt_tmp" as ( |
| with source as ( |
| select * from "main"."main"."raw_customers" |
| ), |
| renamed as ( |
| select |
| id as customer_id, |
| first_name, |
| last_name |
| from source |
| ) |
| select * from renamed |
| ); |
| ; |
+-------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set
Time: 0.012s
jaffle_shop.duckdb> select customer_id, first_name, last_name from stg_customers using sample 1;
+-------------+------------+-----------+
| customer_id | first_name | last_name |
+-------------+------------+-----------+
| 84 | Christina | R. |
+-------------+------------+-----------+
1 row in set
Time: 0.016sNow I’ll run the other two staging tables which will also create views. The stg_orders is the same as customers with just a change to the id field name. stg_payments also applies a transform to a currency field in the data:
select
[…]
-- `amount` is currently stored in cents, so we convert it to dollars
amount / 100 as amount
[…]Whereas before I used the name of the model, per the docs you can also specify a folder of models (--models staging).
--models is deprecated in favour of --select
|
dbt run --models staging
10:48:11 Running with dbt=1.1.1
10:48:11 Found 5 models, 20 tests, 0 snapshots, 0 analyses, 167 macros, 0 operations, 3 seed files, 0 sources, 0 exposures, 0 metrics
10:48:11
10:48:11 Concurrency: 1 threads (target='dev')
10:48:11
10:48:11 1 of 3 START view model main.stg_customers ..................................... [RUN]
10:48:11 1 of 3 OK created view model main.stg_customers ................................ [OK in 0.09s]
10:48:11 2 of 3 START view model main.stg_orders ........................................ [RUN]
10:48:11 2 of 3 OK created view model main.stg_orders ................................... [OK in 0.04s]
10:48:11 3 of 3 START view model main.stg_payments ...................................... [RUN]
10:48:11 3 of 3 OK created view model main.stg_payments ................................. [OK in 0.06s]
10:48:11
10:48:11 Finished running 3 view models in 0.30s.
10:48:11
10:48:11 Completed successfully
10:48:11
10:48:11 Done. PASS=3 WARN=0 ERROR=0 SKIP=0 TOTAL=3Now we’ve got three views in DuckDB representing the staging models over the raw seed data:
$ duckdb jaffle_shop.duckdb -c "select table_name, table_type from information_schema.tables;"
┌───────────────┬────────────┐
│ table_name │ table_type │
├───────────────┼────────────┤
│ raw_payments │ BASE TABLE │
│ raw_customers │ BASE TABLE │
│ raw_orders │ BASE TABLE │
│ stg_orders │ VIEW │
│ stg_customers │ VIEW │
│ stg_payments │ VIEW │
└───────────────┴────────────┘So that’s staging run. dbt creates views here because that’s the materialization config that’s specified in the dbt_project.yml:
[…]
models:
jaffle_shop:
materialized: table
staging:
materialized: viewLet’s now take a look at the main models that build tables from staging.
The Main Models: customers.sql 🔗
Looking at this model’s SQL you can see that calculates several aggregates by customer:
-
From order data (earliest & most recent order date, number of orders)
-
From payment data (total amount paid)
and builds a table of all customers with order and payment data where it exists (LEFT JOIN).
Let’s run it.
$ dbt run --select customers
13:39:39 Running with dbt=1.1.1
13:39:39 Found 5 models, 20 tests, 0 snapshots, 0 analyses, 167 macros, 0 operations, 3 seed files, 0 sources, 0 exposures, 0 metrics
13:39:39
13:39:39 Concurrency: 1 threads (target='dev')
13:39:39
13:39:39 1 of 1 START table model main.customers ........................................ [RUN]
13:39:39 1 of 1 OK created table model main.customers ................................... [OK in 0.10s]
13:39:39
13:39:39 Finished running 1 table model in 0.31s.
13:39:39
13:39:39 Completed successfully
13:39:39
13:39:39 Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1over in DuckDB we have a nice customers table populated for us:
jaffle_shop.duckdb> select table_name, table_type from information_schema.tables;
+---------------+------------+
| table_name | table_type |
+---------------+------------+
| raw_orders | BASE TABLE |
| raw_customers | BASE TABLE |
| raw_payments | BASE TABLE |
| customers | BASE TABLE |
| stg_payments | VIEW |
| stg_customers | VIEW |
| stg_orders | VIEW |
+---------------+------------+
7 rows in set
Time: 0.019s
jaffle_shop.duckdb> describe customers;
+-----+-------------------------+---------+---------+------------+-------+
| cid | name | type | notnull | dflt_value | pk |
+-----+-------------------------+---------+---------+------------+-------+
| 0 | customer_id | INTEGER | False | <null> | False |
| 1 | first_name | VARCHAR | False | <null> | False |
| 2 | last_name | VARCHAR | False | <null> | False |
| 3 | first_order | DATE | False | <null> | False |
| 4 | most_recent_order | DATE | False | <null> | False |
| 5 | number_of_orders | BIGINT | False | <null> | False |
| 6 | customer_lifetime_value | HUGEINT | False | <null> | False |
+-----+-------------------------+---------+---------+------------+-------+
Time: 0.008s
jaffle_shop.duckdb> select * from customers using sample 5;
+-------------+------------+-----------+-------------+-------------------+------------------+-------------------------+
| customer_id | first_name | last_name | first_order | most_recent_order | number_of_orders | customer_lifetime_value |
+-------------+------------+-----------+-------------+-------------------+------------------+-------------------------+
| 67 | Michael | H. | <null> | <null> | <null> | <null> |
| 35 | Sara | T. | 2018-02-21 | 2018-03-21 | 2 | 34 |
| 12 | Amy | D. | 2018-03-03 | 2018-03-03 | 1 | 4 |
| 52 | Laura | F. | 2018-03-23 | 2018-03-23 | 1 | 27 |
| 94 | Gregory | H. | 2018-01-04 | 2018-01-29 | 2 | 24 |
+-------------+------------+-----------+-------------+-------------------+------------------+-------------------------+
5 rows in set
Time: 0.012s
jaffle_shop.duckdb> select count(*) from customers;
+--------------+
| count_star() |
+--------------+
| 100 |
+--------------+
1 row in set
Time: 0.009s
jaffle_shop.duckdb>The Main Models: orders.sql 🔗
The orders.sql model is not quite as straight forward. Check out the first line of it
{% set payment_methods = ['credit_card', 'coupon', 'bank_transfer', 'gift_card'] %}What SQL-devil magic is this?!
Well it turns out that you can super-charge SQL by adding Jinja to it. Which when you hear it on a podcast sounds exactly like 'Ginger' and is really confusing.
The particular snippet above (payment_methods) is actually used in the doc page as an example. It explains that, as seen later in the model, the variable payment_methods can then be iterated over:
{% for payment_method in payment_methods %}
sum(case when payment_method = '{{payment_method}}' then amount end) as {{payment_method}}_amount,
{% endfor %}to generate the desired SQL:
sum(case when payment_method = 'bank_transfer' then amount end) as bank_transfer_amount,
sum(case when payment_method = 'credit_card' then amount end) as credit_card_amount,
sum(case when payment_method = 'gift_card' then amount end) as gift_card_amount,This is pretty smart. We could just write the SQL directly itself, but what happens when we start taking cheques and cryptocurrencies for payment? We either end up copy-and-pasting and search & replace on this line twice:
sum(case when payment_method = 'cheque' then amount end) as cheque_amount,
sum(case when payment_method = 'crypto' then amount end) as crypto_amount,which is fiddly and error prone. In addition if you look further down the model’s SQL you can see that the variable is used again:
{% for payment_method in payment_methods -%}
order_payments.{{ payment_method }}_amount,
{% endfor -%}So now your chances of making errors is even more so because you need to work out all the places in the SQL has appeared, and no way of telling which fields need replicating without knowing the code logic closely.
Alternatively, we just add them once to the nicely obvious and declared enum:
{% set payment_methods = ['cheque','crypto','credit_card', 'coupon', 'bank_transfer', 'gift_card'] %}Pretty smart huh.
This is where dbt compile comes into its own too. It was useful above to understand a bit more about the flow of things, but here it’s going to let us take the model and check how the Jinja will resolve into SQL:
$ dbt compile --select orders
15:13:58 Running with dbt=1.1.1
15:13:58 Found 5 models, 20 tests, 0 snapshots, 0 analyses, 167 macros, 0 operations, 3 seed files, 0 sources, 0 exposures, 0 metrics
15:13:58
15:13:58 Concurrency: 1 threads (target='dev')
15:13:58
15:13:58 Done.$ cat target/compiled/jaffle_shop/models/orders.sql
[…]
order_payments as (
select
order_id,
sum(case when payment_method = 'cheque' then amount else 0 end) as cheque_amount,
sum(case when payment_method = 'crypto' then amount else 0 end) as crypto_amount,
sum(case when payment_method = 'credit_card' then amount else 0 end) as credit_card_amount,
sum(case when payment_method = 'coupon' then amount else 0 end) as coupon_amount,
sum(case when payment_method = 'bank_transfer' then amount else 0 end) as bank_transfer_amount,
sum(case when payment_method = 'gift_card' then amount else 0 end) as gift_card_amount,
sum(amount) as total_amount
[…]
select
orders.order_id,
orders.customer_id,
orders.order_date,
orders.status,
order_payments.cheque_amount,
order_payments.crypto_amount,
order_payments.credit_card_amount,
order_payments.coupon_amount,
order_payments.bank_transfer_amount,
order_payments.gift_card_amount,
order_payments.total_amount as amount
[…]There’s a nice note in the docs about a dbtonic approach to the use of Jinja (this is nothing to do with Gin, but a nice nod to the pythonic concept) which is worth a read including strong advice to not be a smartarse favour readability over DRY-ness.
dbt run 🔗
Now that we’ve understood how all of this works, let’s run it all:
$ dbt run
15:51:46 Running with dbt=1.1.1
15:51:46 Found 5 models, 20 tests, 0 snapshots, 0 analyses, 167 macros, 0 operations, 3 seed files, 0 sources, 0 exposures, 0 metrics
15:51:46
15:51:46 Concurrency: 1 threads (target='dev')
15:51:46
15:51:46 1 of 5 START view model main.stg_customers ..................................... [RUN]
15:51:46 1 of 5 OK created view model main.stg_customers ................................ [OK in 0.11s]
15:51:46 2 of 5 START view model main.stg_orders ........................................ [RUN]
15:51:47 2 of 5 OK created view model main.stg_orders ................................... [OK in 0.06s]
15:51:47 3 of 5 START view model main.stg_payments ...................................... [RUN]
15:51:47 3 of 5 OK created view model main.stg_payments ................................. [OK in 0.07s]
15:51:47 4 of 5 START table model main.customers ........................................ [RUN]
15:51:47 4 of 5 OK created table model main.customers ................................... [OK in 0.09s]
15:51:47 5 of 5 START table model main.orders ........................................... [RUN]
15:51:47 5 of 5 OK created table model main.orders ...................................... [OK in 0.05s]
15:51:47
15:51:47 Finished running 3 view models, 2 table models in 0.54s.
15:51:47
15:51:47 Completed successfully
15:51:47
15:51:47 Done. PASS=5 WARN=0 ERROR=0 SKIP=0 TOTAL=5We end up with two final tables built and populated from this, customers and orders
$ duckdb jaffle_shop.duckdb -c "select table_name, table_type from information_schema.tables;"
┌───────────────┬────────────┐
│ table_name │ table_type │
├───────────────┼────────────┤
│ orders │ BASE TABLE │
│ customers │ BASE TABLE │
[…]
└───────────────┴────────────┘Wrapping up… 🔗
So that was fun. Slightly back-to-front, but fun nonetheless.
dbt gives us a nice way to use SQL to declare the transformations that we’d like to do on our data. It’s predicated on your data being in place already — it’s the T of the ELT/ETL process.
With dozens of adaptors you can use the same build platform but with different targets. I can see the appeal of this massively both as a way early in a project to evaluate different data stores side-by-side, as well as later on in a project as technology perhaps evolves to the point that you want to move your workload elsewhere.
Learning More 🔗
Data Engineering in 2022 🔗
-
Query & Transformation Engines [TODO]